Unleashing Success in the AI Era: Startups
Introduction
The AI sector has become even hotter over the past year, creating a more complex ecosystem for entrepreneurs and investors. Entrepreneurs are flocking to this sector, while early-stage investors are striving to identify startups with the potential to grow into significant companies.

Particularly, early-stage investors are looking to identify startups with strong advantages compared to their competitors and avoid investing in companies that could become irrelevant due to the actions of larger players. Some investors also express their reservations about startups built on top of existing large language models.
In this AI era, as AI-based startups seek to innovate and continuously grow, what should they consider?
Even in the paradigm shift to the AI era, companies are still trying to maximize customer and business value through AI technology. That’s an unchanging fact.
💡I share some personal reflections on what aspects to consider in order to successfully establish and sustain AI-based startups during this era.
The Areas
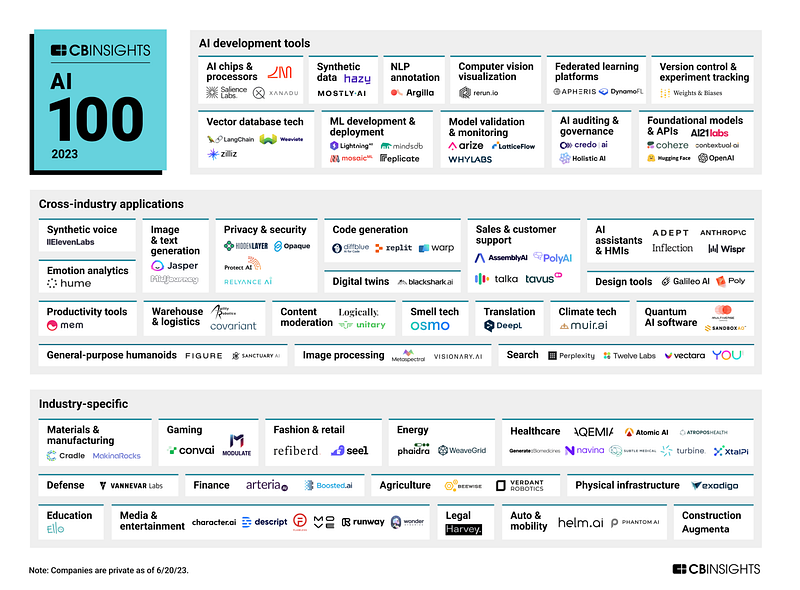
As you all know, existing AI companies can be broadly categorized into three main areas based on their services and target customers.
(1) Foundation LLM & Hub
Firstly, this area involves generating models based on large language models and providing them via APIs.
- Foundation models, APIs
Representative companies in this area include OpenAI, Google, Microsoft, Meta, HuggingFace, etc.
(2) AI Tools
Secondly, this area offers tools and platforms covering the entire AI process, from data processing and model creation to validation, development, and deployment.
- Chip & processor
- Data synthesis
- Prompt Engineering tool
- NLP annotation (labeling)
- Computer vision visualization
- Vector DB
- Development & deployment
- Model validation & monitoring
- Version management & experiment tracking
- AI auditing & governance
Representative companies in this area include Langchain, Mosaic ML, and others.
(3) End-User Applications
Companies in this category provide AI-based service applications, which can be divided into two subcategories.
One is offering AI solutions applicable to various industries, mainly as B2B services. They serve a diverse range of business customers in various industries.
(a) Cross-Industry
- Design generation tools
- Code generation
- Voice synthesis
- Sentiment analysis
- Search
- Image generation
- Text generation
- Assistants
- Media & Entertainment
Representative companies include Jasper, Midjourney, Perflexity, VisionaryAI, and others.
The second subcategory focuses on providing services specialized in a particular industry.
(b) Industry-Specific
- Gaming
- Manufacturing
- Fashion
- Healthcare
- Energy
- Automotive
- Education
Representative companies include CharacterAI, Descript, and Ello, and there are countless other services emerging every day.
The approach of AI Startups
Navin Chaddha, Senior Partner at Mayfield, an early-stage venture investment firm that backed Lyft, asks these four questions to many AI-based entrepreneurs [TechCrunch article source]
If you are preparing to start or already running an AI startup, these are questions worth asking yourself:
💡 How do you plan to dominate a layer of the AI technology stack that drives the AI paradigm shift in your company?
In the AI era, AI-native startups need to dream big to become independent companies that dominate a layer of the new technology stack, just like Nvidia in chip manufacturing, GitHub in the open-source AI model community (e.g., Hugging Face), or ChatGPT.
💡 Are you offering painkillers or vitamins?
While large language models and generative AI innovations create new markets and change market dynamics, it’s essential for entrepreneurs to identify the specific pain points they are addressing with their innovation and provide solutions that act as painkillers rather than just nice-to-have vitamins for certain people.
In other words, it’s crucial to focus on solving actual pain points or problems with AI rather than just providing something nice to have for a specific group of people.
💡 What is the unfair advantage that you can bring?
In other words, what competitive edge does your company possess beyond technology and product? Innovation can extend not only at the technology or product level but also across the entire value chain. Therefore, consider other moats that your company can create.
- Vertical foundational models
- Exclusive datasets
- Semiconductor architecture innovations
- Business models with various pricing options
- Market entry strategies such as open-source, product-led growth, leveraging network or data effects

💡 Are you automating or providing value?
Consider what value your AI-based service provides to people.
It’s not enough to say that your service automates something. You must clarify how your AI system empowers and enhances humans, acting as a valuable tool rather than just an automation mechanism.

🌟 Key Takeaway
As AI continues to cause disruptions, making definitive conclusions is difficult.
However, it’s evident that the more dependent a business model or service is on other giant LLM models, the more disadvantaged it will be in the AI ecosystem.
This applies not only from an AI ecosystem perspective but also as a best practice for sustainable business growth.
So, how should AI business models and services be developed?
To build AI-based services that solve customer problems and sustain a successful startup in the AI era, startups need to create and continuously refine proprietary models based on their own data. This means that AI-based startups should not solely rely on their services or business models but also secure datasets specific to their vertical and build specialized foundational models based on this data.
🏄♀️ Example
Let’s consider a startup that provides fashion recommendations for products and creators based on people’s fashion preferences and styles, ultimately offering a personalized commerce experience.
To provide value to customers through AI-based innovation, this startup should consider the following service scenarios alongside building competitive AI models based on its own dataset.

Browsing and Conversion-Based Style Recommendations:
- Model: Collaborative filtering and models that understand user-product interactions, such as Matrix Factorization or Deep Learning-based recommendation systems
- Data: User browsing history, conversion data, style information, purchase history
Interest Tag-Based Style Recommendations:
- Model: Text analysis models using Natural Language Processing (NLP) techniques, such as TF-IDF, Word2Vec, BERT, etc.
- Data: User-entered style tags and interest keywords, style/codi information, purchase history
Purchase History-Based Product Recommendations:
- Model: Collaborative filtering, Matrix Factorization, or Deep Learning-based recommendation models that understand user-product interactions
- Data: User purchase history, product information, purchase behavior data
Product Image-Based Similar Product Recommendations:
- Model: Convolutional Neural Network (CNN) models for image analysis, such as ResNet, VGG
- Data: Product image data, product information, and feature vector data for similarity measurement
Style Image-Based Similar Style Recommendations:
- Model: CNN models for image analysis
- Data: Style image data, Style information, and feature vector data for similarity measurement
Automatic Tagging of Style Images — Product Names/Brands:
- Model: Fusion of image analysis and NLP techniques, such as Vision-Language Pretraining (VLP) models
- Data: Style image data, product names, and brand information
Rather than developing all these models from scratch, it’s more practical to use existing open-source models and continuously fine-tune them with proprietary data through iterative steps:
- Create hypotheses based on the company’s business objectives.
- Develop prototype models for each hypothesis.
- Test the models in actual production.
- Select the model that demonstrates the best customer experience or business value.
Continuously iterate 1 to 4 to optimize the process and the model’s performance.
Building Proprietary Models
Building your machine learning models using your own data can be a rewarding and educational experience.
Here are some general steps to consider when building your machine-learning model with your data:
Problem Definition
Clearly describe the problem you want to solve with machine learning. It can range from image classification to text generation, depending on your data and interests.
Data Collection
Gather or generate a dataset related to the problem. The dataset should be diverse, representative, and large enough to train a powerful model.
Data Preprocessing
Clean the data, format it, and convert it into a suitable format for machine learning algorithms. This step may involve tasks like duplicate removal, handling missing values, and data normalization.
Data Splitting
Divide the dataset into 2–3 parts (typically training, validation, and test sets). The training set is used to train the model, the validation set is used to adjust hyperparameters, and the test set is used to evaluate the final model’s performance.
Model Architecture Selection
Choose the most suitable machine learning algorithm or model architecture for the problem. The choice of model depends on whether the data is structured (e.g., tabular data) or unstructured (e.g., images or text).
Model Training
Use the training data to train the model to fit the problem. The model learns from the data and adjusts its internal parameters to make accurate predictions.
Hyperparameter Tuning
Machine learning models have hyperparameters that can impact performance. Experiment with different values for these hyperparameters using the validation set to find the best combination.
Model Evaluation
After training and tuning the model, evaluate its performance on the test set to estimate how well it generalizes to unseen data.
Fine-Tuning and Iteration
Based on the evaluation results, fine-tune the model or collect more data to achieve better performance. Model Deployment: If the model performs well, deploy it in real applications to make predictions on new data.
Successful machine learning model building can involve iterative processes and may require some trial and error.
Additionally, learning various algorithms, model architectures, and data preprocessing techniques is essential to creating effective machine-learning solutions.
Moreover, when working with your own data or deploying machine learning models in real scenarios, consider ethical issues and data privacy.
TL: DR and Final Thought
As we navigate the AI era, startups in the AI domain must stay innovative and forward-thinking to thrive in this ever-evolving landscape. To build successful AI-based startups, entrepreneurs should ponder the following key questions:
- Dominating a Layer of the AI Technology Stack: Dream big and aim to establish independent companies that dominate a specific layer of the AI technology stack. This could be analogous to Nvidia in chip manufacturing, GitHub in the open-source AI model community, or ChatGPT in language generation.
- Offering Painkillers, not Vitamins: Focus on solving real pain points and providing tangible solutions to customers. Ensure that your AI-based innovation acts as a painkiller, addressing critical needs, rather than merely providing optional “vitamins” to a niche market.
- Leveraging Unfair Advantages: Identify your unique competitive edge beyond just technology or product. Consider vertical foundational models, exclusive datasets, innovative business models, or market entry strategies that set your startup apart from the competition.
- Automating while Providing Value: Strive to create AI services that empower and enhance human experiences. It’s not enough to automate processes; your AI should bring true value to users, making it an invaluable tool in their lives.
To achieve sustainable growth, AI-based startups should prioritize building proprietary models based on their own data. This entails continuously refining and fine-tuning existing open-source models with specific datasets, addressing their vertical’s unique challenges.
Building AI models with proprietary data can be a rewarding journey, starting from problem definition to model deployment. Embrace an iterative approach, learning from data, experimenting with different architectures, and continuously improving your models.
By embracing these principles and staying committed to constant improvement, AI startups can carve their path to success in this exciting and transformative AI landscape.
Here, I’ve outlined the direction for startups aiming to create sustainable businesses using AI technology in this AI era. I consider it a work in progress and a topic that I’d like to keep pondering. So, if you could leave your valuable feedback in the comments, it would be of great help to me as I continue to explore this subject further.