
Understanding Tokens and Overcoming their Limitations in LLMs

Token limits are one of the most discussed limitations of LLMs that I have observed in any conversation that happens around LLMs. This is because it is directly related to how much information can the LLM absorb to answer a specific question. The more information you give(more specifics) the better your response will be. Before diving deep into ways to overcome this token limit, let's first talk about the limitations of LLMs very briefly. Large Language Models have 2 types of limitations,
- Conceptual Limitations: These can be thought of as soft limitations. Some examples of these limitations are domain knowledge, languages known, data cutoff, etc. These limitations, given more data or resources, or both are possible to overcome in an ideal situation.
- Technological Limitation: These are more like hard limitations. Some examples are input or output token limits, memory limits, and trainable parameters. These limitations cannot be overcome without making changes to the architecture of the LLMs. However, you can never fully eliminate them. Meaning, that if your current LLM has an input token limit of 1k tokens, you can build a larger LLM that overcomes the 1k limit but then it may have a limit of 8k for 36k or even 100k, my point is that the limit will always exist.
Most of the end-users generally face the technological limitation of token limits. If you already know what tokens are then you can skip the below section, or keep reading.
Tokens
They can be thought of as a string of contiguous characters. This string can be approximately (not always) 4 characters long. These tokens may or may not be a complete word.

As you can see in the above image, some of the basic words(irrespective of their size) are grouped as single tokens but, when it comes to complex words, they are broken down down into multiple tokens(like photosynthesis and metamorphosis). There is no universal set rule to perform this breaking of words. It differs from model to model and it is generally done based on the frequency of a set of characters in the training data.
Why do token limits exist?
To understand this, we will have to get our hands a little bit dirty on the technical side. So, Large Language Models(LLMs) as their name suggests are trained using an enormous corpus of text. The LLM training is performed using this text by giving a subset of this text as input and other subsets as expected output(true label). These subsets can either be 2 halves of a sentence or some missing words in a sentence. In either situation, we need to give the LLM a fixed-size input and a fixed-size output. Keeping these input and output sizes fixed, helps the LLM to understand the given sequence of words and their combined meaning in association with the expected output. Also, practically it wouldn’t be possible to give an input of a streaming nature(infinitely ongoing) to the LLM for training as it will not be able to consume it completely at all. The input layer in the below image can be thought of as the fixed-size input being fed to the neural network.

Let me try to explain this using a simple analogy. Imagine that you are given the task of answering a question from the given passage. Now imagine that this passage is streaming, meaning it just keeps on going. Hence the problem arises, you will never finish reading the passage and will never reach the question OR you might have read the question first and then started reading the passage but again, you will never reach the end of the passage and will never be confident that if the answer you have is correct or is there a better answer ahead.
These token limits exist in all the LLMs or in fact, I can say that they exist in every supervised machine learning model. Be it computer vision, NLP, or simple classification models, all of them have an input size(dimension) that they accept for training and during inference time. For inputs that are smaller than the token limit of the model, we can do padding to increase and match the expected input dimensions but, what do we do when the input is larger than the expected token limit? Let's look at some techniques that can be applied to overcome this limitation.
Basic Techniques
1. Truncation
This is the easiest and least effective method of handling token limits. The input is stripped off of the extra tokens that are present. This can be done from either side (start or end) to make the input token length acceptable. It does not even solve the issue but rather modifies the input to make it consumable for the model. There is no guarantee that the model will generate a good response as it does not understand the entire user query. Risk: Critical information might get stripped off
2. Sampling
Sampling can be thought of as a modification of truncation to overcome its limitation of missing information beyond the token limit. In sampling, we remove some filler(non-critical) words from the input to make it shorter but still maintain the context of the query. You can see in the below example, that in each query I am making the input smaller and smaller by removing the non-critical words but the output remains the same.
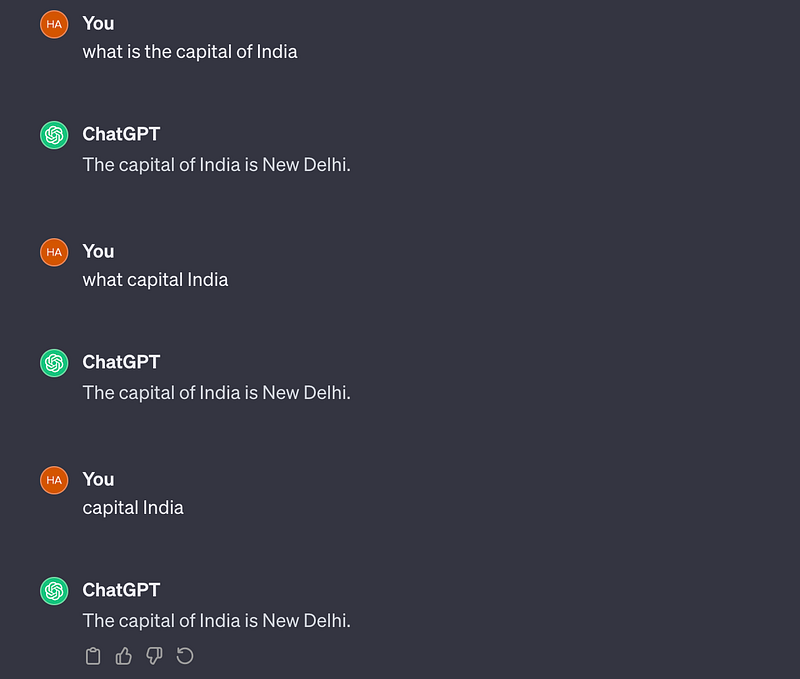
Risk: Critical words might be removed changing the meaning of the sentence.
3. Chunking
Chunking is the process of breaking the user query into smaller parts and sending them individually to the LLM. In this way, we do cover the entire query but it is in a disjoint fashion and the LLM loses the context. This might be useful if there are different contextual parts in the query that can be answered independently. Risk: If the entire query belongs to the same context then this technique might not get good results.
4. Encoding
Encoding your input can be helpful to alter the length of your query without losing the majority of information and still keeping the context. You can use compression methods like Huffman coding, Run Length Encoding, etc. to encode your string to a shorter length. LLMs will be able to understand these encoded formats as for them, it is just like a language that has a different set of rules than English as you can see in the below image where I send a base64 encoded message
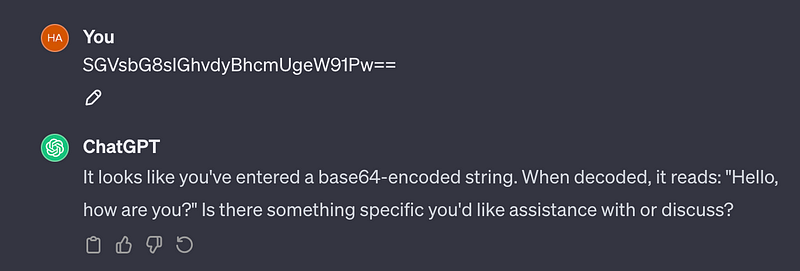
Risk: Sometimes encoding might result in a longer string than the actual version. It is important to choose the encoding algorithm carefully
5. Summarisation
In this method, you can summarise the query into a shorter version and then send it to the LLM. This can be thought of as a lossy compression where we are trying to keep the general idea of the context but some specifics are lost.
6. Stop Word Removal
This is a specialized version of the sampling technique you saw earlier. The only difference is that here, we define a specific list of grammatical words(eg is, a, an the, of, etc.) that are removed from the query. This reduces the size of the query. The LLM is smart enough to understand the context of the query without these stop words. You can consider the same example image given for the sampling technique.
Advanced Techniques
7. Refining
Refining is an iterative approach. We first divide the larger query into smaller chunks. We send the first chunk to get a response. Now, we send the second chunk and ask the LLM to refine its response with this new information. We keep repeating this process for all the remaining chunks and at the end we will have a response that has been refined with all the information in mind. You can find the example in the below transcript:
8. RAG Pipeline(Retrieval-Augmented Generation)
In RAG pipelines we break our knowledge base into small chunks of information which are represented as embeddings. The user query is also represented as embeddings and then we find the chunk that is closest(or top k closest) to it using vector similarity. Then, these chunk(s) are sent as context to the LLM to answer the user query. This is generally used for infobot use cases. A simple representation of the RAG is shown below:

Risk: It is important to perform the chunking and vectorization operations with attention or else, it might affect the performance.
9. Fine Tuning your LLM
In this technique, we need to alter the training process of our LLM. This is one of the most complex type of technique that you can implement to handle token limits. We want to train our LLM in such a way that it is able to fill in missing words in the user query. For example:
User query: This user input broken down multiple tokens It include complex words photosynthesis metamorphosis LLM Interpretation: This is a user input that will be broken down into multiple tokens. It may include some complex words like photosynthesis or metamorphosis Risk: The LLM might make a different interpretation every time as it is not deterministic
Conclusion
We can thus see that multiple techniques are available to overcome the token limitation of the LLMs. Each of these techniques has its advantages and disadvantages and it depends on the use case that you are trying to solve. It also depends on your team’s current priority as the advanced techniques might need more time and effort compared to the basic ones but they sure have their benefits.
10 years back if somebody had told me that something like an LLM would exist, then I may not have believed it at all but today, here I am writing blogs on it. Who knows in the future, we might even have LLMs that do not have these token limitations at all.




