
Understanding Token Limits in OpenAI’s GPT Models

The token generation capacity in OpenAI’s GPT models varies based on the model’s context window(length) as illustrated in the previous post. For instance, the gpt-3.5-turbo offers a context window of 4,096 tokens, while the gpt-4-1106-preview extends up to 128,000 tokens, capable of processing an entire book's content in a single chat interaction.
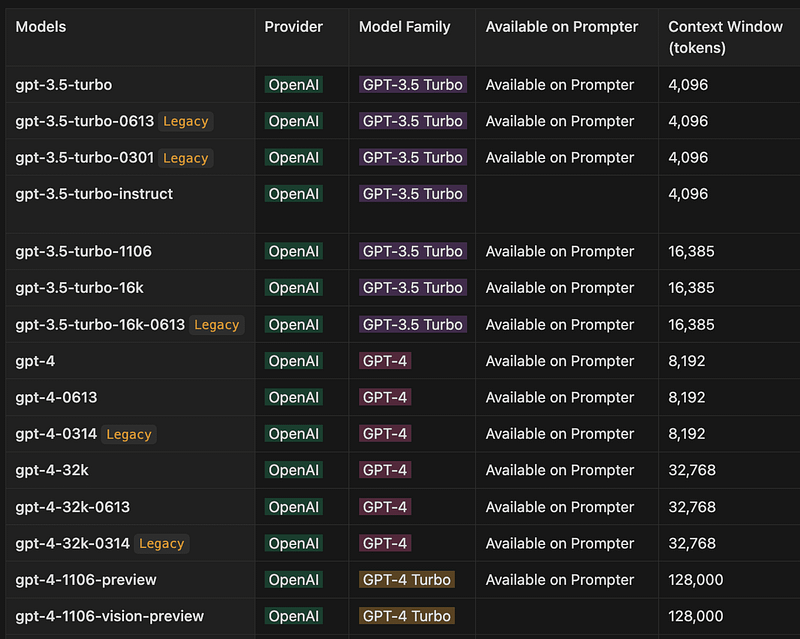
The model’s context window, which is shared between the prompt and completion, determines the maximum tokens allowed in a chat request. For gpt-3.5-turbo, this limit is 4,096 tokens.
Depending on the model used, requests can use up to 4097 tokens shared between prompt and completion. If your prompt is 4000 tokens, your completion can be 97 tokens at most.(Source: OpenAI Help Center)
The max_tokens parameter in the chat completion endpoint raises questions about its functioning. It represents the maximum number of tokens the model can return in completion.
The maximum number of tokens that can be generated in the chat completion.(Source: OpenAI Documentation)
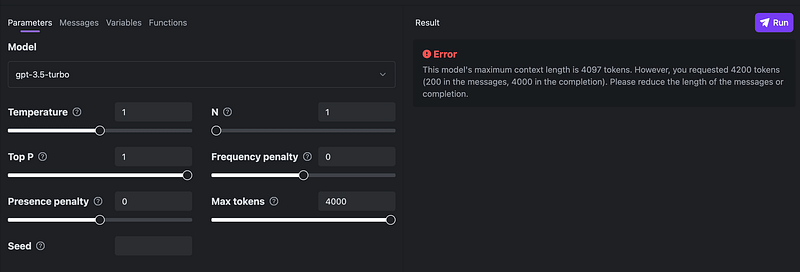
You may encounter such error if the max_tokens + the token number of prompt exceeds the models’ maximum context length.
This model’s maximum context length is 4097 tokens. However, you requested 4200 tokens (200 in the messages, 4000 in the completion). Please reduce the length of the messages or completion.
The completion content may be partially cut off if finish_reason="length", which indicates the generation exceeded max_tokens or the conversation exceeded the max context length.
To optimize token consumption and save costs in GPT wrapper products, please consider:
- Adjusting the number of historical chat contexts carried, balancing between memory and context window limits.
- Clearly indicating the current user input token count and setting maximum input token limits.
- Tailoring the
max_tokensvalue in requests based on the prompt length and model's context window to avoid errors. - Utilizing tools like Prompter for fine-tuning and optimizing prompts, minimizing token counts without compromising completion quality.
Summary
Understanding the token generation and limits in OpenAI’s GPT models is pivotal for developers and users alike. By grasping the nuances of context window sizes and managing max_tokens wisely, one can enhance the efficiency of GPT-based applications. This knowledge not only improves user experience but also aids in cost-effective management of AI resources.
Original Link:https://prompter.engineer/blog/understanding-token-limits-in-openai-s-gpt-models





