
Understanding the Differences Between AutoEncoder (AE) and Variational AutoEncoder (VAE)
Are you familiar with the nuances between AutoEncoder (AE) and Variational AutoEncoder (VAE)?
Yes, they exhibit fundamental differences!
While both are neural network-based techniques used for data compression and feature extraction, they operate differently, particularly concerning the latent space, a multidimensional space where data is compressed. The main distinction between AE and VAE lies in the regularization of the latent space, which has profound implications for data generation capabilities.
AutoEncoder (AE):
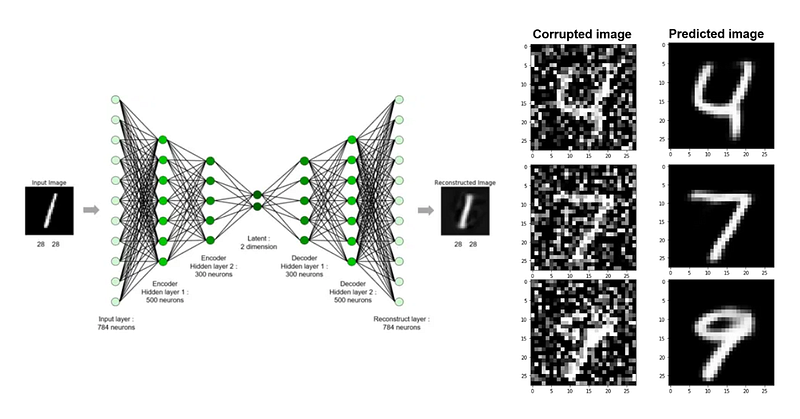
AE consists of two main parts: the encoder, which maps the input X to a latent space Z, and the decoder, which maps Z back to a reconstruction X^. The typical cost function for AE is the mean of the quadratic reconstruction, also known as the Mean Squared Error (MSE), between the original input and the reconstructed output.
Error formula:
LAE=N1∑i=1N∥∥Xi−Xi∥∥2
AE excels at learning compact data representations, but the latent space is not regularized, meaning it lacks specific constraints on the distribution of points in space Z. Consequently, while proficient in compression and reconstruction, AE cannot effectively generate new data.
Variational AutoEncoder (VAE):
In contrast, VAE introduces regularization into the latent space. It assumes that points in the latent space Z should follow a standard multivariate Gaussian distribution (N(0,1)). VAE reformulates the optimization problem to maximize the marginal likelihood P(X) while simultaneously minimizing the Kullback-Leibler (KL) divergence between the approximate distribution Q(Z∣X) and the standard distribution.
Cost function formula for VAE:
LVAE=−EQ(Z∣X)[logP(X∣Z)]+DKL(Q(Z∣X)∣∣P(Z))

The first part of the cost function aims to maximize the reconstruction probability, while the second part penalizes significant deviations from the Gaussian pattern.
Typical Use Cases:
- Anomaly Detection and Fraud Analysis: Both AE and VAE can be employed for detecting anomalous patterns in complex data.
- Data Generation: VAE, owing to its generative capacity, is used in tasks such as image, music, and text generation, where creating new data is essential.
- Dimensionality Reduction: Both methods are valuable for reducing the dimensionality of complex data while preserving essential features.
I hope this provides a deeper understanding of the differences between AE and VAE and their applications!