
Understanding the Bias-Variance Tradeoff in Machine Learning: Examples and Solutions
Introduction
Machine learning models play a pivotal role in various applications, from predicting customer behavior to diagnosing diseases. However, building an effective model is not a straightforward task. One of the central challenges in machine learning is striking the right balance between bias and variance. In this comprehensive guide, we will explore the bias-variance tradeoff in detail, provide examples to illustrate these concepts, and offer practical solutions to address bias and variance issues.
Bias and Variance: Definitions and Implications
Before we dive into the tradeoff, let’s establish a solid understanding of bias and variance:
Bias (Underfitting)
Bias refers to the error due to overly simplistic assumptions in the learning algorithm. A model with high bias tends to underfit the data, meaning it oversimplifies the underlying patterns. This leads to poor predictive performance as the model cannot capture the complexity of the real-world problem.
Example of High Bias:
Suppose you are training a linear regression model to predict housing prices. If the model assumes that the relationship between the features (e.g., square footage, number of bedrooms) and the price is strictly linear, it may perform poorly when the true relationship is more complex.
Variance (Overfitting)
Variance, on the other hand, is the error due to excessive complexity in the learning algorithm. A model with high variance captures not only the underlying patterns but also the noise in the training data. This leads to poor generalization to unseen data.
Example of High Variance:
Imagine training a decision tree with a very deep structure on a dataset of handwritten digits. While the tree can fit the training data perfectly, it might perform poorly on new, unseen digits because it has essentially memorized the training examples, including their individual quirks.
Identifying Underfitting and Overfitting
Now that we understand bias and variance, let’s discuss how to recognize whether a model is underfitting or overfitting.
Underfitting
Underfitting occurs when a model is too simplistic to capture the underlying patterns in the data. You can identify underfitting by analyzing the model’s performance on both the training and test datasets:
- Training Set: A model with high bias will struggle to fit the training data, resulting in low training accuracy (e.g., 60%).
- Test Set: The same model will also perform poorly on the test set, leading to low test accuracy (e.g., 65%).
In summary, underfitting results in a model that fails to grasp even the fundamental relationships in the data.
Overfitting
Overfitting happens when a model is excessively complex, capturing not just the patterns but also the noise in the training data. Identifying overfitting is a bit more nuanced:
- Training Set: A model with high variance can fit the training data exceedingly well, achieving high training accuracy (e.g., 95%).
- Test Set: However, this model will perform significantly worse on the test set, exhibiting lower test accuracy (e.g., 75%).
In essence, an overfit model “memorizes” the training data but struggles to generalize to new, unseen data.
The Tradeoff: Balancing Bias and Variance
The bias-variance tradeoff is the delicate equilibrium between underfitting and overfitting. The goal is to find the optimal level of complexity that allows a model to generalize effectively to unseen data. This tradeoff is often visualized as a curve, known as the validation error curve:
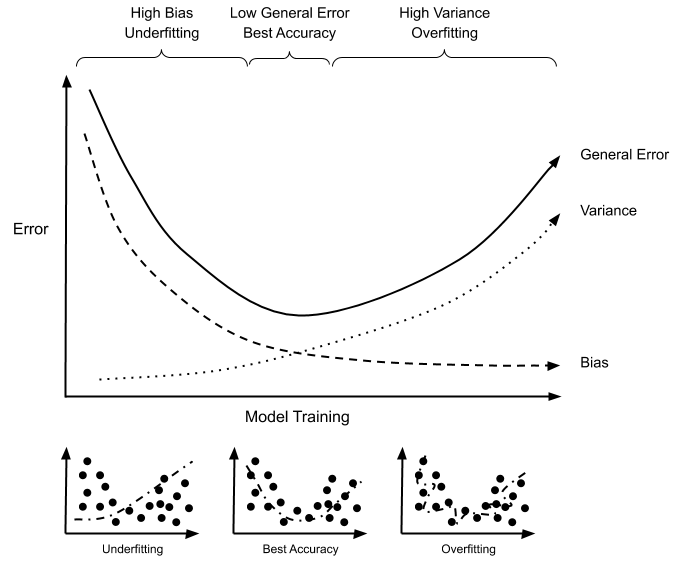
Validation Error Curve:
The validation error curve is a graphical representation that illustrates the relationship between model complexity (or flexibility) and the error on a validation dataset. It typically looks like an inverted U-shape or a curve with two distinct components:
- Bias (Underfitting) Region: On the left side of the curve, you have the region associated with high bias or underfitting. In this area, the model’s complexity is too low to capture the underlying patterns in the data. As a result, both the training and validation errors are high.
- Variance (Overfitting) Region: On the right side of the curve, you enter the region associated with high variance or overfitting. Here, the model’s complexity is excessively high, and it starts fitting not only the underlying patterns but also the noise in the training data. In this region, the training error is very low, but the validation error starts to increase significantly because the model fails to generalize to unseen data.
- Optimal Region (Tradeoff): The point of optimal model complexity lies between the bias and variance regions, often referred to as the “sweet spot.” This is where the model generalizes well to both the training and validation data, resulting in the lowest validation error.
Solutions to Address Bias and Variance
To strike the right balance and address bias and variance issues, consider the following solutions:
- Regularization: Regularization techniques like L1 (Lasso) and L2 (Ridge) can help mitigate overfitting. These methods add penalty terms to the model’s cost function, discouraging it from becoming overly complex.
- Feature Engineering: Thoughtful feature selection and engineering can reduce both bias and variance. By including relevant features and excluding noisy ones, you can improve model performance.
- Cross-Validation: Utilize cross-validation to assess your model’s performance on different subsets of the data. This helps you gauge how well your model generalizes across various data splits, providing valuable insights into bias and variance.
- Ensemble Methods: Ensemble techniques such as Random Forests and Gradient Boosting combine multiple models to achieve better performance. They can effectively reduce overfitting while improving predictive accuracy.
- Collect More Data: If your model suffers from high bias (underfitting), acquiring more data can help it capture more complex patterns. Additional data can be especially beneficial when dealing with deep neural networks.
Conclusion
In the realm of machine learning, the bias-variance tradeoff is a fundamental concept that can significantly impact the success of your models. Striking the right balance between bias and variance is an art that requires careful consideration and experimentation. By identifying whether your model is underfitting or overfitting and applying appropriate solutions, you can optimize your model’s performance and build robust machine learning systems. Remember, the tradeoff is about finding that sweet spot where your model is just right, making it a valuable tool for real-world applications.





