Understanding LSTM, GRU, and RNN Architectures
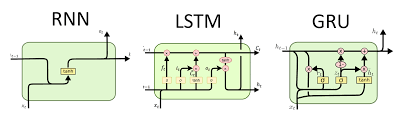
In the ever-evolving landscape of artificial intelligence and machine learning, the demand for processing long sequences of data has become increasingly prevalent. As we navigate through this complex realm, three pivotal recurrent neural network (RNN) architectures have emerged to tackle this challenge: Long Short-Term Memory (LSTM), Gated Recurrent Unit (GRU), and the traditional RNN. In this article, we delve deep into the architecture of each, shedding light on their inner workings and highlighting the limitations of the conventional RNN when it comes to processing extended sequences.
Recurrent Neural Networks (RNN)
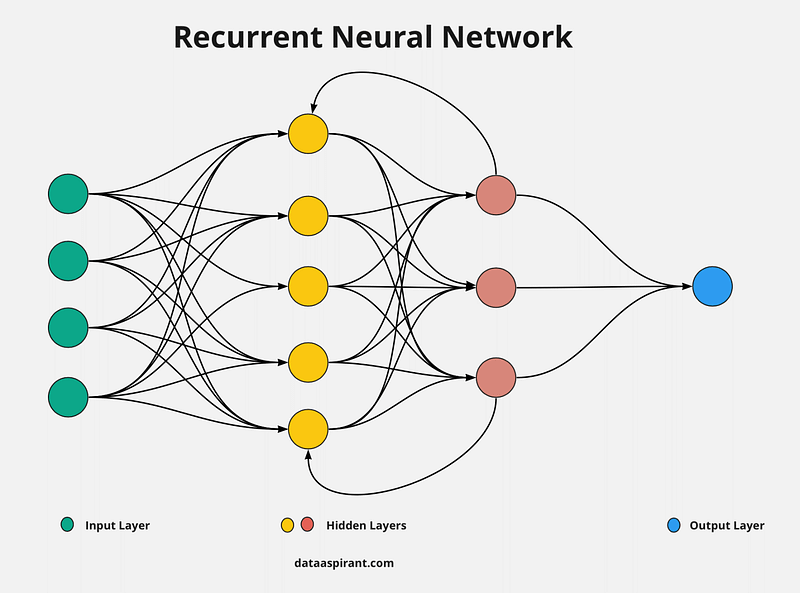
To embark on our journey, let’s first explore the conventional RNN. RNNs are a class of artificial neural networks designed for sequential data processing. Their architecture comprises a series of hidden states that evolve as the network processes each element of the sequence. This dynamic nature allows RNNs to maintain a form of memory and take into account past information when making predictions. However, the standard RNNs exhibit certain limitations when dealing with long sequences.
The Challenge with RNNs
The Achilles’ heel of traditional RNNs lies in their inability to capture long-range dependencies effectively. When processing extensive sequences, they often suffer from a phenomenon known as the “vanishing gradient problem.” This means that the gradients used to update the network’s parameters during training become extremely small as information traverses through numerous time steps. Consequently, the network struggles to learn from distant past data, severely limiting its ability to make accurate predictions or classifications.
Long Short-Term Memory (LSTM)
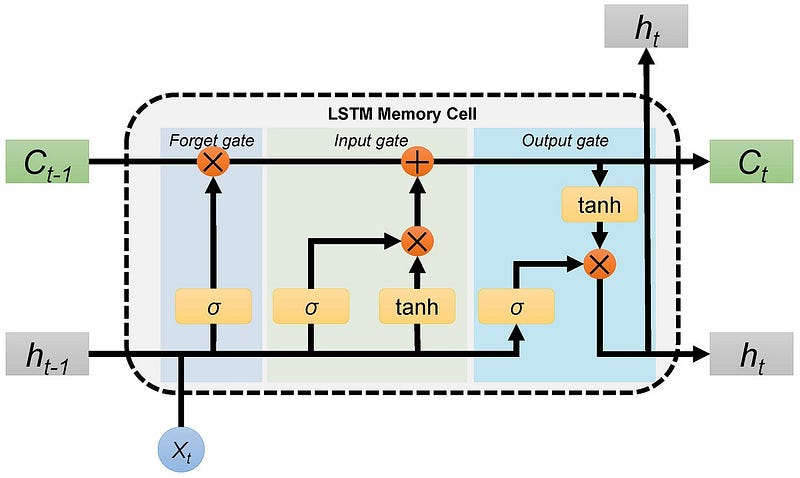
In response to the limitations of RNNs, the LSTM architecture was developed. LSTM networks are a type of RNN that address the vanishing gradient problem by introducing a more sophisticated memory mechanism.
LSTM Architecture
LSTM networks have a unique structure, which includes three fundamental gates:
- Forget Gate: This gate determines what information from the previous cell state should be forgotten or retained.
- Input Gate: It controls what new information should be stored in the cell state.
- Output Gate: This gate defines the output of the LSTM cell, considering the current input and the updated cell state.
This intricate gating mechanism enables LSTM networks to preserve information over long sequences, making them exceptionally well-suited for various tasks, such as natural language processing and time series analysis.
Applications of LSTM
LSTM networks have found wide-ranging applications in the field of machine learning and AI. Here are some notable use cases:
ApplicationDescriptionNatural Language Processing (NLP)LSTM is widely used for text generation, sentiment analysis, and machine translation.Speech RecognitionLSTM helps convert spoken language into written text, making it essential for voice assistants and transcription services.Time Series PredictionIt’s effective in predicting stock prices, weather patterns, and various financial trends.Music CompositionLSTM networks can compose music based on existing compositions and styles.
Gated Recurrent Unit (GRU)
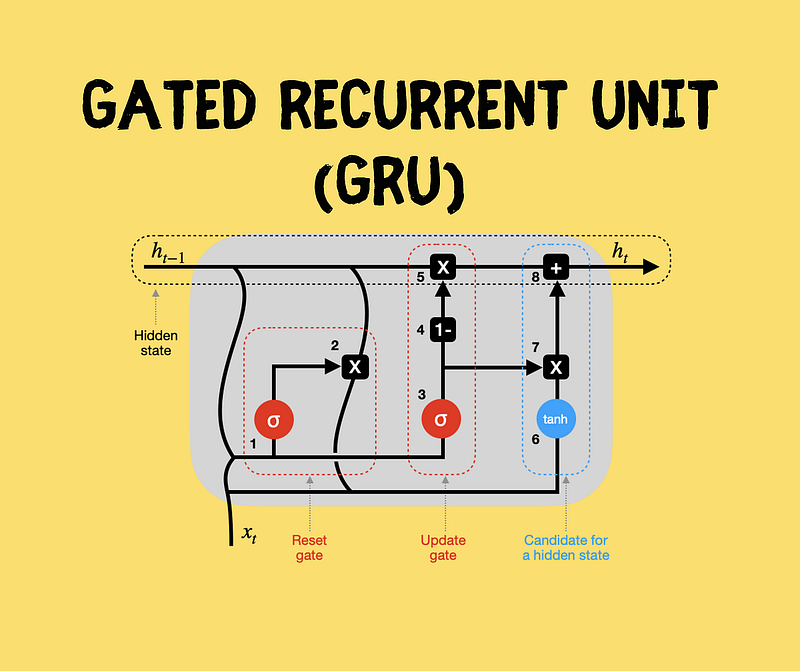
Another breakthrough in the realm of sequence processing is the Gated Recurrent Unit (GRU). Like LSTM, GRU is designed to address the vanishing gradient problem while being computationally more efficient.
GRU Architecture
The GRU architecture also incorporates gating mechanisms, although it is somewhat simplified compared to LSTM:
- Update Gate: This gate controls what information from the previous hidden state should be retained.
- Reset Gate: It determines what information should be discarded from the previous hidden state.
GRUs maintain a balance between the capacity to capture long-range dependencies and computational efficiency, making them an attractive option in various applications where LSTM might be overkill.
Applications of GRU
GRU networks, due to their efficiency, are gaining popularity in a variety of fields:
ApplicationDescriptionLanguage ModelingGRU is utilized in autocompletion and text generation applications.Video AnalysisIt’s used for tasks like action recognition and object tracking in videos.Handwriting RecognitionGRU can convert handwritten text into machine-readable text, a crucial feature in digitization.Fraud DetectionGRU networks help identify patterns of fraudulent activities in financial transactions.
Combining the Power of LSTM and GRU
In some cases, combining the strengths of LSTM and GRU can yield exceptional results. This hybrid approach leverages the long-term dependency capturing ability of LSTM and the computational efficiency of GRU. Researchers and practitioners often experiment with different network architectures to find the optimal solution for their specific tasks.
Conclusion
In conclusion, understanding LSTM, GRU, and RNN architectures is crucial for anyone venturing into the world of sequence processing in the domain of artificial intelligence. While RNNs lay the foundation, LSTM and GRU have arisen as powerful solutions to address the limitations of traditional RNNs. The former’s complex gating mechanism allows for superior long-range dependency capture, while the latter simplifies the process while retaining efficiency.
These neural network architectures have revolutionized fields such as natural language processing, speech recognition, and even music composition. The choice between LSTM, GRU, or RNN depends on the specific task and the trade-off between model complexity and computational efficiency.
For those looking to delve deeper into these architectures and their applications, further exploration and experimentation are key to harnessing the full potential of these remarkable tools in the world of artificial intelligence.
Remember, when it comes to handling long sequences and making intelligent predictions, it’s not just about knowing the terminology — it’s about understanding the inner workings and selecting the right tool for the job.


