

Understanding Latent Dirichlet Allocation (LDA) — A Data Scientist’s Guide (Part 2)
LDA Convergence Explained with a Dog Pedigree Model
“What if my a priori understanding of dog breed group distribution is inaccurate? Is my LDA model doomed?”
My wife asked.
Welcome back to part 2 of the series, where I share my journey of explaining LDA to my wife. In the previous blog post, we discussed how LDA works and how it can be understood as a dog pedigree model.
This time around, let's dive into the iterative fitting process of LDA!
Part 1 (link):
- How does LDA work?
- How to explain LDA to a non-technical person?
Part 2 (We are here now!):
- How does LDA improve iteratively?
- How does LDA converge?
- Bonus: Get your LDA cheatsheet here!
Part 3:
- When to use LDA & when not to?
- How can we use it in Python?
- What are the alternatives & variants to LDAs (excluding LLMs)?
Let’s get started.
If you have not read part 1 of the series, I strongly encourage you to read it first, as we will build on that understanding.
Quick Recap from Part 1

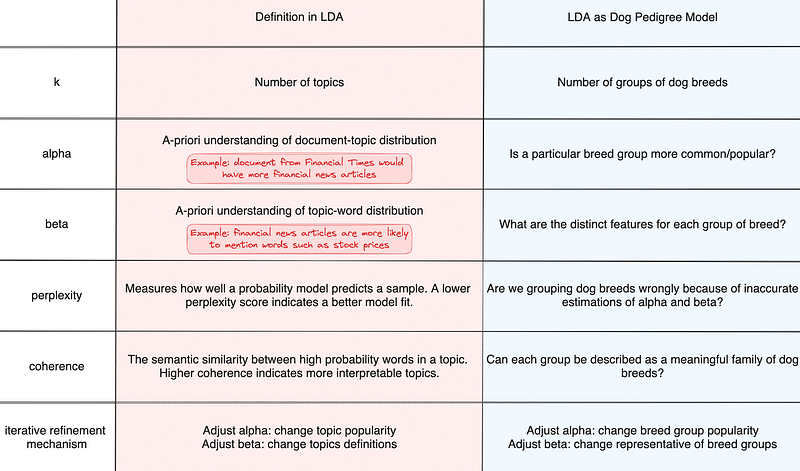
Our dog pedigree model in Part 1 aims not to classify pedigrees of dogs but to model groups of pedigrees. For each group of pedigrees, we have picked a breed as the symbol/representative. Based on these representatives, we have defined the following alpha and beta.


Confidently confused — Model perplexity

{kind=link}
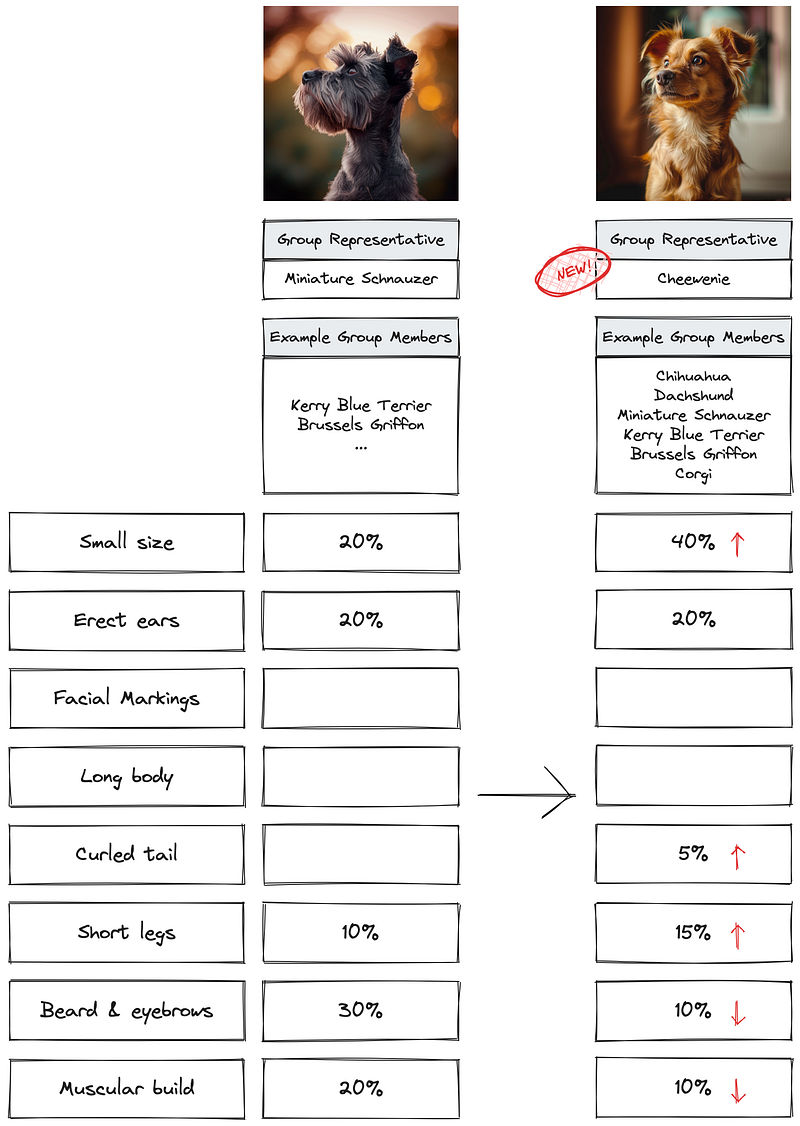
In the pile of dog images is a Cheewenie similar to the above. Look for its features:
- Erect ears
- Beard & eyebrows
- Small size
Before consulting our model, we imagine it to be more similar to Chihuahua and Dachshund than the others.

If we look at our beta table, the model is confident that a Cheewenie with a small size, erect ears, beard & eyebrows is similar to a Miniature Schnauzer & Chihuahua mix. Dachshund is only the distant fourth, only marginally ahead of Huskey!
Bottom line: if a dog is a mix of two breeds, our model should be able to group it as more similar to the parent breeds than other breeds!
Why can’t our model group a Cheewenie under Chihuahua and Dachshund?
- The way we group breeds is not reflecting the reality — Miniature Schnauzer, Chihuahua and Miniature Dachshund might be too similar for us to consider them as separate breed groups if we are only dividing breed groups into 5!
- Our definition of indicative physical traits for each breed group is inaccurate — Yes, Miniature Schnauzers might have erect ears, but is it as indicative as being small-sized?
- We might have mistaken the popularity of each breed group — If we encounter even more Cheewenies, have we got it wrong that Miniature Schnauzer might actually have less than 10% breed popularity?
Crucial re-iteration: we are trying to model the pedigrees into groups of similar breeds instead of classifying them. We have picked the 5 breeds as breed group representative for illustration purposes. For example, Miniature Schnauzer is a representative of a group of breeds that may include Kerry Blue Terrier, Brussels Griffons and other similar breeds.
All three reasons from the above would confuse our model when grouping photos into different breed groups. To address that, we can adjust our model in two ways:
- Redefine the group of breeds (Adjust Beta): If the model sees too much overlapping between groups, it signals that they are indeed one group of breeds. May be we can group them (Chihuahua, Miniature Schnauzer, and Miniature Dachshund) together to form a new group and free up two group of breed for representing more distinct breed groups.
- Adjust group popularity (Adjust Alpha): Alongside adjusting the groups, our model would also update the group popularity to align with the popularity of the observed groups of pedigrees.


In LDA, a perplexity score measures the alpha & beta induced over-confidence illustrated above. The lower the perplexity score, the better the model is. Take the news article headline of Local Farmer's stock of rare chickens sees price surge due to popularity. If the combination of stock, price, and surge has leaned LDA’s prediction to a financial topic, we call the model perplexed/confused. The model might update its alpha to lean heavier toward agricultural news articles while adjusting beta to update the relative importance of vocabulary collocation for the financial topic.
Meaningful Groups — Topic Coherence

Would it make more sense to group a Pomeranian with Shiba Inu & Spitz dogs or a group of breeds represented by a Cheewenie?
Realistically, a Pomeranian is a small sized dog with erect ears, curled tails, and muscular build. Based on the beta matrix, it should be tight between the Shiba Inu group and the Cheewenie group, leaning closer to the latter.
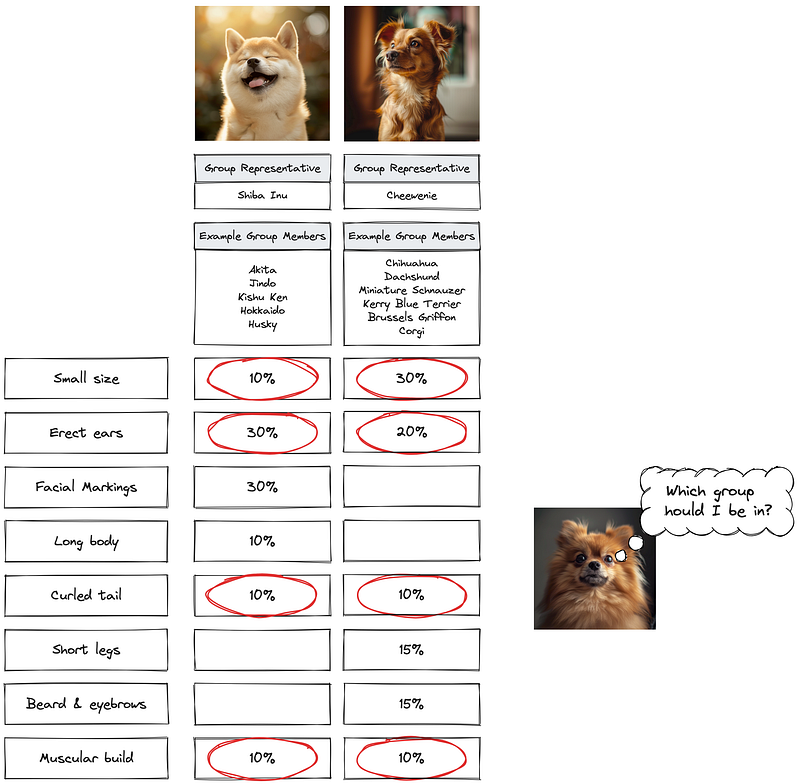
Ultimately, models are created to provide interpretable & meaningful insights. If you have to explain to your boss how the breeds are grouped, which would be more straightforward?
- A group of Spitz family dog breeds, and another group of smaller breeds represented by a Chihuahua & Miniature Dachshund mix; Or
- A group of Spitz family dog breeds excluding Pomeranians, and another group of smaller breeds represented by a Chihuahua & Miniature Dachshund mix and Pomeranians
Surely, the first one is more succinct!
To create a more meaningful Spitz group, we can again adjust alpha and beta to ensure that Pomeranians lean closer to the Shiba Inu group than the Cheewenie group.
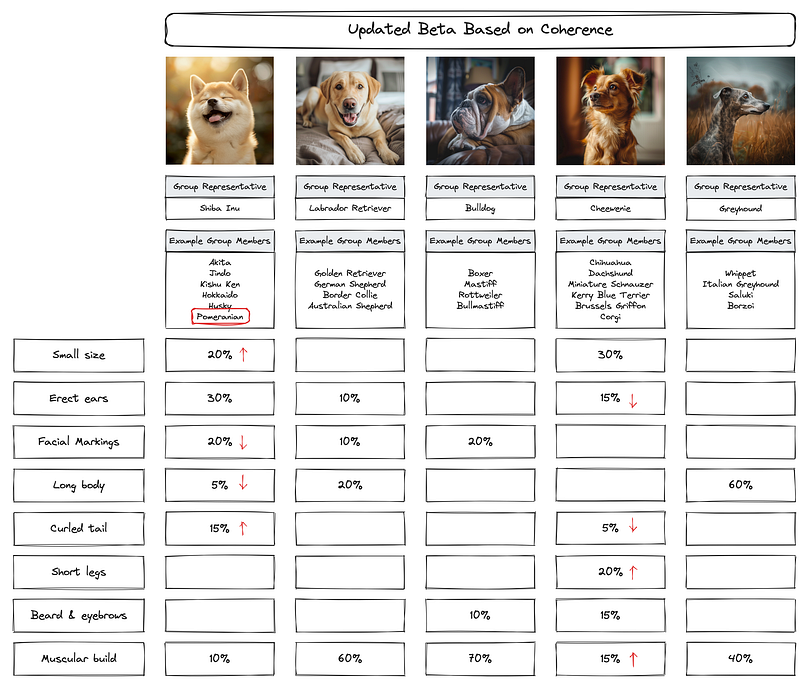
In LDA, this concept is called topic coherence. If a topic is not coherent enough, it signals multiple smaller topics. The measure of dispersion within a topic gives us a hint of how well-defined a topic is from a statistical point of view. Similar to adjusting the model based on the perplexity score, LDA will adjust alpha and beta accordingly to refine topic popularity & topic definition.
Iterative Improvement
We have just finished one iteration of the dog pedigree model review and adjusted alpha and beta to ensure a more meaningful group and reduce cases where models are confused. But we don’t need to stop there; we can start the next iteration and adjust the model until it stabilises. By stabilising, we can either say, “Let’s iterate 5 times”, or we can also say, “Let’s iterate until the photo group membership does not change more than 5 percentage points”.

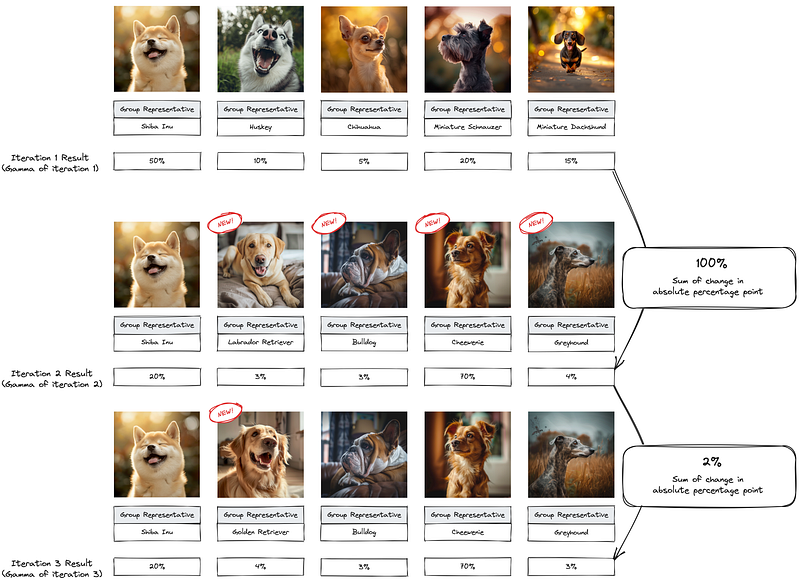
An early stopping rule or gamma threshold typically controls iterative improvements when fitting an LDA model. The early stopping rule will stop LDA fitting after a specified number of iterations. The gamma threshold is a quantified way of measuring the change in gamma, i.e. the document-topic distribution. Usually, gamma stabilises as the LDA model converges/stabilises. Once it stabilises, there will only be a marginal benefit for further iterating and refining. The formula for updating gamma depends on the iteration mechanism, e.g. Gibbs Sampling/Variational Bayesian Inference.
Starting Conditions
If the model got updated based on the perplexity and coherence of the groups of breeds, we need to start somewhere first to generate the initial perplexity and coherence measures. An easy way could be randomly guessing each picture's breed group mix or following the alpha.
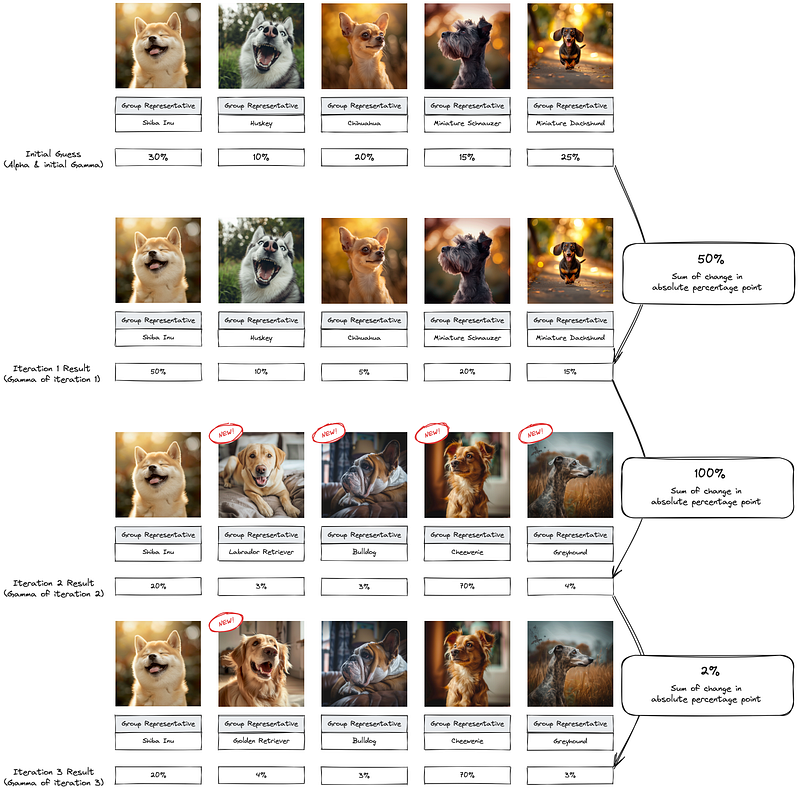
The initial state/initial gamma will be set in LDA according to the alpha. It can either be a random guess, evenly distributed, or exactly alpha. The value of this initial gamma is expected to drift as the model fits the training data iteratively using the process outline in the previous section.
Piecing everything together — What is LDA?
Here’s your LDA cheatsheet!
- LDA is a Bayesian clustering algorithm for identifying underlying groups of topics across a set of documents.
- Each document can be represented and interpreted as a mix of groups of discussion topics, each with a probabilistic weighting (e.g. 70% financial, 30% banter).
- Each document is considered a bag of words; each contributes a different semantic meaning to the document.
- A word is a document with exactly 1 word, so each word can be interpreted as a mix of discussion topics similar to how documents can.
- LDA aims to model topic distribution across documents and word distribution of topics.
- LDA identifies groups of topics but cannot assign a label to the topics (e.g. LDA can link the two collocations of “stock” & “price” and “price” & “surge” to the same topic but cannot label them as “financial”).
- LDA improves iteratively by reducing model perplexity and enhancing topic coherence.
- The definition of topics and the topic distribution across documents might change as the LDA model improves iteratively. (i.e. topics defined in the first iteration could be different to the final set of topics)
- LDA’s iterative update process can be controlled using an early stopping rule to cap the fitting process at a certain number of iterations or with a
gammathreshold for detecting model convergence. - An LDA model converges when changes in
gammadrop below a certain threshold. gammais the topic distribution for each document. Change ingammasignals changes how the LDA model creates groups of topics.- LDA typically uses Gibbs sampling and variational Bayesian inference for iterative improvement.
corpusis the universe of the document-word matrix that LDA needs to analyse. It should be in the shape of (number of documents, number of unique words)kis another required hyperparameter that determines the number of topics to be modelled.alphais an optional hyperparameter for providing an A priori understanding of document-topic distribution. This initial seed can be a scalar (topics are assumed to be evenly distributed) or a vector of lengthk(each element representing the overall weighting of each topic)betais an optional hyperparameter for providing an A priori understanding of topic-word distribution. This initial seed can be a scalar (naive assumption of even distribution of words for each topic), a vector of length of the number of unique words for specifying each word’s relative importance across all topics, or a matrix of the shape of (number of documents, number of unique words) where each element represents the relative importance of each word to each topic
Quick Recap So Far
In the second part of the LDA series, we have extended our Dog Pedigree Model to illustrate how LDA iteratively update its internal state to better model the underlying topics. Combining both parts, you should now be able to explain what LDA is trying to achieve and how LDA converge to a non-technical individual!
In our final part of the series, we will dissect LDA for its pros and cons and highlight some alternatives. Stay tuned!
So back to my wife’s question:
“What if my a priori understanding of dog breed group distribution is inaccurate? Is my LDA model doomed?”
No, while having a decent a priori understanding helps guide LDA to fit better quicker, an inaccurate a priori understanding might not be the end of the world! As illustrated in this blog post, internal states of LDA will update iteratively to best model the underlying data.
Think of a decent a priori understanding as a gentle push on the right direction, giving the model the tail wind it needs to learn and converge faster.
A quick plug for myself!
If you have read this far, you are interested in the theories behind different data science techniques. Check out some of my other blogs where I dissected other algorithms!
If you have found this blog post helpful, subscribe to my mailing list or support my work using claps! If I have missed/mistaken anything critical, please comment or DM me through LinkedIn. Let’s keep the knowledge flowing!