
Understanding Large Language Model (LLM) Benchmarks
Often times when new LLM models/versions are launched we see benchmarks comparison in their website that compares their model with other prominent LLM models available in the market like the comparison below.
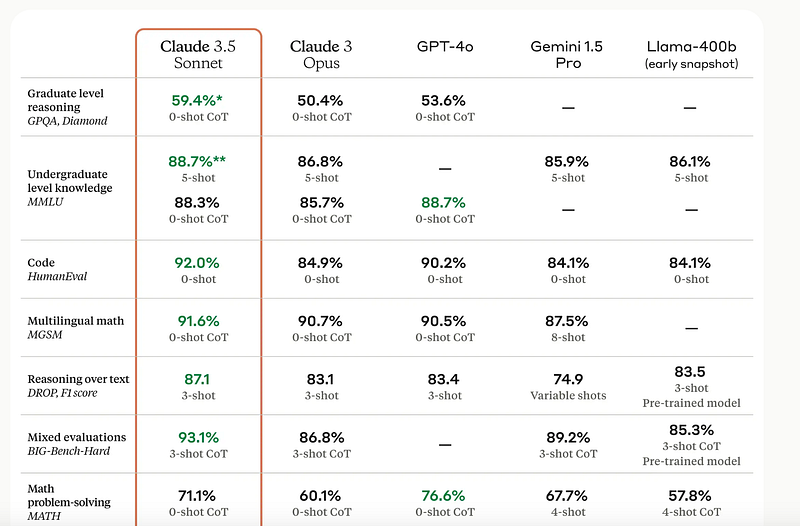
In this post, I would like to give an idea of what are LLM benchmarks? Why they are important? What happens in the benchmarking process? and What are the performance metrics and evaluation criteria tracked for the benchmarks?
Large Language Model (LLM) benchmarks are essential tools for evaluating and comparing the performance of different language models. They provide a standardized set of tasks that allow us to measure how well these models understand and generate language. Here’s a breakdown of what LLM benchmarks typically include and why they are so important.
What Are LLM Benchmarks?
LLM benchmarks are designed to test the capabilities of language models in a consistent and objective way. They usually consist of:
- A Dataset of Test Examples: This is a collection of text samples that the models will be tested on.
- Specific Tasks or Questions: These are the challenges or prompts that the models need to respond to.
- Metrics for Scoring Model Outputs: These are the criteria used to evaluate how well the models perform.
- Leaderboards: These rank the models based on their performance on the benchmark tasks.
For example, in a question-answering benchmark, models might be given a series of factual questions. Their performance is then measured by how many questions they answer correctly, and they are ranked based on their accuracy scores. Another example is a summarization benchmark, which tests how well models can condense longer articles into concise summaries, often using metrics like ROUGE to score their performance.
Why Are LLM Benchmarks Important?
LLM benchmarks play a crucial role in the development and application of language models for several reasons:
- Comparing Models: They allow us to objectively compare different models to determine which one is best suited for a specific use case.
- Tracking Progress: By using benchmarks, we can monitor improvements over time and identify areas where models still need enhancement.
- Accountability: Benchmarks hold models accountable to their performance claims and help uncover any limitations.
- Standardized Evaluation: They enable consistent and fair evaluations, making it easier to determine which models are truly state-of-the-art.
Without benchmarks, it would be challenging to sift through marketing claims and truly understand which models deliver the most accurate, reliable, and beneficial outputs. Rigorous benchmarking ensures that models continue to improve and meet the high standards expected of them.
The Benchmarking Process
Task Definition
The first step in benchmarking an LLM is to define the tasks that will test the model’s abilities. These tasks might include:
Question-Answering: Testing how well the model can respond to factual questions. Language Understanding: Assessing the model’s ability to comprehend text. Reasoning: Evaluating logical thinking and inference skills. Language Generation: Measuring the quality of text the model can produce.
The tasks should be challenging yet solvable, pushing the model to its limits while remaining within the realm of possibility.
Data Preparation
Next, a high-quality test dataset is curated. This dataset must be:
Representative: Reflecting the diversity of real-world language use. Unbiased: Free from prejudices that could skew results. Unseen by Models: Ensuring that models haven’t been trained on this specific data before.
Data can come from real-world sources or be designed to be particularly challenging:
Prompt Design
Prompts are crafted to query the model and elicit the desired responses. These instructions need to be standardized to ensure a fair comparison between different models.
Model Evaluation
The model is then run on the test examples, and its performance is measured using relevant metrics. Evaluation can be automated or involve human judgment to assess the quality of the model’s responses.
Results Analysis
Finally, the scores are analyzed to identify the models’ strengths, weaknesses, and differences. This analysis provides insights that can help improve both the models and the benchmarks themselves.
Benchmarks may test models in a “zero-shot” manner, where no additional training is provided, or in a “few-shot” setting, where a small set of examples is given. During testing, models are typically restricted from accessing external information.
Performance Metrics and Evaluation Criteria
LLM benchmarks use a variety of metrics to evaluate performance, including the list in the table below:
| Metric | Description |
|------------------|-------------------------------------------------------|
| Accuracy | % of responses exactly matching expected answer |
| F1 Score | Harmonic mean of precision and recall |
| BLEU | Similarity between generated and reference text |
| Perplexity | How surprised model is by test data, lower is better |
| Exact Match | Binary score if entire output matches expected |
| ROUGE | Measures overlap of generated and reference summaries |
| Human Evaluation | Qualitative judgment of outputs by raters |
To get a comprehensive view of a model’s capabilities, benchmarks often employ multiple complementary metrics. Evaluation criteria may also consider factors like:
Truthfulness: Providing factual and reliable information. Coherence: Staying on topic and making logical sense. Fluency: Using natural and grammatical language. Relevance: Directly addressing the prompt. Reasoning: Exhibiting logical thinking and inference. Robustness: Performing well on adversarial or out-of-distribution examples.
Closing thoughts
Benchmarking LLMs is a critical process that ensures models are reliable, effective, and continuously improving. By defining tasks, preparing data, designing prompts, evaluating models, and analyzing results, we can push the boundaries of what these models can achieve and ensure they provide valuable, accurate outputs. This rigorous evaluation helps us cut through the hype and understand which models are truly leading the way in natural language processing.
In summary, LLM benchmarks are vital for advancing the field of natural language processing, ensuring that language models are constantly evolving and providing valuable outputs. They offer a clear, objective way to measure and compare model performance, driving innovation and improvement in this exciting area of technology.
References:
https://beginswithai.com/llm-large-language-model-benchmarks/




