
Understanding Focal Loss for Pixel-level Classification in Convolutional Neural Networks
A smooth version of cross entropy loss for quick convergence

As I wrote in the last article of this series, focal loss is a more focused cross entropy loss. In semantic segmentation problems, focal loss can help the model focus on pixels that have not been well trained yet, which is more effective and purposeful than cross entropy loss. I recommend the article if you haven ‘t read it yet.
Again in this article, I ‘d like to talk about a variant of focal loss that can be used as a distance-aware cross entropy loss in semantic segmentation problems, especially with sparse labels.
The issue of standard cross entropy loss
Cross entropy loss is typically used in semantic segmentation, in which each pixel of the image is labeled with a category number, and a model is trained to predict that number for each pixel.
This per-pixel prediction fashion is widely used in almost all academic papers about semantic segmentation. However, there exists an issue, which may cause bad influence on convergence and is seldomly discussed. The sparser the labels are, the more significant the issue will be.
Let ‘s take a binary classification scenario as an example. Extension to multi-class classification is straightforward. Look at the following Figure 1, in which a blue pixel is labeled with 1, and all other pixels are labeled with 0. This labeled image is extremely sparse and foreground-background imbalanced because only one pixel is labeled as foreground class.

Now, imaging Figure 1 is input to our model, and we get an output image in which the label of every pixel is predicted. As conceptually shown in Figure 2, among all the resulting pixels, we take two of them for discussion. The two pixels are colored in green, and the labeled blue pixel is also preserved here for ease of explanation.
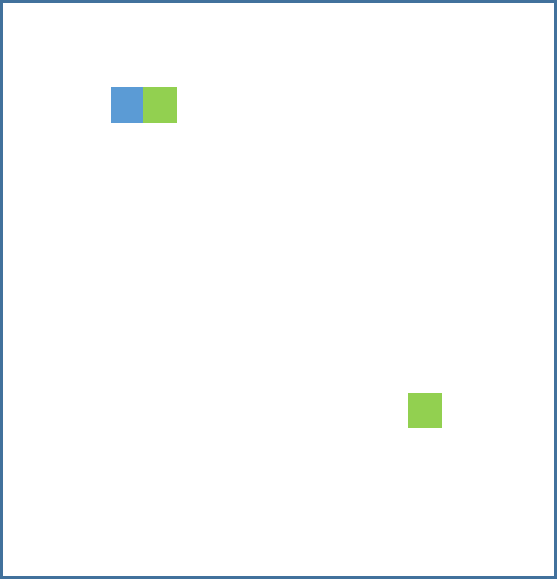
Suppose the two green pixels are predicted with the same probability 0.9, which means that the probabilities of their labels to be 1 is 0.9, and the probabilities of their labels to be 0 is 0.1. As their real labels are 0, the two green pixels will be punished heavily during this round of training because the probability for the real label is merely 0.1, which is too small.
Even though their distances to the foreground blue pixel are totally different, the two green pixels will be punished equally if standard binary cross entropy loss is adopted. This is not problematic if both the labels are distributed evenly. However, since the foreground-background labels are highly imbalanced in this example, we hope that the model can be trained to focus on and converge the prediction results to the foreground pixel. More specifically, background pixels within a small radius of the foreground pixel are allowed to be predicted to 1, with the allowance extent varying in a monotonic fashion according to their distances to the foreground pixel. However, this cannot be implemented with standard cross entropy loss, in which each pixel is trained individually, independently from other pixels. This is just the issue of standard cross entropy loss when used in tasks with sparse labels.
A distance-aware cross entropy loss
Since the issues with standard cross entropy loss discussed above, tasks with highly imbalanced labels such as facial point detection [Sun 2013], human pose detection [Newell 2016] etc. adopted mean square error (MSE) loss for training. The label images are shown in Figure 3.

MSE works by minimizing the difference between real and predicted key-point positions in a pixel level regression framework. The MSE loss function is shown in Figure 4.
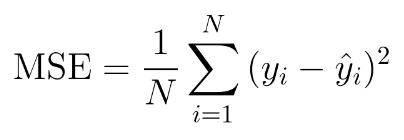
The issue of this approach is that the predictions only contain the positions of pixels, while their semantic information is lost. If someone wants to use the predicted key points for some post process, she has to work out a pattern to deal with the intrinsic relationship among the points in advance, which might be complicated.
Therefore, in such tasks with highly imbalanced labels, can we train a model to learn the positions of foreground labels effectively while preserving their semantic information?
As discussed above, the answer is Yes! We can modify the standard cross entropy loss in two steps to get such a new loss function. Firstly, modify it to a focal loss [Lin 2017]. Secondly, modify the focal loss to be aware of distance to foreground labels. I call it distance-aware cross entropy loss [Law 2018].
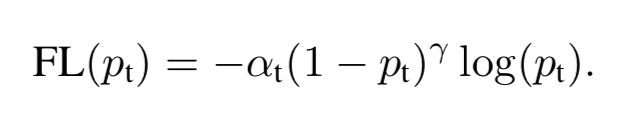
In the first step, standard cross entropy loss is modified to focal loss as shown in Figure 5. In the equation, pt is a measurement of prediction accuracy. The higher the pt is, the more accurate the prediction is. Since pt is between 0 and 1, the factor 1-pt can be used to decrease the standard cross entropy loss if the accuracy is already good enough, thus making the model focus on areas that have not been well trained yet. I recommend reading my last post for more details.
In the second step, as discussed above, background pixels within a small radius of the foreground pixel are allowed to be predicted to 1, with the allowance extent varying in a monotonic fashion according to their distances to the foreground pixel. Therefore, for the background pixels with label 0, a distance factor is added to decrease their loss values according to their distances to the nearest foreground pixel with label 1.
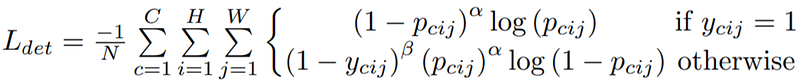
In order to get that loss function, we split the focal loss into two equations according to different label values (0 and 1). Then a distance factor ycij is added as shown in Figure 6. Here, the distance factor ycij is a Gaussian function centered on a foreground label position in the 2D image space as shown in Figure 7. The function value at the center is 1 and decreases monotonically as getting far from center. Thus, the focal loss doesn ‘t change for foreground pixels (upper equation in Figure 6). For background pixels, under the influence of the factor 1-ycij, the focal loss decreases largely as getting close to foreground pixels, while keeps almost unchanged as getting far from them (lower equation in Figure 6).
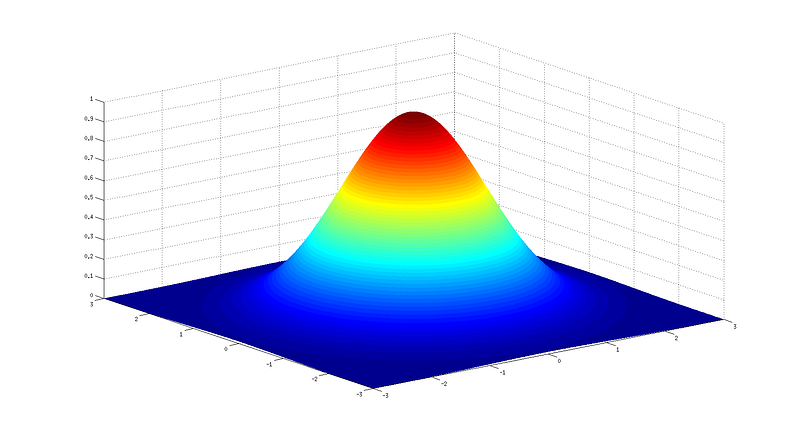
As a consequence, with the help from the distance factor, focal loss can be modified to focus on and converge the prediction results to the foreground pixels for tasks with highly imbalanced foreground-background labels. Focal loss refines the traditional pixel-wise discrete cross entropy loss to a continuous smooth loss as shown in Fig. 7, which is faster to converge.
References
Deep Convolutional Network Cascade for Facial Point Detection, Sun et al., CVPR 2013
Stacked Hourglass Networks for Human Pose Estimation, Newell et al., ECCV 2016
Focal Loss for Dense Object Detection, Lin et al., ICCV 2017
CornerNet: Detecting Objects as Paired Keypoints, Law et al., ECCV 2018



