Understanding Categorical Encoding Techniques: Ordinal, One-Hot, and Label Encoding

Introduction: Categorical variables are an essential part of data analysis, but they cannot be directly processed by machine learning models. To address this, we use various encoding techniques to convert categorical data into numerical form. In this blog post, we will explore three popular encoding methods: Ordinal Encoding, One-Hot Encoding, and Label Encoding.
What is Categorical Data?
Categorical data refers to a type of data that represents specific categories or groups. It is a type of data that is non-numerical and consists of labels or qualitative values rather than numerical values. Categorical data is often represented by text or symbols and can be divided into different distinct groups or categories. In machine learning, categorical data is typically represented using the “object” or “string” data type.
Here are a few examples of categorical data:
Gender: Categorical variable with categories such as “Male” and “Female.”
Marital Status: Categorical variable with categories such as “Married” and “Single.”
Education Level: Categorical variable with categories such as “High School,” “Bachelor’s Degree,” “Master’s Degree,” etc.
Occupation: Categorical variable with categories such as “Teacher,” “Engineer,” “Doctor,” etc.
In machine learning, there are two main types of categorical data:
Nominal Categorical Data: Nominal variables represent categories without any specific order or ranking between them. The categories are simply distinct groups. Examples of nominal categorical data include gender (e.g., “Male” and “Female”), country of origin (e.g., “USA,” “UK,” “Germany”), or product categories (e.g., “Electronics,” “Clothing,” “Books”). Nominal variables are often represented using one-hot encoding.
Ordinal Categorical Data: Ordinal variables represent categories that have a natural order or ranking between them. The categories can be ranked based on some criteria or scale. Examples of ordinal categorical data include education level (e.g., “High School,” “Bachelor’s Degree,” “Master’s Degree”), customer satisfaction rating (e.g., “Very Satisfied,” “Satisfied,” “Neutral,” “Dissatisfied,” “Very Dissatisfied”), or economic status (e.g., “Low Income,” “Middle Income,” “High Income”).
I am using Student dataset which can be found in my GitHub.


In the above dataset, observe that StageID, ParentsschoolSatisfaction, Class belongs to ordinal category whereas gender,Topic and Relation belongs to nominal category.
Ordinal Encoding:
Ordinal encoding assigns each unique value to a different integer.

This approach assumes an ordering of the categories: “ lowerlevel” (0) < “ MiddleSchool” (1) < “ HighSchool” (2).

Note: When performing encoding If we dont specify a mapping or order(Refer to categories in above line), the encoder will assign random integers to represent the distinct values. As a result, the encoded data may not follow any particular order or logic. For example good might be given as 0 and bad as 1 but we want the the ranking from low to high.
Now we will fit and transform to the OrdinalEncoder object to encode our StageId and ParentsschoolSatisfaction columns.

I created two new columns just to differentiate the columns and their data before and after encoding.

We can further drop the StageID and ParentsschoolSatisfaction column as we have already converted this into numeric data.

Label Encoder:
LabelEncoder should be used to encode the target variable (y) rather than the input features (X). Here’s an example code snippet that demonstrates how to use LabelEncoder to encode the target variable
Create an object of Label Encoder and apply fit_transform on the target variable.


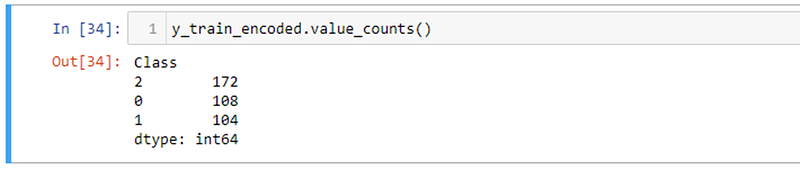
We can see from the above, the data in the ‘Class’ column is converted to numeric data.
Similarly, applied le_transform to the testing data.

One-Hot Encoding:
One-Hot Encoding is a technique used to transform categorical variables into a binary representation, where each category is converted into a binary column. It creates new columns for each unique category and assigns a value of 1 or 0 to indicate the presence or absence of that category in a particular row.
Here’s an example code snippet that demonstrates how to perform one-hot encoding using both pandas and scikit-learn libraries in Python


We can observe that one column is created for each category in gender(2 categories), Topic(12 categories), and Relation(2 categories). Hence the dataframe shape is now changed to 480 rows and 23 columns
The above code can create Dummy variable trap which is a situation that occurs when we include a dummy variable for each category of a categorical variable, resulting in multicollinearity. Multicollinearity is a phenomenon in which two or more independent variables are highly correlated, leading to instability in the model and difficulty in interpreting the coefficients.
To solve the multicollinearity issue, one of the dummy variables needs to be dropped. This is typically done by excluding one of the encoded columns from each categorical feature, creating one less column than the total number of categories.

The ‘drop_first’ parameter avoids the dummy variable trap by dropping the first encoded column for each categorical feature. Now we can see the shape of the dataframe is (480,20) which mean one category from each column is dropped.

Using Sklearn OneHotEncoding:

Applying OneHotEncoding to Nominal Category columns to both training and testing data.

Converting the One hot Encoded data back to Dataframe.

Dropping the original columns gender, Topic and Relation from training and testing data and combining the OneHotEncoded columns with the X_train and X_test dataframe.



Conclusion:
In this blog post, we explored three common categorical encoding techniques: Ordinal Encoding, One-Hot Encoding, and Label Encoding. We used the Student dataset to demonstrate the implementation of each technique in Python.
To summarize their use cases:
Ordinal Encoding is suitable when categorical variables have an inherent order or ranking.
One-Hot Encoding is useful when the categories have no natural order
Label Encoding is appropriate when encoding target variables, especially for categorical variables with no inherent order.




