
Technical
Understanding And Implementing Dropout In TensorFlow And Keras
Dropout is a common regularization technique that is leveraged within state-of-the-art solutions to computer vision tasks such as pose estimation, object detection or semantic segmentation.

Introduction
This article covers the concept of the dropout technique, a technique that is leveraged in deep neural networks such as recurrent neural networks and convolutional neural network.
The Dropout technique involves the omission of neurons that act as feature detectors from the neural network during each training step. The exclusion of each neuron is determined randomly.
G.E Hinton proposed this simple technique in 2012 in the published paper: “Improving neural networks by preventing co-adaptation of feature detectors”.
In this article, we will uncover the concept of dropout in-depth and look at how this technique can be implemented within neural networks using TensorFlow and Keras.
Understanding Dropout Technique
Neural networks have hidden layers in between their input and output layers, these hidden layers have neurons embedded within them, and it’s the weights within the neurons along with the interconnection between neurons is what enables the neural network system to simulate the process of what resembles learning.
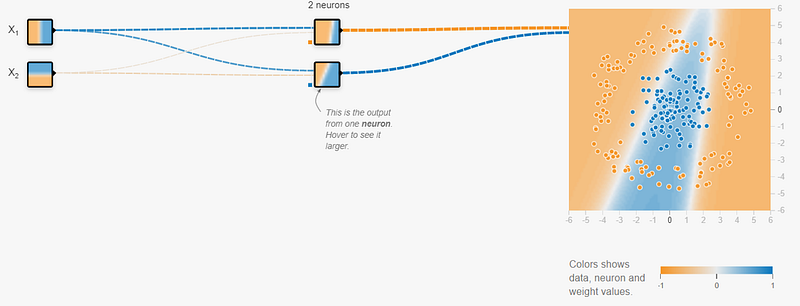
The general idea is that the more neurons and layers within a neural network architecture, the greater the representational power it has. This increase in representational power means that the neural network can fit more complex functions and generalize well to training data.
Simply kept, there are more configurations for the interconnections between the neurons within the neural network layers.
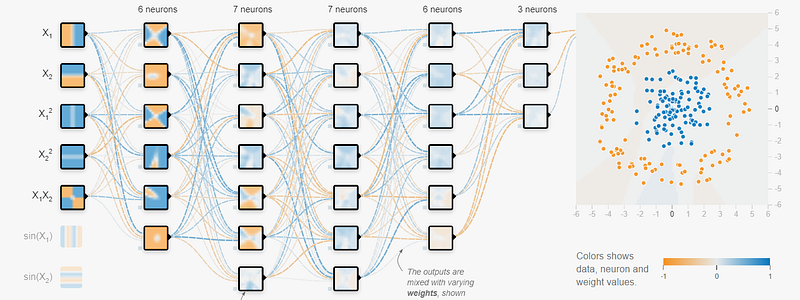
The disadvantage of utilizing deeper neural networks is that they are highly prone to overfitting.
Overfitting is a common problem that is defined as the inability for a trained machine learning model to generalized well to unseen data, but the same model performs well on the data it was trained on.
The primary purpose of dropout is to minimize the effect of overfitting within a trained network.
Dropout technique works by randomly reducing the number of interconnecting neurons within a neural network. At every training step, each neuron has a chance of being left out, or rather, dropped out of the collated contribution from connected neurons.
This technique minimizes overfitting because each neuron becomes independently sufficient, in the sense that the neurons within the layers learn weight values that are not based on the cooperation of its neighbouring neurons.
Hence, we reduce the dependence on a large number of interconnecting neurons to generate a decent representational power from the trained neural network.
Supposedly you trained 7,000 different neural network architecture, to select the best one you simply take the average of all 7,000 trained neural network.
Well, the dropout technique actually mimics this scenario.
If the probability of a neuron getting dropped out in a training step is set to 0.5; we are actually training a variety of different network at each training step as it’s highly impossible that the same neurons are excluded at any two training steps. Therefore a neural network that has been trained utilizing the dropout technique is an average of all the different neurons connection combinations that have occurred at each training step.
Practical scenarios
In practical scenarios, or when testing the performance of the trained neural network that utilized dropout on unseen data, certain items are considered.
The first being the fact that dropout technique is actually not implemented on every single layer within a neural network; it’s commonly leveraged within the neurons in the last few layers within the network.
In the experiments conducted in the published paper, it was reported that when testing on the CIFAR-10 dataset, there was an error rate of 15.6% when dropout was utilized in the last hidden layer. This was an improvement from the error rate of 16.6% that was reported when the same dataset was tested on the same convolutional neural network but with no dropout technique included in any of the layers.
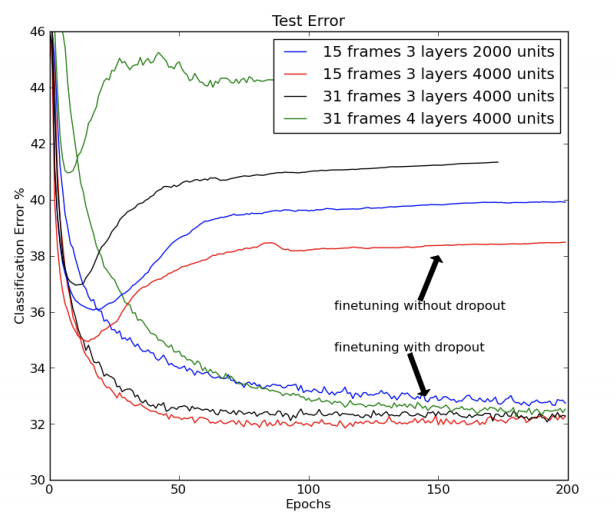
The second item is that within practical scenarios dropout isn’t utilized when evaluating a trained neural network. As a result of dropout not used during the evaluation or testing phase, the full potential of the neural network is realized. This means that all neurons within the network are active, and each neuron has more input connections than it had been trained with.
Therefore it’s expected to divide the weights of the neurons by one minus the dropout hyperparameter value(dropout rate that’s used during training). So if the dropout rate was 0.5 during training, then in test time the results of the weights from each neuron is halved.
Implementing Dropout Technique
Using TensorFlow and Keras, we are equipped with the tools to implement a neural network that utilizes the dropout technique by including dropout layers within the neural network architecture.
We only need to add one line to include a dropout layer within a more extensive neural network architecture. The Dropout class takes a few arguments, but for now, we are only concerned with the ‘rate’ argument. The dropout rate is a hyperparameter that represents the likelihood of a neuron activation been set to zero during a training step. The rate argument can take values between 0 and 1.
keras.layers.Dropout(rate=0.2)From this point onwards, we will go through small steps taken to implement, train and evaluate a neural network.
- Load tools and libraries utilized, Keras and TensorFlow
import tensorflow as tf
from tensorflow import keras2. Load the FashionMNIST dataset, normalize images and partition dataset into test, training and validation data.
(train_images, train_labels),(test_images, test_labels) = keras.datasets.fashion_mnist.load_data()
train_images = train_images / 255.0
test_images = test_images / 255.0
validation_images = train_images[:5000]
validation_labels = train_labels[:5000]3. Create a custom model that includes a dropout layer using the Keras Model Class API.
class CustomModel(keras.Model):
def __init__(self, **kwargs):
super().__init__(**kwargs)
self.input_layer = keras.layers.Flatten(input_shape=(28,28))
self.hidden1 = keras.layers.Dense(200, activation='relu')
self.hidden2 = keras.layers.Dense(100, activation='relu')
self.hidden3 = keras.layers.Dense(60, activation='relu')
self.output_layer = keras.layers.Dense(10, activation='softmax')
self.dropout_layer = keras.layers.Dropout(rate=0.2)
def call(self, input, training=None):
input_layer = self.input_layer(input)
input_layer = self.dropout_layer(input_layer)
hidden1 = self.hidden1(input_layer)
hidden1 = self.dropout_layer(hidden1, training=training)
hidden2 = self.hidden2(hidden1)
hidden2 = self.dropout_layer(hidden2, training=training)
hidden3 = self.hidden3(hidden2)
hidden3 = self.dropout_layer(hidden3, training=training)
output_layer = self.output_layer(hidden3)
return output_layer4. Load the implemented model and initialize both optimizers and hyperparameters.
model = CustomModel()
sgd = keras.optimizers.SGD(lr=0.01)
model.compile(loss="sparse_categorical_crossentropy", optimizer=sgd, metrics=["accuracy"])5. Train the model for a total of 60 epochs
model.fit(train_images, train_labels, epochs=60, validation_data=(validation_images, validation_labels))6. Evaluate the model on the test dataset
model.evaluate(test_images, test_labels)The result of the evaluation will look similar to the example evaluation result below:
10000/10000 [==============================] - 0s 34us/sample - loss: 0.3230 - accuracy: 0.8812[0.32301584649085996, 0.8812]The accuracy shown in the evaluation result example corresponds to the accuracy of our model of 88%.
With some fine-tuning and training with more significant epoch numbers, the accuracy could be increased by a few percentages.
Here’s a GitHub repository for the code presented in this article.
Dropout is a common regularization technique that is leveraged within the state of the art solutions to computer vision tasks such as pose estimation, object detection or semantic segmentation. The concept is simple to understand and easier to implement through its inclusion in many standard machine/deep learning libraries such as PyTorch, TensorFlow and Keras.
If you are interested in other regularization techniques and how they are implemented, have a read of the articles below.
Thanks for reading.