
Understanding and Coding the Attention Mechanism — The Magic Behind Transformers
In this article, I’ll give you an introduction to the attention mechanism and show you how to code the attention mechanism yourself.

How can we briefly describe attention? While we have multiple sensory perceptions such as sight, hearing, taste, etc., we always (often unconsciously) prioritize certain input information over others. For example, try to listen intently to your heartbeat while simultaneously trying to notice the smell of the environment and focus on all the red objects nearby. It is impossible to pay equal attention to all three different senses at the same time. So depending on the context we are in and what our goal is, we pay attention to different information.
If you like videos more, feel free to check out my YouTube video to this article:
Intuition and Goal
To better understand why applying such an attention behaviour to neural networks is a great idea, let’s have a look at what machine translation looked like in 2014:
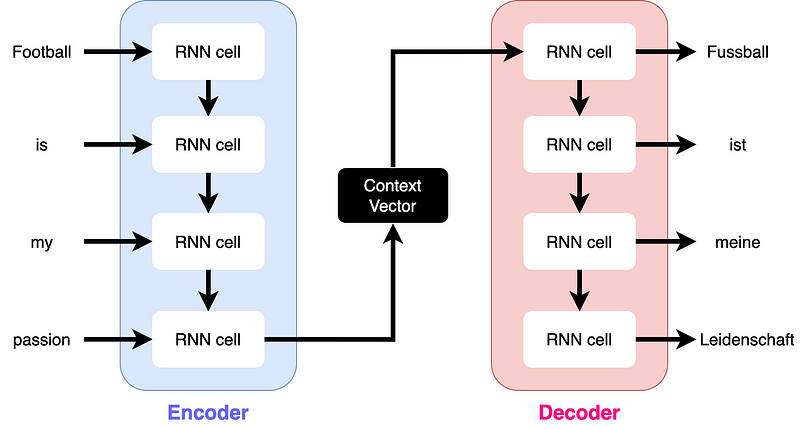
Back then, the encoder took the input sequence and summarized it into a fixed-size vector. This vector is also called a context vector and was then passed to the decoder as the only input. This approach led to two problems:
Compression of long sequences into a fixed-sized vector: Since sentences vary in length, it is particularly difficult to summarize all the information of longer sequences into a vector of fixed size. This often results in words at the beginning of the long sequence being less represented in the context vector than words at the end.
Slow inference: Due to the autoregressive structure of RNNs, each hidden state relies on its predecessor’s hidden state and must be computed sequentially, which doesn’t allow parallelization.
While slow inference primarily affects training time and which real-world scenarios such models can be used in, the difficulty of summarizing long sequences into a fixed-size vector affects the quality of the results produced by the model. Therefore, when introducing attention mechanisms into machine translation models, this was the major issue that needed to be overcome. To this end, Bahdanau et al. presented an idea in 2014 that can be illustrated as follows:
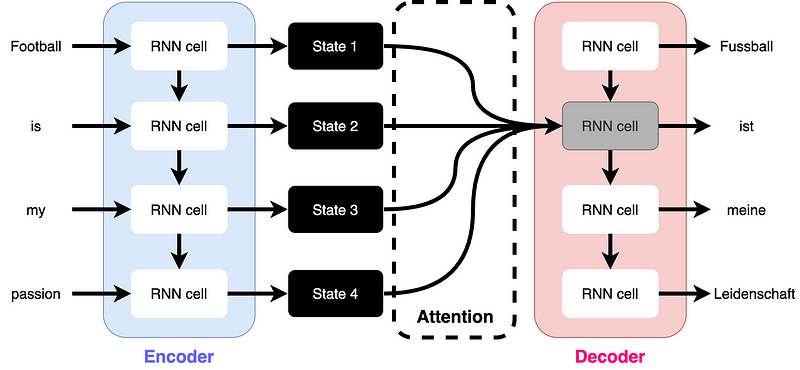
The idea is that each decoder cell can access all of the encoder’s hidden states, rather than combining a sequence into a fixed-size vector that is then passed through the decoder. By using the previous cell state of the decoder, the relevance of all hidden states of the encoder for the translation of the current token can be queried. But how does querying the relevance of the hidden encoder states work? This is where the attention mechanism comes into play.
Attention Mechanism
Since neural networks use mathematical operations under the hood, let’s look at how this attention mechanism works from a mathematical point of view. For this, three different things are calculated:
Alignment Score: How can we assess the relevance of each input token on the output token at a certain position? Bahdanau et al. present an alignment model for this purpose, which can be a feed-forward model. The model evaluates how well the inputs around position j and the output at position i match:
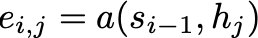
The alignment score eᵢ,ⱼ is based on the previous hidden decoder state sᵢ₋₁ and the j-th hidden encoder state hⱼ of the input sentence. Thus, an alignment score is calculated for each hidden encoder state hⱼ.
Weights: In the next step, all alignment results are converted into a probability distribution using the softmax function so that all resulting attention weights aᵢ,ⱼ summed up are equal to 1:
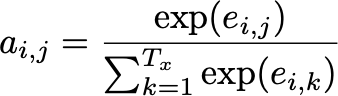
By applying the softmax function, the alignment scores get normalized.
Context Vector: In the final step, the context vector is computed using the previously computed attention weights aᵢ,ⱼ:
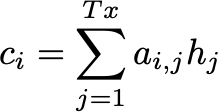
The context vector cᵢ is a weighted sum of all hidden states hⱼ of the encoder (denoted as Tₓ). It is then fed into the decoder at each time step i.
Generic Attention Mechanism
You may have heard about the famous paper “Attention is All You Need” by Vaswani et al. In this work Vaswani et al. introduced a more generic definition of attention which uses queries, keys and values.
If we wanted to apply the attention concept of Bahdanau et al. to the generic attention, the previous decoder step sᵢ₋₁ would be the query, while the hidden encoder states hⱼ would be both the values and the keys. Imagine if we ran our previous decoder step sᵢ₋₁ as a query against a key-value database. Then keys would be vectors and relevant keys would resemble our query so that we can access relevant values which are our hidden encoder states hⱼ. In this way, we would pay attention to the most relevant information (hidden encoder states) in our current context (previous decoder state sᵢ₋₁).
Another reason why this is considered a more general definition of attention is that it has been applied not only to the decoder, but also to the encoder. Retaining our previous representations, the Transformer architecture for machine translation using the generic attention introduced by Vaswani et al. can be represented as follows:
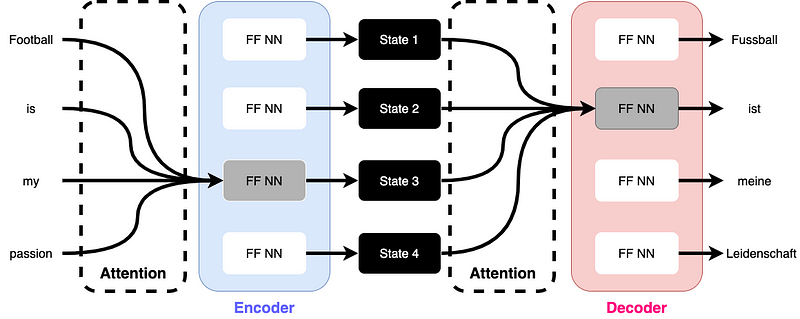
Because attention is used more generally in this architecture, the definitions of attention score, weight, and context vector are broader, but the idea behind them remains the same. Moreover, it can be seen that in the Transformer architecture, RNN cells have been replaced by feed-forward neural networks (FF NN), which counteracts the problem of slow inference due to the autoregressive structure of RNNs mentioned at the beginning.
Attention Score: Again, we first compute an attention score to evaluate the relevance of each key vector to a particular query vector. Think of it as if you were googling for a Python tutorial. Your keywords would be the query, and by matching the query vector with the key vectors of all possible websites, we can assess whether a website is relevant to that query or not. Basically, the query is matched against a database of key vectors kⱼ. The matching between query vector and key vector is done using the dot product. By applying the dot product to the query vector q and each key vector kⱼ, some kind of similarity value between query vector and key vectors can be calculated:
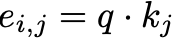
While the upper equation is a valid option for calculating an attention score, Vaswani et al. used a scaled dot product to calculate the attention score (dₖ states the dimensionality of the query vector and key vectors):
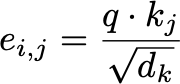
Okay, first, why did they use the dot product instead of the alignment model (feed-forward model) proposed by Bahdanau et al.? For this, Vaswani et al. state the following (the allignment model is also described as additive attention):
Additive attention computes the compatibility function using a feed-forward network with a single hidden layer. While the two are similar in theoretical complexity, dot-product attention is much faster and more space-efficient in practice, since it can be implemented using highly optimized matrix multiplication code.
Now second, why do they scale the dot product?
We suspect that for large values of dₖ, the dot products grow large in magnitude, pushing the softmax function into regions where it has extremely small gradients. To counteract this effect, we scale the dot products by 1/sqrt(dₖ).
Attention Weights: The attention weights are computed using the softmax operation in the same way as done by Bahdanau et al.:
Attention Vector: Likewise, the last step is basically the same as done by Bahdanau et al. The definition is just a bit broader, since we multiply the attention weights by the value vectors instead of the hidden encoder states:
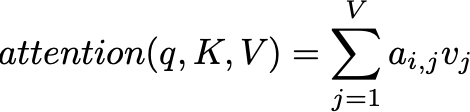
So far, we have focused only on how to compute the attention vector for a single query vector. As you may have seen, in the figure above, there is no longer an autoregressive structure that would require sequential computation of attention vectors. For this reason, in practice, attention vectors are computed as a set by packing queries, keys, and values into individual matrices and computing all attention vectors as follows:
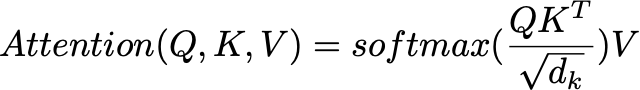
I know this is already a very long read, but before we start coding the attention mechanism, I want to make sure you not only know what attention is, but also understand why it works so well.
Where Do the Matrices Q, K and V Come From? You may have wondered where the individual vectors for query, key, and value come from. This is an important part to understand the general attention mechanism. First of all, the matrices Q, K, and V contain all the individual query, key, and value vectors. These matrices are calculated by applying matrix multiplication between the input embeddings and 3 matrices with trained weights: Wq, Wₖ, Wᵥ. Since these matrices are learned during training, the query, key and value matrices (which are calculated by matrix multiplication of the weight matrices with the input embeddings) differ from each other even though they have the same input. For the same input embeddings, multiple weight matrices Wq, Wₖ, and Wᵥ can also be trained, which is then called multi-head attention. In this way, a model can learn different representations and pay attention to different information of the same input in different attention heads.
Attention in an Encoder-Decoder Architecture: This part is especially important to better understand the Transformer architecture. In case you don’t know how the Transformer architecture looks like, it is shown below:
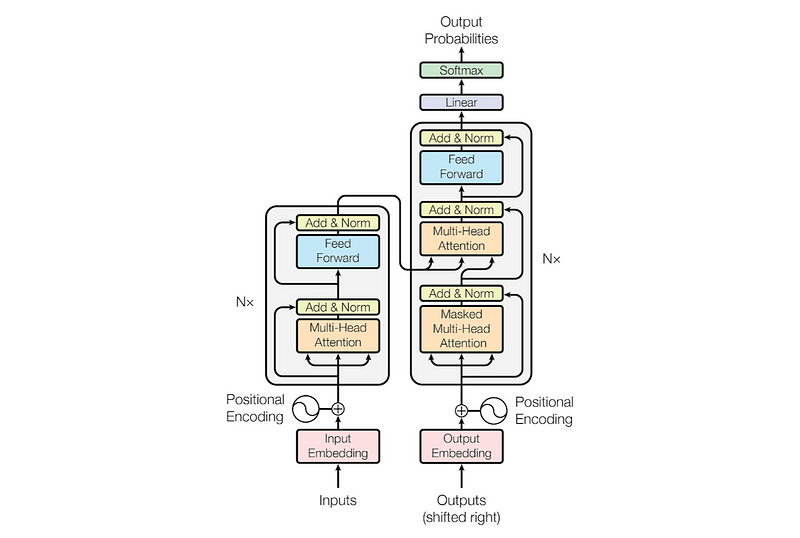
As can be seen in the figure, all three matrices in the first attention module for both the encoder and decoder come from previous layers (either the input or the previous attention layer). However, the decoder consists of another attention module (also called cross attention), where the query matrix Q comes from the previous decoder layer, while the key and value matrices K and V come from the encoder. In my opinion, this is very important to know in order to understand how the encoded representation of two languages is mixed to allow machine translation using Transformers.
Attention Is More Than Similarity: Instead of focusing only on words that are similar to the word given in a particular decoding step, attention can also be used to focus on words that are related but not similar to another. The following image shows the attention weights for the query word “making”:
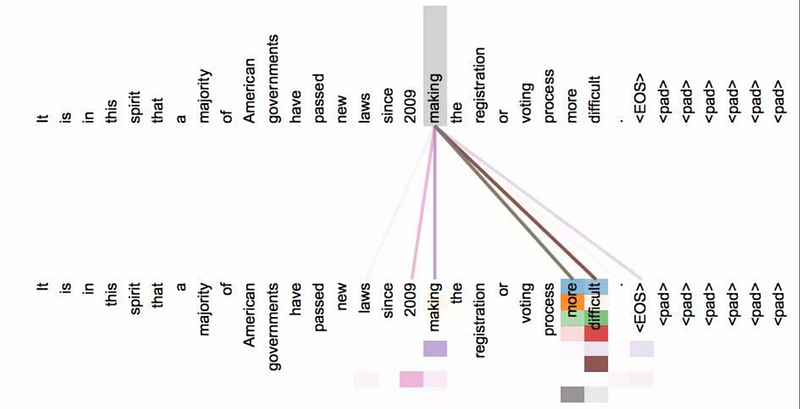
While thicker lines mean larger attention weights, we can see that attention is mainly focused on the word “making” itself and the words “more” and “difficult”. Intuitively, this makes sense, since “making” itself is the same word, and “more” and “difficult” are directly related to “making” in this context. But those are also related in other sentences. It is interesting to note that attention is also paid to the words “laws” and “2009”, which are less frequent and should be due to the context (sentence structure) as well as proximity to the word “making”. Although it is difficult to say exactly which NLP techniques are covered by the attention mechanism, the picture above gives an impression of how many different aspects are covered by the attention mechanism and how much it is related to the way we humans understand languages.
Coding the Attention Mechanism
After all the theory, you might think that implementing the attention mechanism is going to be a lot of work. However, actually only a few lines of code are needed for this. I myself found a really neat implementation done by Stefania Cristina using NumPy and SciPy:
# Code originates from:
# Stefania Christina (2022) The Attention Mechanism from Scratch [Source code].
# https://machinelearningmastery.com/the-attention-mechanism-from-scratch/
from numpy import random
from numpy import dot
from scipy.special import softmax
# encoder representations of four different words
word_1 = array([1, 0, 0])
word_2 = array([0, 1, 0])
word_3 = array([1, 1, 0])
word_4 = array([0, 0, 1])
# stacking the word embeddings into a single array
words = array([word_1, word_2, word_3, word_4])
# generating the weight matrices
random.seed(42)
W_Q = random.randint(3, size=(3, 3))
W_K = random.randint(3, size=(3, 3))
W_V = random.randint(3, size=(3, 3))
# generating the queries, keys and values
Q = words @ W_Q
K = words @ W_K
V = words @ W_V
# scoring the query vectors against all key vectors
scores = Q @ K.transpose()
# computing the weights by a softmax operation
weights = softmax(scores / K.shape[1] ** 0.5, axis=1)
# computing the attention by a weighted sum of the value vectors
attention = weights @ V
print(attention)Since I usually work with PyTorch, I reimplemented the code above with PyTorch. I will explain it step by step below.
First, let’s create our word embeddings (inputs):
import torch
word_1 = torch.tensor([1., 0., 0.])
word_2 = torch.tensor([0., 1., 0.])
word_3 = torch.tensor([1., 1., 0.])
word_4 = torch.tensor([1., 0., 1.])Of course, word embeddings usually contain many more dimensions and don’t consist only of 1s and 0s, but for our scenario this is sufficient.
Next, we stack these individual vectors into a matrix in order to speed up the calculation by matrix multiplication later:
input_embeddings = torch.stack([word_1, word_2, word_3, word_4], dim=0)Now it’s time to initialize our weight matrices (Q, K and V) randomly. To do this, we will initialize three different 3x3 matrices consisting of integer values ranging from 0 to 2 (this is definitely not mandatory and is based on Stefania Cristina’s implementation). Remember that these matrices are crucial for the attention mechanism to learn representations of the input data. Usually these matrices are optimized during training, but this is not covered in this tutorial:
torch.manual_seed(42)
W_Q = torch.randint(0, 2, (3, 3)).type(torch.float)
W_K = torch.randint(0, 2, (3, 3)).type(torch.float)
W_V = torch.randint(0, 2, (3, 3)).type(torch.float)Now that we have our weight matrices, we can calculate our query, key, and value matrices using matrix multiplication:
Q = torch.matmul(input_embeddings, W_Q) K = torch.matmul(input_embeddings, W_K) V = torch.matmul(input_embeddings, W_V)
As a next step, we now calculate the attention score by applying the scaled dot product. In case you didn’t know, the exponentiation of a given number by 0.5 is often used as an alternative to calculating the square root of this number. K.shape[1] specifies the dimension of the individual vectors (dₖ) in the matrix K:
attention_scores = torch.matmul(Q, K.transpose(1, 0)) / K.shape[1] ** 0.5Let’s now calculate the attention weights by applying the softmax function to our attention scores:
attention_weights = torch.softmax(attention_scores, axis=1)Finally, we calculate the attention matrix by matrix multiplication between our attention weights and the value matrix V.
attention_matrix = torch.matmul(attention_weights, V)
print(attention_matrix)Result:
tensor([[1.1634, 0.7909, 1.5817],
[1.0000, 0.8424, 1.5616],
[1.1799, 0.8707, 1.6405],
[1.1634, 0.7909, 1.5817]])It seems that our randomly initialized weight matrices lead to the third value of each word embedding vector receiving the most attention. However, the results should not be taken too seriously since our input embeddings are only three-dimensional and we didn’t optimize our three randomly initialized weight matrices.
Feel free to run the code yourself to better understand what happens at each step. For example, check out what the attention weights or weight matrices look like. Also, take a look at the calculated matrices Q, K, and V. I think this will further improve your understanding.
Final Thoughts
I hope you enjoyed this article. I will publish more articles about Deep Learning related topics in the future. I also write about topics in the field of Data Science and Data Engineering.
Isn’t collaboration great? I’m always happy to answer questions or discuss ideas proposed in my articles. So don’t hesitate to reach out to me! 🙌 Also, make sure to subscribe or follow to not miss out on new articles.
YouTube: https://bit.ly/3LqA1Os
LinkedIn: http://bit.ly/3i5Sc1g





{kind=link}