
Understanding a Basic Recommendation System

So I’ve been working on a project based on recommendation systems, and decided to blog out my understanding on how these systems work, hoping to help an upcoming data scientist. Also, feel free to connect with me via my LinkedIn :)
What is a Recommendation System?
A recommender system, or a recommendation system (sometimes replacing ‘system’ with a synonym such as platform or engine), is a subclass of information filtering system that seeks to predict the “rating” or “preference” a user would give to an item.
Let me simplify this for you. Below is a screenshot of a video playing on YouTube, and you can see a list of videos in the right hand side. These set of videos are shown (recommended) to us, because their content is similar to the video that we are watching, and the machine learning model predicts that we may be interested in them.
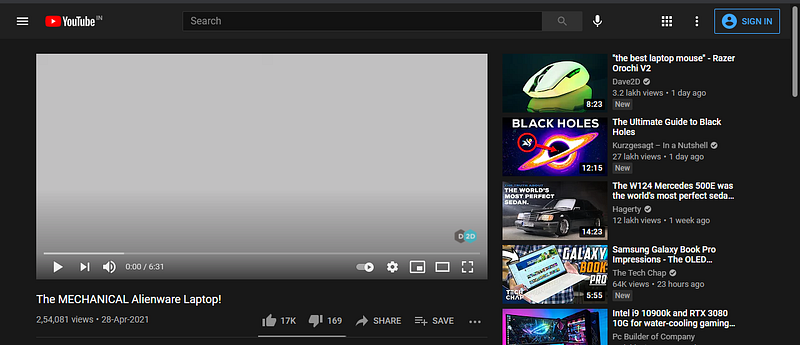
We can see similar systems being used in Netflix and Amazon where we come across categories such as “ Because you watched Inception: ” and “Customers who viewed this item also viewed: ”, respectively. Now, let’s try to understand these systems in-depth through various Matrix operations.
The Data
Let’s say we have a matrix A, where each row denotes a unique user (u_i) and each column denotes a unique movie (I_j), and the matrix element (A_ij) can be binary (if user u_i has watched movie I_j or not) or an integer (rating by user u_i on movie I_j). You will get a better understanding from the diagram below.
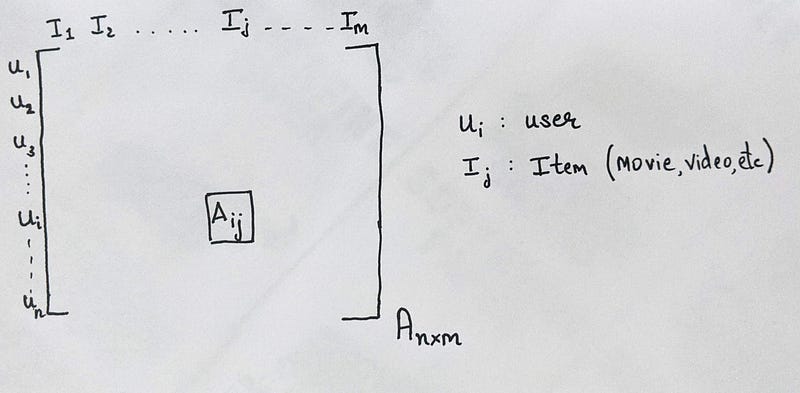
We can say that matrix A is a sparse matrix, meaning most of the values in the matrix are 0 or Na(in case of integers). Why? Because in the real world, where there are billions of users and millions of movies, it is nearly impossible for a single user to watch every single movie. So it is safe to assume that most of the elements in the matrix are 0 or Na.
From this given matrix A, we can understand how a recommendation system is built.
Simple Recommender Systems
a) User-User based Recommendation Systems:
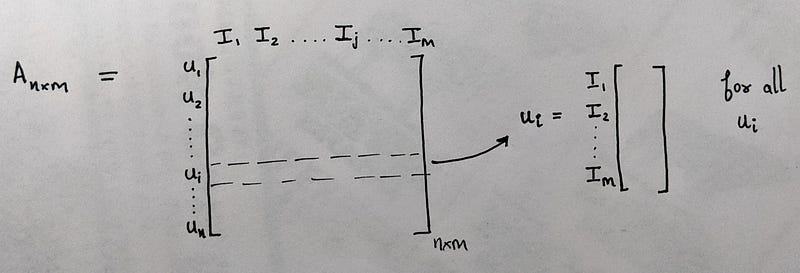
- Consider a Matrix A having n rows (users) and m columns (items) (as shown).
- We can separate all the user vectors (u_1, u_2….,u_n) from the matrix A, as shown. Each vector consists of ratings given by user u_i on movies I_1 to I_m
- Now, taking all combinations of u_i and u_j, we can compute the similarity between the two vectors. Meaning, we can compute how similar two users are to each other. In our case, we will compute the cosine similarity between the two vectors. Thereby, creating a Similarity Matrix S (nxn).
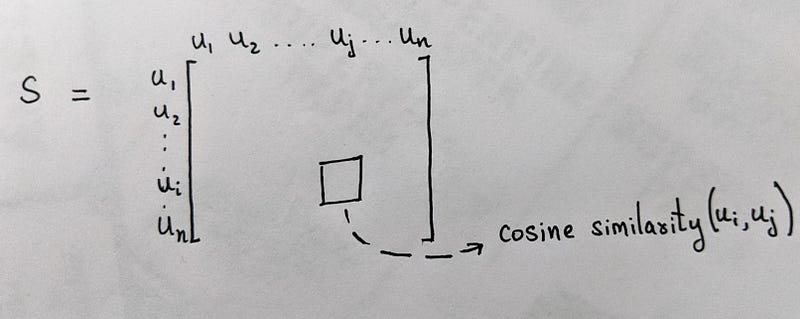
Now, if we have to recommend something to (say) user u_10, we can check who u_10 is most similar to (preferably top 3 similar). Then we check which items (movies) are not watched by u_10, but are rated well by the similar users. Those items can be recommended to our user u_10.
The problem with this approach is that a users likes/dislikes change over time, so we might end up recommending things which the user may not be interested anymore.
b) Item-Item based Recommender systems
This type of Recommender System was popularly used by Amazon in the early 2000s.
- The concept here is pretty much similar to the user-user type of recommendation system. The main difference here is that instead of computing the similarity matrix S from the user vectors, we compute it using the item vectors.
- Each vector I_j (I_1, I_2 … I_m) consists of all ratings given by every user (u_1, u_2 … u_n) on item j.
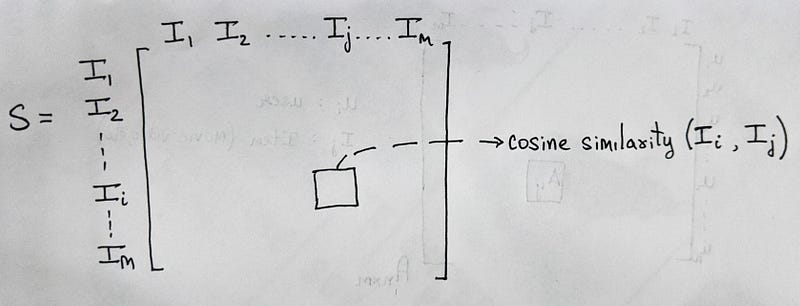
Now, if a user likes movies (say) I_10, I_21 and I_30, we can check which movies are the most similar to these, giving preference to the commonly found ones.
The item-item based recommendation system can be used when a) number of users is much more than the number of items, and b) When we know that the item ratings will not change after a certain period of time.
Machine Learning based Recommender Systems
Modern Recommendation Systems are built using Machine Learning techniques. A recommendation system can be:
1. Classification/Regression System (Content Based Filtering):
From a Matrix A, if we have more information about every user u_i and movie m_j, we can go ahead and create a new traditional dataset with the features of u_i concatenated with features of m_j, as the attributes, and element A_ij being the class label. (as shown)
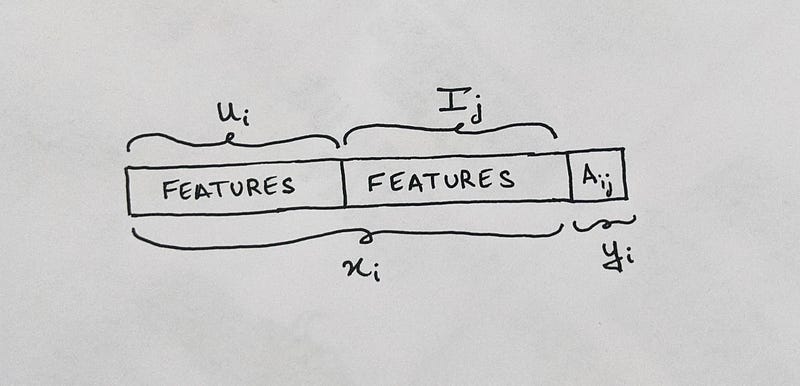
Our model can train on the data where A_ij is available. The test data consists of all the Null A_ij values (Recommendation).
The main task here is arriving at feature representation of u_i & m_j.
2. Matrix Completion System (Collaborative Filtering):
- This is a more commonly used method and we will dive into the mathematics behind this method in the later parts of this series. To give you a basic understanding of how this works, lets say a user u_1 has watched and liked movies I_1, I_3 and I_7, and user u_2 has watched and liked movies I_3, I_6 and I_7.
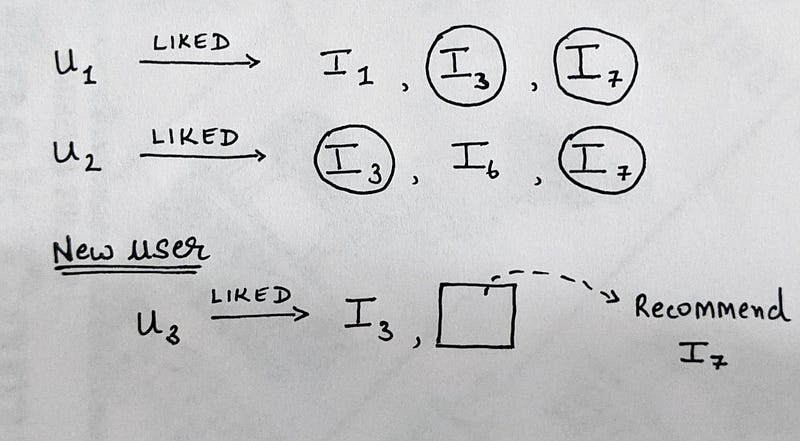
- Now consider another user u_3, who has just finished watching movie I_3.
- Based on the available data, we know that users (u_1 and u_2) who have liked movie I_3, have also liked movie I_7. Thus it may be safe to recommend movie I_7 to our user u_3.
Conclusion
In the next part of this series, We will see how to solve this matrix completion problem, using operations such as Non-Negative Matrix Factorization. We will also look at how the machine learning optimization equation is solved and how a recommendation is given to a user.



