
Active Learning (ultimate guide)
[This blog is a compilation of information gathered from reference sources, where the main content has been retained while focusing on organizing and structuring the information.]
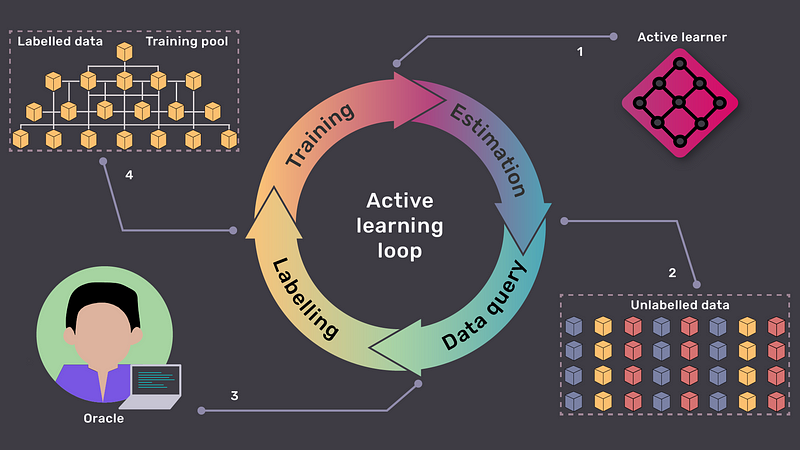
With the advent and explosion of deep-learning based ML-models, and more recently foundation models, active learning is becoming ever-more important to bridge the gap between prototype and production AI models. Active learning is even heralded as the future of generative AI. The main goal of active learning is to intelligently curate training data and improve model performance by surfacing the most informative data samples for labeling to reduce uncertainty in your model and reduce the cost of manually labeled data.
Active learning’s idea is simple: let the model choose the samples for annotation instead of labeling the whole dataset. This method leads to a more efficient annotation process. Active Learning models can achieve the baseline performance (the accuracy of the model trained on the whole dataset), with a considerably lower amount of labeled data.
Active learning is a powerful approach for improving the performance of machine learning models by reducing labeling costs and improving accuracy and generalization.
What is Active Learning?
Active learning is a supervised machine learning approach that aims to optimize annotation using a few small training samples. During the training stage and even into the production stage, a supervised machine learning process involves a continuous feedback loop whereby annotators and data scientists provide more data points to keep improving the model’s performance and accuracy.
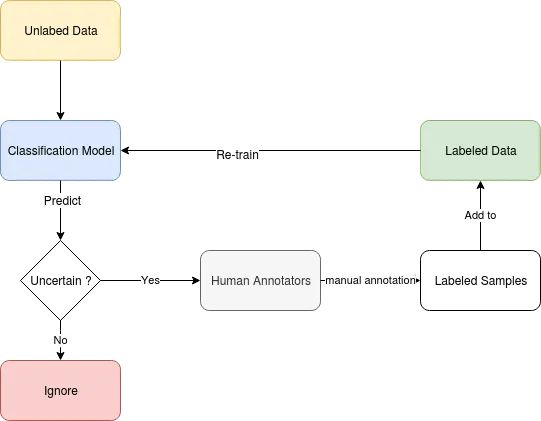
Difference Between Active Learning and Passive Learning
Passive learning and active learning are two different approaches to machine learning. In passive learning, the model is trained on a predefined labeled dataset, and the learning process is complete once the model is trained.
In contrast, in active learning, the informative data points are selected using query strategies instead of a pre-defined labeled dataset. These are then passed to be labeled by an annotator before being used to train the model. By iterating this process of using informative samples, we constantly work on improving the performance of a predictive model.

Advantages of Active Learning
Unfortunately, data annotation can be a costly and time-consuming endeavor, especially when outsourcing this work to large teams of human annotators. Many teams don’t have the time, money, or manpower to label and review each piece of data in these vast datasets.
Active learning is a powerful technique that can help overcome these challenges by allowing a machine learning model to selectively query a human annotator for the most informative data points to label in image or video-based datasets. By iteratively selecting the most informative samples to label, active learning can help improve the accuracy of machine learning models while reducing the amount of labeled data required.
- Reduced Labeling Costs: Labeling large datasets is time-consuming and expensive. Active learning helps to reduce labeling costs by selecting the most informative samples that require labeling.
- Improved Accuracy: Active learning improves the accuracy of machine learning models by selecting the most informative samples for labeling.
- Faster Convergence: The model can learn more quickly and converge faster by focusing on the most relevant samples.
- Improved Generalization: Active learning helps machine learning models to generalize better to new data by selecting the most diverse samples for labeling.
- Robustness to Noise: By selecting the most informative samples, active learning algorithms are trained on the samples that best represent the entire dataset. Hence, the models trained on these samples will perform well on the best data points and the outliers.
Two main type of Active Learning Strategies:
- Informativeness Informativeness-based query strategies mostly assign an informative measure to each unlabeled instance individually. The instance(s) with the highest measure will be selected.
- Representativeness Only considering the informativeness of individual instances may have the drawback of sampling bias and the selection of outliers. Therefore, representativeness, which measures how instances correlate with each other, is another major factor to consider when designing AL query strategies.
- Hybrid There is no surprise that informativeness and representativeness can be combined for instance querying, leading to hybrid strategies. A simple combination can be used to merge multiple criteria into one.
Categorizing Active Learning Strategies
This step of selecting the data points can be categorized into three methods:
- Selective Sampling: The sampling strategy measures the informativeness of the samples and determines which samples the model should request labels for to improve its performance. For example, uncertainty sampling selects the samples the model is most uncertain about, while diversity sampling selects the samples most dissimilar to the samples already seen.
- Pool-based Sampling: In this approach, a pool of unlabeled data is created, and the model selects the most informative examples from this pool to be labeled by an expert or a human annotator.Pool-based sampling can be further categorized into uncertainty sampling, query-by-committee, and density-weighted sampling.
- Synthesis Methods: Query synthesis methods are a group of active learning strategies that generate new samples for labeling by synthesizing them from the existing labeled data. The methods are useful when your labeled dataset is small, and the cost of obtaining new labeled samples is high.
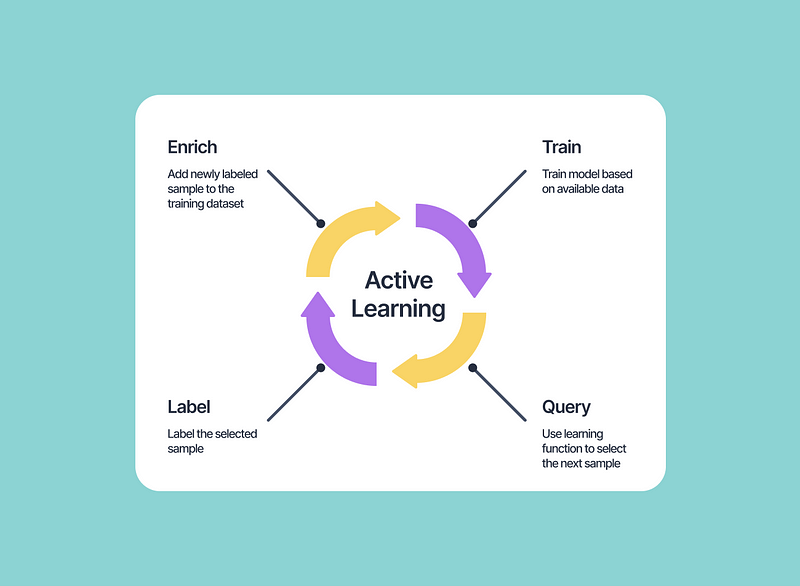
Active learning: strategies for subsampling
Selecting the best query strategy is very important as they decide which data points are informative and should be sent for labeling and used for further training. The efficiency of the active learning pipeline can be determined by how quickly the query strategy can select the most effective sample from the pool of unlabeled data.
- Uncertainty-based Sampling
- Committee-based Sampling
- Diversity Weighted Methods
- Expected Model-change-based Sampling
- Expected Error Reduction
- Stream-based Sampling
- Active Regression
- Bayesian optimization
- Multilabel Strategies
Uncertainty-based Sampling
Uncertainty sampling is a query strategy that selects samples that are expected to reduce the uncertainty of the model the most. The uncertainty of the model is typically measured using a measure of uncertainty, such as entropy or margin-based uncertainty. Samples with high uncertainty are selected for labeling, as they are expected to provide the most significant improvements to the model’s performance.
Uncertainty-based strategies are the most convenient way for querying labels. Despite the simple nature of these methods, they have shown high performance in all sorts of tasks (even higher performance in some tasks compared to other complicated approaches).
Committee-based Sampling
Query-by committee is a query strategy that involves training multiple models on different subsets of the labeled dataset and selecting samples based on the disagreement among the models.
This strategy is useful when the model tends to make errors on specific samples or classes. By selecting samples on which the committee of models disagrees, the model can learn to recognize sample patterns and improve its performance in those classes.
Diversity Weighted Methods
Diversity-weighted methods select examples for labeling based on their diversity in the current training set. It involves ranking the pool of unlabeled examples based on a diversity measure, such as the dissimilarity between examples or the uncertainty of the model’s predictions.
Expected Model-change-based Sampling
Expected model-change-based sampling is an active learning method that selects examples for labeling based on the expected change in the model’s predictions. This approach aims to select examples likely to cause the most significant changes in the model’s predictions when labeled to improve the model’s performance on new, unseen data.
In expected model-change-based sampling, the unlabeled examples are first ranked based on estimating the expected change in the model’s predictions when each example is labeled.
This estimation can be based on various measures such as expected model output variance, expected gradient magnitude or by measuring the euclidean distance between the current model parameters and the expected model parameters after labeling.
Using this approach, the examples that are expected to cause the most significant changes in the model’s predictions are then selected for labeling, with the idea that these examples will provide the most informative training data for the model. These samples are then added to the training data to update the model.
Expected Error Reduction
Expected error reduction is an active learning method that selects examples for labeling based on the expected reduction in the model’s prediction error. The idea behind this approach is to select examples likely to reduce the model’s prediction error the most when labeled, to improve the model’s performance on new, unseen data.
In expected error reduction, the unlabeled examples are first ranked based on estimating the expected reduction in the model’s prediction error when each example is labeled. This estimation can be based on various measures, such as the distance to the decision boundary, the margin between the predicted labels, or the expected entropy reduction.
Active Learning for NLP
Active learning is quite popular in the world of NLP. Specifically, information extraction for POS tagging, Named Entity Recognition (NER), etc., require lots of training (labeled) data, and the cost of labeling data for these kinds of use cases is really high. Most of the advanced language models are based on deep neural networks and trained on large datasets. However, under typical training scenarios, the upper hand deep learning usually commands will diminish if the datasets are too small. Hence to make deep learning broadly useful, it is crucial to find an effective solution for the above problem.
>> Active Learning for Text Classification example
Tools for Active Learning
- Cleanlab : Proposing a novel active learning method, called ActiveLab, that results showed that under a fixed total number of allowed annotations, training datasets constructed with ActiveLab lead to much better ML models vs. other active learning methods.
- modAL (A modular active learning framework for Python3): modAL is an active learning framework for Python3, designed with modularity, flexibility and extensibility in mind. Built on top of scikit-learn, it allows you to rapidly create active learning workflows with nearly complete freedom. modAL supports many of the active learning strategies discussed in the previous sections, such as probability/uncertainty-based algorithms, committee-based algorithms, error reduction, and so on.
- libact (Pool-based Active Learning in Python): libact is a python package designed to make active learning easier for real-world users. The package not only implements several popular active learning strategies but also features active learning by learning meta-strategy that allows the machine to automatically learn the best strategy on the fly.
- AlpacaTag : AlpacaTag is an active learning-based crowd annotation framework for sequence tagging, such as named-entity recognition (NER). Intelligent recommendation , Automatic crowd consolidation and Real-time model deployment are some of the distinctive advantages of AlpacaTag.
When to stop Active Learning?
When adopting AL in practice, it would be desirable to know the time to stop AL when the model performance is already near the upper limits, before running out of all the budgets. For this purpose, a stopping criterion is needed, which checks certain metrics satisfying certain conditions.
For the design of a general stopping criterion, there are three main aspects to consider: Metric, Dataset, and Condition.
For the metric, measuring performance on a development set seems a natural option. However, the results would be unstable if this set is too small and it would be impractical to assume a large development set. Cross-validation on the training set also has problems since the labeled data by AL is usually biased.
The dataset to calculate the stopping metric requires careful choosing. The results could be unstable if not adopting a proper set.
The condition to stop AL is usually comparing the metrics to a pre-defined threshold. Earlier works only look at the metric at the current iteration, for example, stopping if the uncertainty or the error is less than the threshold
Active Learning in production
Active learning pipelines — semi-automatic
In a semi-automatic or semi-active learning approach, each cycle runs automatically, but it needs to be triggered manually. Key areas where manual intervention is required are at –
1. selecting the data for annotation — we need to choose the next images in an informed way.
2. Selecting the best model out of the ensemble of models created among each cycle
A semi-automatic pipeline needs to be closely monitored for its performance indicators, such as the model performance metrics after each active learning cycle. Inherently this technique is prone to errors, especially when it requires a number of learning cycles.
>> An example of semi-automatic or semi-active Learning with AutoTrain and Prodigy
Active learning pipelines —automatic
So what happens in an automatic pipeline is that we leave the two manual intervention steps to a smart algorithm. Selecting the data for annotation could be through any one of the sampling techniques discussed in the previous section, i.e, Querying, Pool based sampling, etc. Selecting the best model could be again based on any of the performance metrics of our choice or their weighted values.
References:
[1] Optimizing Annotation Effort Using Active Learning Strategies: A Sentiment Analysis Case Study in Persian (Ashrafi Asli et al., LREC 2020)
[2] Top 6 Tools for Active Learning in Machine Learning
[3] A Survey of Active Learning for Natural Language Processing (Zhang et al., EMNLP 2022)
[4] Active Learning: Strategies, Tools, and Real-World Use Cases





