
Two minutes NLP — Quick intro to Text Simplification
Applications, Extractive methods, Abstractive approaches, Lexical Simplification and Novel Text Generation

Text Simplification aims to reduce the linguistic complexity of content to make it easier to understand, while still retaining the original information and meaning.
For example, the complex sentence “The ominous clouds engulfed the hill” may be transformed into its simpler form “The gloomy clouds covered the hill”.
Over time, approaches to Text Simplification have shifted from manual, hand-crafted rules to automated simplification. Research in the field has clearly shifted towards utilizing deep learning techniques, with a specific focus on developing solutions to combat the lack of data available for simplification.
Applications
Among the most prominent target audiences for Text Simplification are foreign language learners, often focusing on lexical but also sentence-level simplification. Text Simplification is also of interest to dyslexics, and the aphasic, for whom particularly long words and sentences, but also certain surface forms such as specific character combinations, may pose difficulties.
Approaches
Most of the early work in the field involved extractive methods of summarization, i.e. extracting the sentences from a document that conveyed the most meaning. The research in simplification has shifted towards abstractive approaches with the actual generation of text.
Abstractive Approach
Initially this involved sentence level simplification through lexical (word-based or phrasal-based) selection and substitution, like using a Paraphrase Database.
In recent years, text simplification has evolved to actual generation of new and novel text, thanks to the advent of neural networks, especially Recurrent Neural Networks, Long Short-Term Memory networks, and Transformers, which allow sequence-to-sequence modeling.
Abstractive Approach with Lexical Simplification
These approaches are basically a pipeline where complex words in sentences are identified and then replaced by substitutions, which have been previously filtered and ranked by relevance.
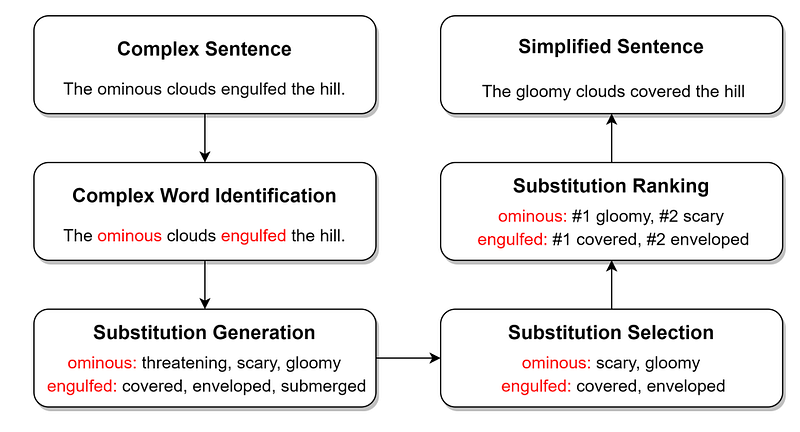
In a sample Lexical Simplification pipeline:
- Complex Word Identification is usually done with indexes like the Zipf word frequencies.
- Substitution Generation is often done looking for synonyms in lexical databases like WordNet.
- Substitution Selection is done by performing Word Sense Disambiguation to select the candidates with the correct meaning.
- Substitution Ranking can be done by selecting the simpler candidates leveraging again the Zipf word frequencies.
This article is a practical example of how to perform Lexical Simplification with BERT.
Abstractive Approach with Novel Text Generation
As opposed to Lexical Simplification, which aims to reduce the complexity of a text by simplifying the vocabulary, syntactic simplification seeks to identify grammatically complex text, and rewrite it so that it is easier to comprehend. This may involve splitting long sentences into shorter, more digestible chunks, changing passive voice usage to active, and resolving ambiguities and anaphora. Text Generation is done with sequence-to-sequence models.
See this article for an example of a sequence-to-sequence model trained for text simplification.
Thank you for reading! If you are interested in learning more about NLP, remember to follow NLPlanet on Medium, LinkedIn, and Twitter!
Two minutes NLP related posts