
Two minutes NLP — Basic taxonomy of Topic Tagging models and elementary use cases
LDA, NMF, Top2Vec, and WikiData
Topic Tagging is the process of assigning topics to the content of various forms, the most spread being text.
Topic Modeling
Topic Modeling is a set of unsupervised techniques to extract these topics, such as LDA, NMF, and Top2Vec. These techniques automatically detect topics specific to the corpus of documents analyzed, without the need of external taxonomies.
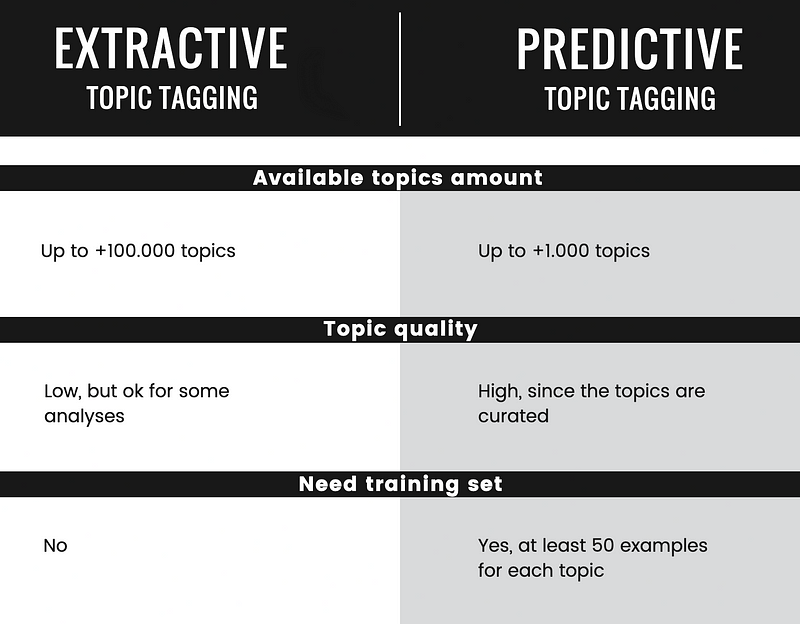
Extractive Topic Tagging
Works by detecting the keywords contained in a text and using their normalized forms as topics. Often these topics are enriched using categories from open-source knowledge bases like WikiData.
Predictive Topic Tagging
Works with a predefined set of topics, by training a classification model with several examples of texts for each topic, making it a multilabel classification problem. The training set can be scraped from the web since each published article with tags is a potential training sample.
Datasets
- WikiData: a collaboratively edited multilingual knowledge graph hosted by the Wikimedia Foundation. It is a common source of open data that Wikimedia projects such as Wikipedia.
- Media Topics: a constantly updated taxonomy of over 1,200 terms with a focus on categorizing text about media. Originally based on the IPTC Subject Codes taxonomy.
- 20 newsgroups: a dataset comprises around 18000 newsgroups posts on 20 topics.
Use cases
- Analysis of blog articles of companies to deduce their content marketing strategy.
- Analysis of news data.
- Quick organization of a corpus of documents by topics.
Code examples
Two minutes NLP related posts

Stay up to date with the latest stories about applied Natural Language Processing and join the NLPlanet community on LinkedIn, Twitter, Facebook, and Telegram.





