
Tuning Whatnot’s Data Platform for Speed and Scale
City planners have a tough task. Given scarce space and scant knowledge of the future, they must lay out the zones, infrastructure, and codes to foster a vibrant urban ecosystem. Neglect the planning, and even with the best materials and economy, the city may within up a convoluted mess.
Data platform teams face a similar challenge today. In a “modern data stack” world, the difference between building a data metropolis or a data wasteland is one of planning and execution, not technology.
At Whatnot, our core principle to “move uncomfortably fast” in support of our customers puts even more pressure on data systems. New features and new teams makes data stale. Staleness creates instability. Instability breeds distrust.
To stay ahead of these problems, the data platform team adopted firmer principles around organization, ownership, and automation. Although we made a few architectural changes since our last post (including adding real-time data systems), here I want to detail a few principles guiding the team as we hardened patterns in the platform.
Principle: Build Modules, Not Monoliths
Loosely coupled systems scale better. Allowing more people to develop data models in dbt Cloud should never break critical assets. Letting five teams orchestrate Python scripts on Dagster Cloud should not risk production pipelines. Add new machine learning models to our MLOps platform should not make existing services suffer.
Whatnot teammates are regularly adding more data, products, and use cases. To handle this increasing load, we made our platform as modular as possible. We built workflows into every system to ensure the entire lifecycle of a new product could be managed in isolation.
This doesn’t mean we aren’t building a data warehouse that integrates information and creates a coherent view of the business — the platform still hosts the orders table and the livestreams table. What modular means here is that users should be able to understand what data is being exposed and dependencies are explicitly seen.
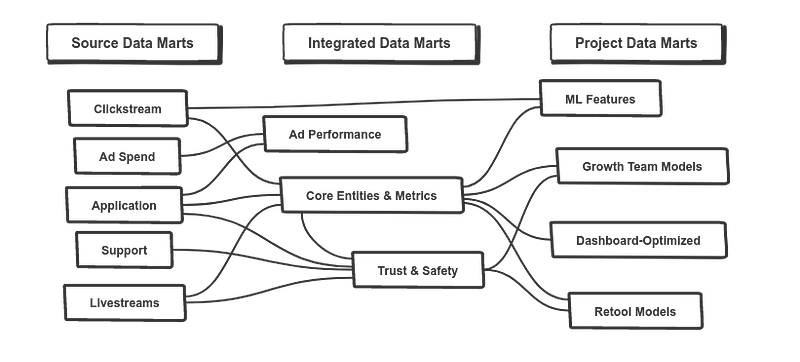
To do this, we reorganized our dbt project, placing each of the 150 data models inside a “mart” with explicit ownership and dependencies. Each mart fits in one of three categories: an application data mart that exposes data from a specific data producer, and contains no logic external to that system; an integrated data mart, that reads from one or more sources and creates useful, integrated views of data; and project-specific data marts, that can be created with short notice and little planning, but which have accordingly smaller scope and loose SLAs.
Principle: Domains Own Their Data
In a small organization, a data team can manage the entire lifecycle of a data product: how it’s generated, how it’s transformed, how it’s presented. Even though Whatnot is only a couple years old, we move so fast that centralized management is already impossible.
Our analytics team felt this tension when reporting on client-side behavior. Events fired from mobile devices drive key company metrics, such as “daily active users”. But since our application changes daily — and often dramatically — ensuring stability of this metric was a major problem and required direct conversations across team boundaries.
To speed up the identification and resolution of issues, the data and engineering teams decided to shift the problem “left,” away from the analytics consumers and towards the application data producers.
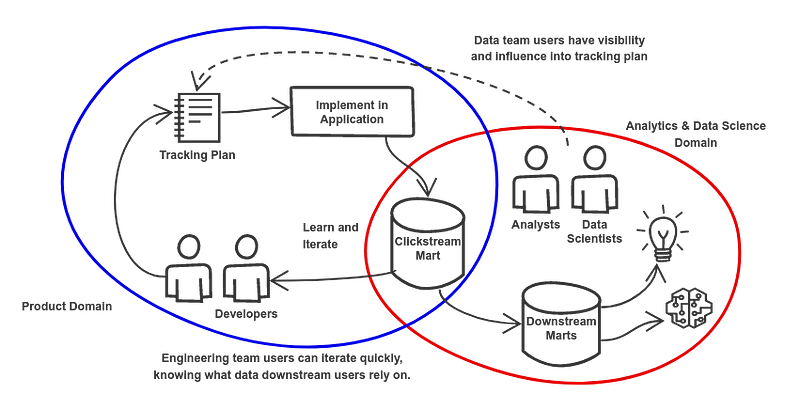
The technical solution is straightforward: set up a version-controlled tracking plan that could power server-side event validation. But the organizational solution is more impactful: setting up a channel where conversations could happen between key stakeholders — engineers, analysts, data scientists — before events make it into a product release.
To do this, we housed the tracking plan in a Github repo and set up a couple of issue templates. When a developer wants to create a new event for measurement, they can create an issue, and stakeholders discuss the best way to code it up. When changes are made and merged into the main branch, a Github Action updates the tracking plan Segment and the new events are passed through.
We used Pydantic to define simple data classes for properties and events to make it easy to reuse code for future events and to support multipe output formats. An example is shown below:
# Events are defined using Pydantic data classes
# But can be exported to other formatslivestream_created_event = DefaultEvent(
name = “livestream_created”,
properties = [
Property(
name=”livestream_id”,
description=”The id of the livestream.”
),
Property(
name=”category_id”,
data_type=”integer”,
]
)event_json = livestream_created_event.to_segment_json()
event_avro = livestream_created_event.to_avro()The real upshot of this approach is speed: because there is a process shared between teams, because decisions are made in the open, conversations are to-the-point: the analytics team can bring up issues where specific events are not firing as expected, and the engineering team can get feedback on new events during the development cycle.
Principle: Automate Platform Processes
The adage to “apply software engineering principles to data systems” is standard by now. But data teams that want to implement version control, consistent CI/CD, multi-stage environments, and comprehensive testing have a lot of work to do.
The best time to make this standard, though, is at the beginning. To support speed and scale — particularly as we add new data engineers that want to make an impact fast — we need these built-in guardrails. All of the workflows described above have automated workflows, and we leaned into a few more: using Terraform Cloud to manage AWS and Snowflake resources, and integrating Okta into all of our tools so that new hires had immediate access to data tools and assets.
In fact, as we build out a platform-centric data strategy with self-serve resources, identifying areas of automation forms a useful line to demarcate ownership. For example:
- Domain experts own decisions about data definitions; the data platform owns automatically promoting and validating these definitions.
- Domain analysts own new data marts and products; the data platform team owns the infrastructure, execution, and automation of the products.
- Domain experts own the machine learning model lifecycle; the data platform team owns the infrastructure supporting machine learning and data operations.
This “centrally-managed, domain-owned” platform approach is inspired by data mesh principles, and we expect it to scale well. Although it has led to a couple of architectural changes — migrating from Airflow to Dagster Cloud for its modular design and out-of-the-box CI/CD support — it is largely a bet that, with great tools and clear zoning, our talented employees will produce better outcomes from data than if a centralized team tried to manage it all.
The Future: Towards Better Discovery, Privacy, and Trust
The actions we’ve taken above are foundational to the platform team’s operations today. But they also set us up to tackle the next major challenges on the horizon: enabling faster discovery, enforcing strict privacy requirements, and proactively establishing more trust in data.
As city planners define frameworks for organizing a city before knowing what exactly will be built, they can plan for success by following principles and thinking strategically about zoning, development, and the environment. So, too, can data platform teams take a principled approach to building out their stack, even in its early stages.
If you’re interested in working on a data team doing real-time analytics, deploying machine learning services at scale, or innovating with data platform design, check out our job postings!





