
Tsinghua U & BAAI’s CogView2 Achieves SOTA Competitive Text-to-Image Generation With 10x Speedups

Text-to-image generation has become one of the most publicly engaging AI research fields, with OpenAI’s recently unveiled state-of-the-art DALL-E-2 model garnering global mainstream media attention with its stunningly hyperrealistic images. High-performance autoregressive models like DALL-E-2 and 2021’s CogView however remain limited by slow generation speeds and expensive high-resolution training costs. Moreover, these models’ uni-directional token generation process differs from the bidirectional masked prediction of vision transformers (ViTs), limiting their application on traditional visual tasks such as image classification and object detection.
A research team from Tsinghua University and the Beijing Academy of Artificial Intelligence addresses these issues in their new paper CogView2: Faster and Better Text-to-Image Generation via Hierarchical Transformers, introducing a pretrained Cross-Modal general Language Model (CogLM) for efficient text and image tokens prediction. When finetuned for fast super-resolution, the resulting CogView2 hierarchical text-to-image system generates images with comparable resolution and quality at speeds up to 10x faster than CogView.

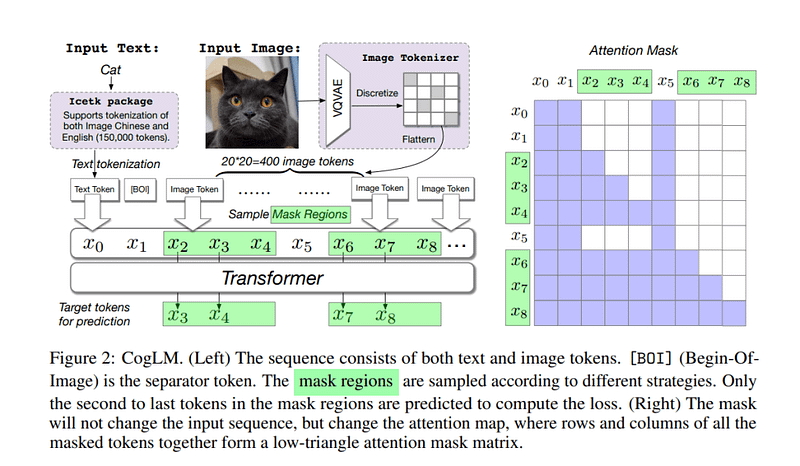
This work aims to build a simple and general language model for both text and image data that unifies autoregressive generation and bidirectional context-aware mask prediction. In the pretraining stage, the researchers employ a unified tokenizer (ICE Tokenizer, Icetk) for Image, Chinese, and English that captures bilingual text and image tokens. They use a transformer with Sandwich LayerNorm as the CogLM backbone, and scale the model up to six billion parameters. A smart and versatile masking strategy is designed and implemented to improve model performance and enable finetuning for different downstream tasks.
The team further proposes a CogView2 system to support interactive text-guided editing on images and fast super-resolution. They summarize their hierarchical generation process as:
- First, we generate a batch of low-resolution images (20x20 tokens in CogView2) using the pretrained CogLM, and then (optionally) filter out the bad samples based on the perplexity of CogLM image captioning, which is the post-selection method introduced in CogView.
- The generated images are directly mapped into 60x60-token images by a direct super-resolution module finetuned from the pretrained CogLM. We use local attention implemented by our customized CUDA kernel to reduce the training expense. The high-resolution images from this step usually have inconsistent textures and a lack of details.
- These high-resolution images are refined via another iterative super-resolution module finetuned from the pretrained CogLM. Most tokens are re-masked and re-generated in a local parallel autoregressive (LoPAR) way, which is much faster than the usual autoregressive generation.
The team conducted extensive experiments on 30 million text-image pairs and compared the proposed CogView2 with popular benchmarks such as DALL-E-2 and XMC-GAN.
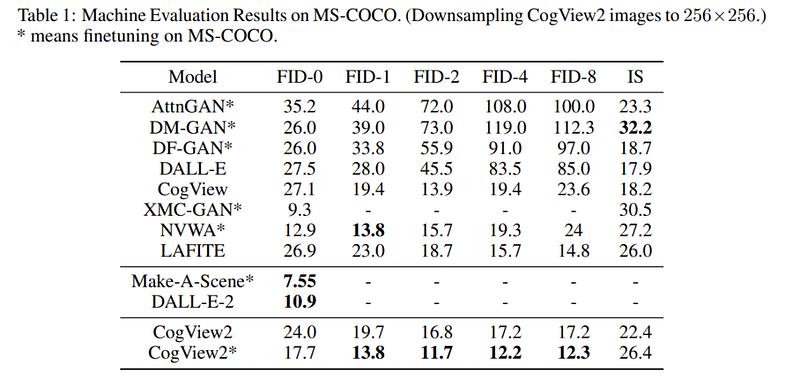
The results show that finetuning the CogLM on the MS-COCO dataset achieves greatly improved performance on the FID metric, and that the resulting CogView2 text-to-image system can generate images with better quality and similar resolutions 10x faster than CogView and obtain results competitive with current state-of-the-art DALL-E-2 baselines.
Overall, the study successfully leverages hierarchical transformers to enable autoregressive text-to-image models to overcome slow generation and high complexity issues and narrow the gap between text-to-image pretraining and vision transformers.
Codes and a demo website will be updated on the project’s GitHub. The paper CogView2: Faster and Better Text-to-Image Generation via Hierarchical Transformers is on arXiv.
Author: Hecate He | Editor: Michael Sarazen

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.