
Translation or Answering tool: seq2seq with teacher forcing and attention mechanism
Just finished building an NLP chatbot with deep learning model using encoder-decoder architecture with attention vector along with teacher forcing. I have to used Keras with Tensorflow back-end and PyTorch for this. I have used MOOCs from Udemy & Coursera in figuring out the models as well as tutorials from PyTorch. I am writing this blog as a way of solidifying my understanding of NLP translation/answer creation.

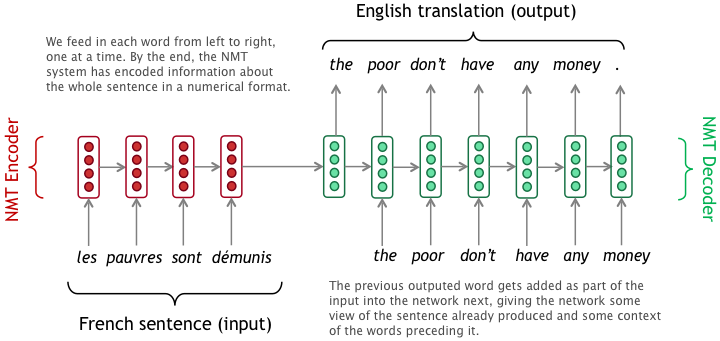
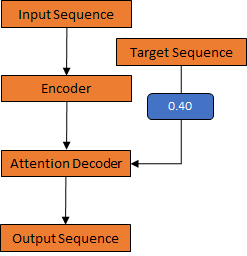
The basic methodology is to create an encoder and decoder neural network system to get the expected output.

In order to do this, we have to preprocess the data of input and output into pairs, create word index dictionaries, create the neural networks, create attention mechanism, enable teacher forcing during model training to reduce it from learning errors etc. We will cover all of these steps below.
Preprocessing
Importing libraries and the historical chat files. The chats were formatted as pairs of questions and replies in 2 columns(‘col1’ and ‘col2’).
Pre-processing the data into input and output pairs is to be done as follows.
- Normalize NFD to change canonical characters to regular characters
- Convert the string to lowercase and remove any non-letter characters
- Create input-output pairs list
Now create pairs list function with class and add the words to dictionary for indexing. This dictionary index will be utilized for encoding input and decoding output for the neural networks that we will be utilizing.
Creating the neural networks
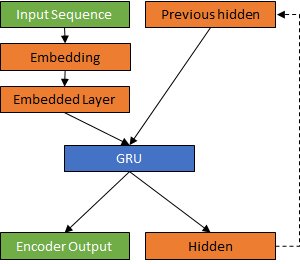
From the hyperlink, I am going to use PyTorch tutorial for creating the encoder and decoder systems. The following is a Gated Recurrent Unit (GRU) encoder.
Encoder
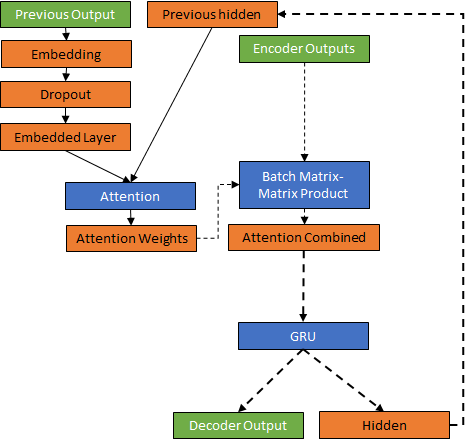
Attention decoder
Then we create a decoder neural network system with GRU and attention mechanism. Attention allows the decoder network to “focus” on a different part of the encoder’s outputs for every step of the decoder’s own outputs. First we calculate a set of attention weights. These will be multiplied by the encoder output vectors to create a weighted combination.

The result (called attn_applied in the code) should contain information about that specific part of the input sequence, and thus help the decoder choose the right output words. For every step the decoder can select a different part of the target sentence to consider based on previous hidden state. Here we use attention weights as a softmax function by concatenating encoder output and hidden layer from previous iteration. Multiple strategies for combining exists (concatenation, dot product and sum) and has to be experimented.
The following is a picture I obtained from a MOOC about application of attention operation weights in a decoder. Please note that here, they are using LSTM instead of GRU. Attention mechanism is especially useful in language translation where the second word in a language-1 sentence might appear at the end in the language-2 sentence. Attention mechanism helps point to the right part of the sequence for each of the input words.
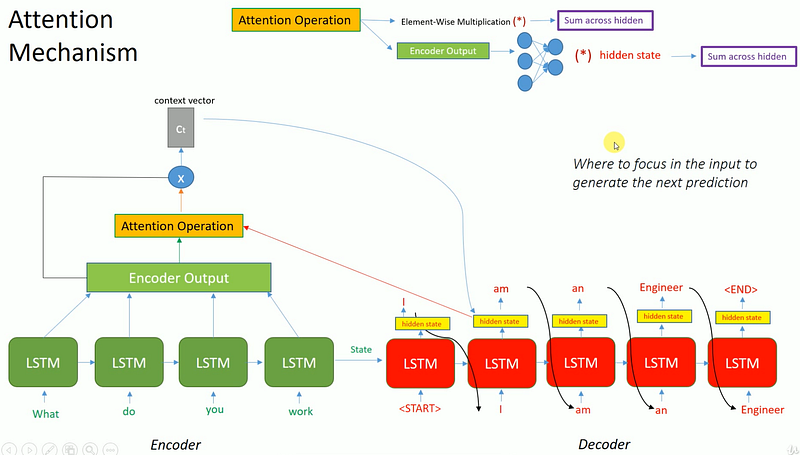
Attention mechanism — Normally attention is a linear layer that takes input from both embedded output from encoder
Preparing and training Data
Now we create functions to prepare the training data including:
- Creating input & output tensors from the list and creating basic functions to track time & plot loss graphs while training
- Train-iteration function which calls the optimizers for encoder & decoder, loss function
- Train function with teacher forcing to run encoder training, get the output from encoder to decoder and train the decoder, backward propagation
- Evaluation function to evaluate actual output string and predicted output string
1. Creating input & output tensors from the list and creating basic functions to track time & plot loss graphs while training
2. Train-iteration function which calls the optimizers for encoder & decoder and loss function
In the following code, we are using SGD optimizer. We could also use other optimizers such as Adam, ASGD, LBFGS, RMSProp etc.
3. Train function with teacher forcing to run encoder training, get the output from encoder to decoder and train the decoder, backward propagation
3. Train function with teacher forcing to run encoder training, get the output from encoder to decoder and train the decoder, backward propagation
4. Evaluation function to evaluate actual output string and predicted output string
Finally…
We call the functions to train the models.
After training, we can enter a new string with function evaluateAndShowAttention(“Trial_String…”) to get the output.
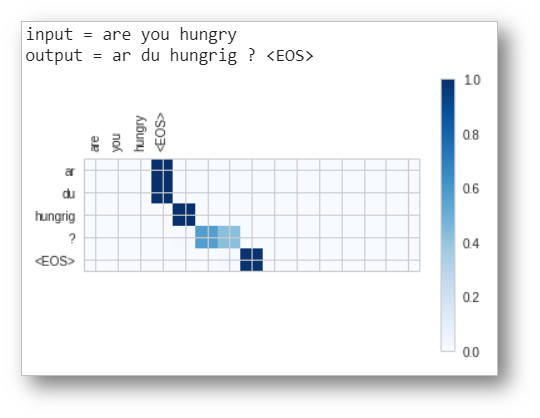
With a single GRU layer in encoder & decoder, teacher forcing and hidden size of 256, we get a marginally good model.
Future experiments:
- We can experiment with attention models of dot product and sum of encoder output & hidden layer output from the GRU.
- More GRU layers
- More hidden states
- Adding Spatial 1-D dropouts between layers
- Hyper-parameter tuning
- Use the same architecture to create answering tools and chatbots with different datasets
- Experiment with BERT pretrained model from Google
Let me know what you think! I have used a lot of PyTorch tutorials, GitHub repos, MOOCs and blogs to put together this article. Please feel free to comment and advise me on better ways to run these models.
Reference
- https://pytorch.org/tutorials/beginner/chatbot_tutorial.html
- https://pytorch.org/tutorials/intermediate/seq2seq_translation_tutorial.html
- https://machinelearningmastery.com/encoder-decoder-recurrent-neural-network-models-neural-machine-translation/
- https://towardsdatascience.com/understanding-gru-networks-2ef37df6c9be
- https://www.udemy.com/applied-deep-learning-build-a-chatbot-theory-application/