
Transformers from Scratch: Part 1
Key Concepts, Self-Attention, Multi-Head Attention

Attention is a mechanism that allows neural networks to focus on different parts of the input sequence when processing information. It is a crucial component of the transformer architecture, enabling the model to capture the sequence's dependencies and relationships between different elements. For text sequences, the elements are token embeddings.
In a transformer model, attention is computed through the self-attention mechanism.
Disclaimer: I’m purposely not touching masks as this is only relevant for the decoder part of the Transformer, which is going to be tackled in Part 2. My main goal here is to explain the basics of the attention mechanism.
But let's start with first things first…
Query, Key, and Value Vectors
In the context of attention mechanisms, each element in the input sequence is associated with a query, key, and value vector.
Imagine you’re attending a conference where multiple speakers give presentations. Each presentation corresponds to a token in the input sequence. Now, let’s break down the key, query, and value in this context:
- Key: The key represents the content or context of each presentation. It captures the main ideas, themes, or relevant information associated with each talk. Think of the key as a summary or representation of the key points of each presentation.
- Query: The query represents the specific topic or question you’re interested in or want to focus on during the conference. It could be a specific area of interest or a particular subject you’re curious about. The query reflects your current context or the aspect you want to explore further.
- Value: The value contains the detailed information, insights, or knowledge provided by each speaker during their presentation. It encompasses all the valuable content of each talk, including facts, examples, explanations, and ideas.
Hold on to this example as we explore the attention mechanism.
Self-Attention
The self-attention mechanism calculates attention weights that indicate the relevance of each element with respect to the other elements within the same sequence. These weights indicate the degree of attention that should be given to each element. They are typically computed based on the similarity between the query, key, and value vectors associated with each element.
The term “self” in self-attention emphasizes that attention is computed within the same sequence, without considering any external context or other sequences. It highlights the capability of the self-attention mechanism to capture dependencies and relationships between elements within the input sequence itself.
In the scenario previously described, the attention mechanism allows you to attend to relevant presentations and extract valuable information based on your query. The key vectors help determine which presentations are most relevant to your query, while the query vector represents your specific area of interest or focus. The value vectors contain the detailed content of each presentation.
The model identifies the most important presentations that align with your interests by calculating attention weights between the query and the keys. It then combines the values of these selected presentations using the attention weights, effectively capturing the relevant information from each presentation based on your query.
Scaled Dot-Product Attention
The scaled dot-product attention is the most common way to implement a self-attention layer. It computes the attention weights between a query vector and a set of key-value pairs by calculating the dot product similarity between them. The key idea behind the scaled dot-product attention is to scale the dot products by the square root of the dimensionality of the query and key vectors, which helps stabilize the gradients during training.
The computation of the scaled dot-product attention can be summarized by the following steps:
- Project each token embedding, with dimension dₘ, into three vectors: query vector
Q, and a set of key vectorsK, both with dimensions dₖ and value vectorsVwith dimension dᵥ. - Compute the attention scores using the dot product similarity. The dot product between the query vector
Qand the key vectorsK^Tfor a sequence with dₖ input tokens will yield a similarity matrix of dimensions dₖ × dₖ. - Scale the similarity matrix by dividing it by the square root of the dimensionality of the query/key vectors. This scaling ensures that the dot product values are not too large and helps prevent gradient explosion during training.
- Compute attention weights
w. Apply the softmax function to the scaled similarity matrix. The resulting attention weights represent the importance of each key with respect to each query. - Update the token embeddings. Multiply the attention weights
wby the value vectorsVto obtain a weighted sum of the values. The output is a weighted representation of the values based on the attention weights.

This can be translated into the following equation:

These steps can be implemented in Python with the following code:
import torch
import torch.nn.functional as F
from math import sqrt
def scaled_dot_product_attention(query, key, value):
"""
Simplified scaled dot product attention.
"""
d_k = query.size(-1)
scores = torch.bmm(query, key.transpose(1, 2)) / sqrt(d_k)
weights = F.softmax(scores, dim=-1)
return torch.bmm(weights, value) To have a glimpse of how the attention weights are calculated, we can use the BertViz library, specifically the neuronview module:
from bertviz.transformers_neuron_view import BertModel, BertTokenizer
from bertviz.neuron_view import show
model_ckpt = "bert-base-uncased"
model = BertModel.from_pretrained(model_ckpt, output_attentions=True)
tokenizer = BertTokenizer.from_pretrained(model_ckpt, do_lower_case=True)
text = "The quick brown fox jumps over the lazy dog"
show(model, "bert", tokenizer, text, display_mode="light", layer=0, head=8)This visualization depicts the query vector, key vectors, and their product as vertical bands. The color intensity of the bands indicates their magnitude, while the hue represents their sign (blue for positive, orange for negative). The thickness of the connections between the lines is weighted based on the attention between the tokens.
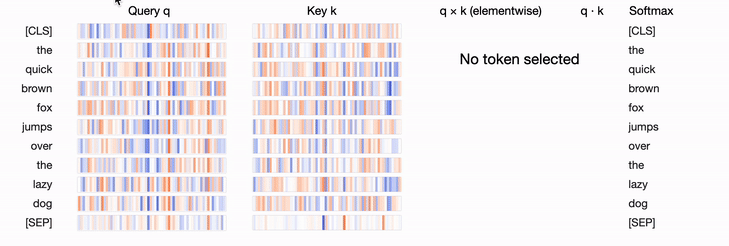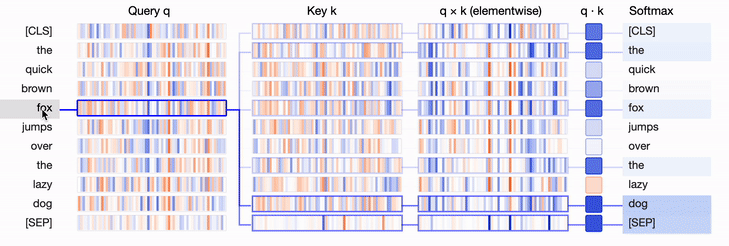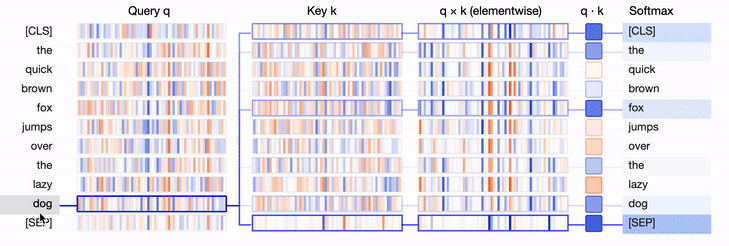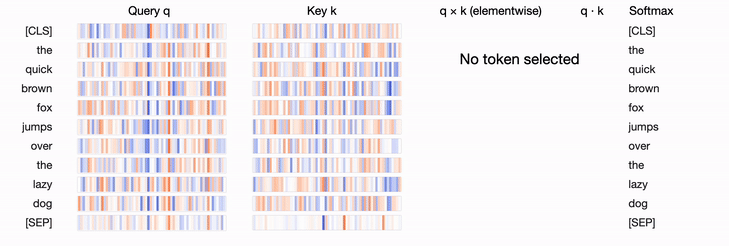
For more on visualizing attention in Transformers, I'd recommend checking this great article:
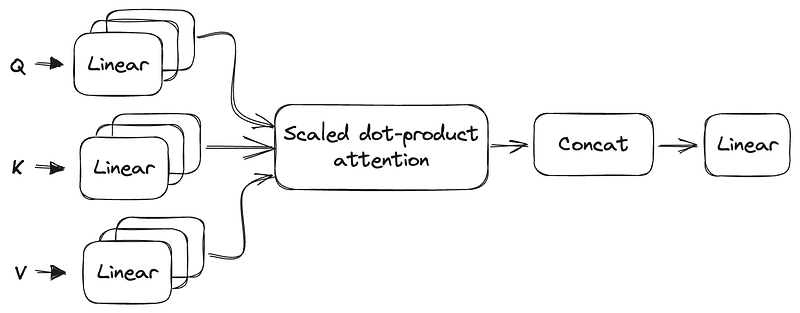
Multi-Head Attention
The multi-head attention is an extension of the self-attention mechanism. It enhances the modeling capability by performing multiple attention computations in parallel, with different learned linear projections.
The reasoning for heaving multi-head attention is that the softmax of one head usually focuses on mostly a single aspect of similarity. In other words, the multi-head attention allows the model to capture different types of dependencies and relationships between the elements in the input sequence. I.e., each headᵢ ∈ h can attend to different parts of the sequence, enabling the model to learn more nuanced patterns.
This can be translated to the following equation:

where:

Where the projections are parameter matrices such as:

As can be seen, each attention head has its own set of learnable parameters. They perform computations on the input sequence and produce different representations. A single attention head can be implemented in Python as the following:
from torch import nn
class AttentionHead(nn.Module):
"""
Self-attention head.
Args:
embed_dim: embedding dimension.
head_dim: number of dimensions we are projecting into.
"""
def __init__(self, embed_dim, head_dim, mask=None):
super().__init__()
self.q = nn.Linear(embed_dim, head_dim)
self.k = nn.Linear(embed_dim, head_dim)
self.v = nn.Linear(embed_dim, head_dim)
def forward(self, hidden_state):
attn_outputs = scaled_dot_product_attention(
self.q(hidden_state), self.k(hidden_state), self.v(hidden_state))
return attn_outputs The AttentionHead class has three linear layers: self.q, self.k, and self.v. These layers perform linear projections of the initial input hidden_state to obtain the Q, K, and V vectors, respectively. The nn.Linear(embed_dim, head_dim) statements create these linear layers, where embed_dim represents the embedding dimension of the input and head_dim represents the number of dimensions the projections are reduced to.
The linear layers self.q, self.k, and self.v in the AttentionHead class use learnable weight matrices to perform the projections. These weight matrices are automatically learned during training. Additionally, the forward method in the AttentionHead class applies the scaled dot-product attention mechanism using the scaled_dot_product_attention function. It takes the linearly projected versions of Q, K, and V as inputs and produces the attention outputs (attn_outputs), which are then returned.
From that, the output of multiple attention heads can be concatenated to define a multi-head attention layer:
import torch
from torch import nn
class MultiHeadAttention(nn.Module):
"""
Multi-head attention.
Args:
config: multi-head attention configuration.
"""
def __init__(self, config, mask=None):
super().__init__()
embed_dim = config.hidden_size
num_heads = config.num_attention_heads
head_dim = embed_dim // num_heads
self.heads = nn.ModuleList(
[AttentionHead(embed_dim, head_dim) for _ in range(num_heads)]
)
self.output_linear = nn.Linear(embed_dim, embed_dim)
def forward(self, hidden_state):
"""
Concatenate the outputs of each self-attention layer.
"""
x = torch.cat([h(hidden_state) for h in self.heads], dim=-1)
x = self.output_linear(x)
return x The head_dim parameter represents the number of dimensions to which the input embeddings are projected within each attention head. Determining the appropriate value for head_dim depends on factors such as the size of the input embeddings and the desired level of granularity in capturing relationships and dependencies.
In practice, the head_dim is often chosen as a fraction or multiple of the embedding dimension (embed_dim). By using a multiple of embed_dim, the computation across each attention head can be more efficient.
We can once again use BertViz library, specifically the head_view module, to visualize the attention for one or more attention heads in the same layer.
from transformers import AutoModel, AutoTokenizer
model_ckpt = "bert-base-uncased"
model = AutoModel.from_pretrained(model_ckpt, output_attentions=True)
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
sentence_a = "The quick brown fox jumps over the lazy dog"
sentence_b = "How quickly daft jumping zebras vex!"
viz_inputs = tokenizer(sentence_a, sentence_b, return_tensors='pt')
attention = model(**viz_inputs).attentions
sentence_b_start = (viz_inputs.token_type_ids == 0).sum(dim=1)
tokens = tokenizer.convert_ids_to_tokens(viz_inputs.input_ids[0])
head_view(attention, tokens, sentence_b_start, heads=[8])
References
General Knowledge
All sentences used here are pangrams. Pangrams are sentences or phrases that contain every letter of the alphabet at least once. They are often used as a typing exercise or as a test to check the functionality of fonts or keyboards.

This story is published on Generative AI. Connect with us on LinkedIn to get the latest AI stories and insights right in your feed. Let’s shape the future of AI together!
