
Transformer Models For Custom Text Classification Through Fine-Tuning
A tutorial on how to build a spam classifier (or any other classifier) by fine-tuning the DistilBERT model
The DistiBERT model was released by the folks at Hugging Face, as a cheaper, faster alternative to large transformer models like BERT. It was originally introduced in a blog post. The way this model works — is by using a teacher-student training approach, where the “student” model is a smaller version of the teacher model. Then, instead of training the student on the ultimate target outputs (basically one-hot encodings of the label class), the model is trained on the softmax outputs of the original “teacher model”. This is a brilliantly simple idea, and the authors show that:
“it is possible to reduce the size of a BERT model by 40%, while retaining 97% of its language understanding capabilities and being 60% faster.”
Loading and Preprocessing the Data For Classification
In this example, I use the SMS spam collection dataset in the UCI Machine Learning Repository and build a classifier that detects SPAM vs HAM (not SPAM). The data contains 5,574 rows of SMS texts that are labeled as SPAM or HAM.
First, I make train and validation files from the original csv and use the load_dataset function from the Hugging Face datasets library.
from datasets import load_dataset
import pandas as pd
df=pd.read_csv(‘/content/spam.csv’, encoding = “ISO-8859–1”)
df=df[['v1','v2']]
df.columns=['label','text']
df.loc[df['label']=='ham','label']=0
df.loc[df['label']=='spam','label']=1
df2[:4179].reset_index(drop=True).to_csv('df_train.csv',index=False)
df2[4179:].reset_index(drop=True).to_csv('df_test.csv',index=False)
dataset = load_dataset('csv', data_files={'train': '/content/df_train.csv',
'test': '/content/df_test.csv'})The next step is to load in the DistilBERT tokenizer to preprocess the text data.
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(“distilbert-base-uncased”)
def preprocess_function(examples):
return tokenizer(examples["text"], truncation=True,padding=True)
tokenized_data = dataset.map(preprocess_function, batched=True)
from transformers import DataCollatorWithPadding
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)Training the model
Prior to training, you need to map IDs to labels. After this, you need to specify the training hyperparameters, call trainer.train() to begin fine-tuning, and push the trained model to the Hugging Face hub using trainer.push_to_hub().
id2label = {0: “HAM”, 1: “SPAM”}
label2id = {“HAM”: 0, “SPAM”: 1}
from transformers import AutoModelForSequenceClassification, TrainingArguments, Trainer
model = AutoModelForSequenceClassification.from_pretrained(
"distilbert-base-uncased", num_labels=2, id2label=id2label, label2id=label2id
training_args = TrainingArguments(
output_dir="spam-classifier",
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=5,
weight_decay=0.01,
evaluation_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
push_to_hub=True,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_data["train"],
eval_dataset=tokenized_data["test"],
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
)
trainer.train()
trainer.push_to_hub()That’s it! As you can see from the Hugging Face hub, the model accuracy is pretty good (0.9885)!
Model Inference
Inference is also relatively straightforward. You can see the output through running python scripts as below:
text = “Email AlertFrom: Ash Kopatz. Click here to get a free prescription refill!”
from transformers import pipeline
classifier = pipeline("sentiment-analysis", model="skandavivek2/spam-classifier")
classifier(text)
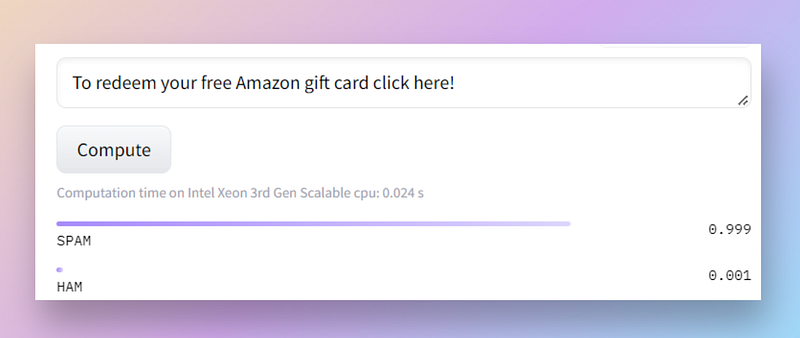
Or run on the Hugging Face hub:
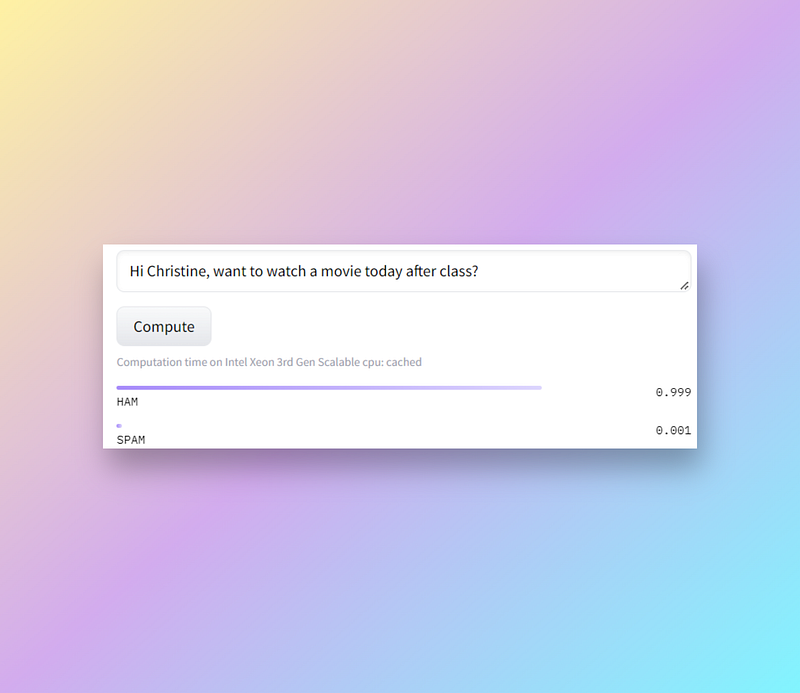
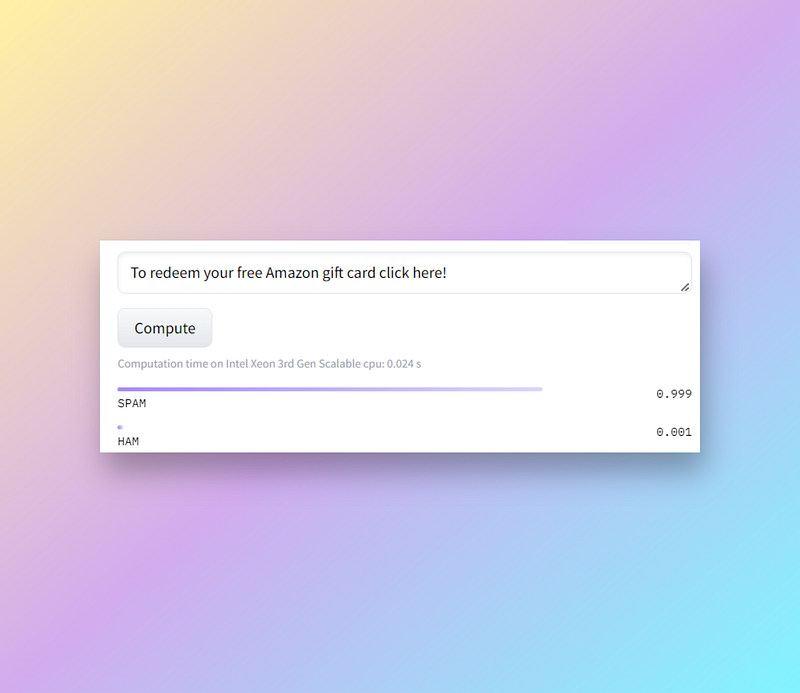
Takeaways
And that’s it! Hugging Face makes it very easy and accessible to adapt state of the art transformer models to custom language tasks as long as you have the data!
Here is the GitHub link to the code:
If you liked this blog, check out my other blog on fine-tuning Transformers for Question Answering!
References:
- https://www.kaggle.com/datasets/uciml/sms-spam-collection-dataset
- Dua, D. and Graff, C. (2019). UCI Machine Learning Repository [http://archive.ics.uci.edu/ml]. Irvine, CA: University of California, School of Information and Computer Science.
- Almeida, T.A., Gómez Hidalgo, J.M., Yamakami, A. Contributions to the Study of SMS Spam Filtering: New Collection and Results. Proceedings of the 2011 ACM Symposium on Document Engineering (DOCENG’11), Mountain View, CA, USA, 2011.
- https://huggingface.co/docs/transformers/training
If you are not yet a Medium member and want to support writers like me, feel free to sign-up through my referral link: https://skanda-vivek.medium.com/membership
For weekly data-based perspectives subscribe here!





