
Training DeepRacer for Speed
AWS DeepRacer is a 1/18th scale autonomous race car. It uses a camera (and LIDAR sensor on the newer version) as input to determine how fast the car should run and how steep should the turn be. We can use reinforcement learning to train a model in a simulated virtual world and load the model into the real car to test it.
Reinforcement learning
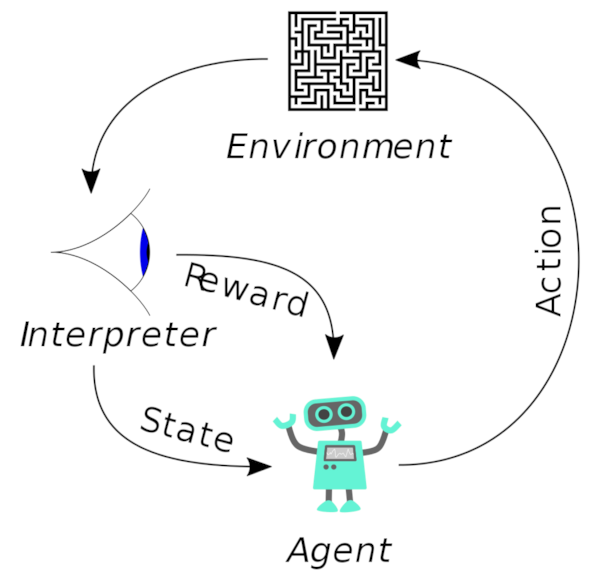
Reinforcement learning is one of the machine learning paradigms. The idea is that an agent observes the environment and take action. We, as the developer can write a function to give the agent rewards on that action. The agent then learns how to get the most reward in a given state.
Think of it as playing video games. At first, you don’t know how to play, so you just randomly clicking the buttons. However, after several tries, you can observe that in a specific scenario, you can do particular action to grab more score.
The difficulty in writing reward function
The main difference between reinforcement learning and supervised learning is the goal we want to achieve spread across a chain of actions.
Use DeepRacer as an example. Our goal is to finish the lap as quickly as possible. However, we cannot merely give out reward based on the finishing time because the car can’t even finish a lap at first. Instead, we need to give out some reward to incentivise the car to keep itself inside the track until it finally finishes a lap.
But just like when we are playing GTA, if the side mission (keeping the car inside the track) is too attractive, we may quickly forget the primary mission (finishing the lap).
In DeepRacer training, the reward is continuously given by the function every 1/15 second. If the model wants to get as many rewards as it can, it just stays on the track as long as it can. However, our goal is to finish the lap as quickly as possible.
Thus, matching the model’s goal and our goal is very important when writing the reward function.
My reward functions
1. Penalise slow speed
To prevent the model from running slowly on the track, I use the following code to penalise slow speed
In theory, if the car half its speed, the step it can run within a certain distance and the reward is doubled. We can compensate it by giving half the reward on each step.
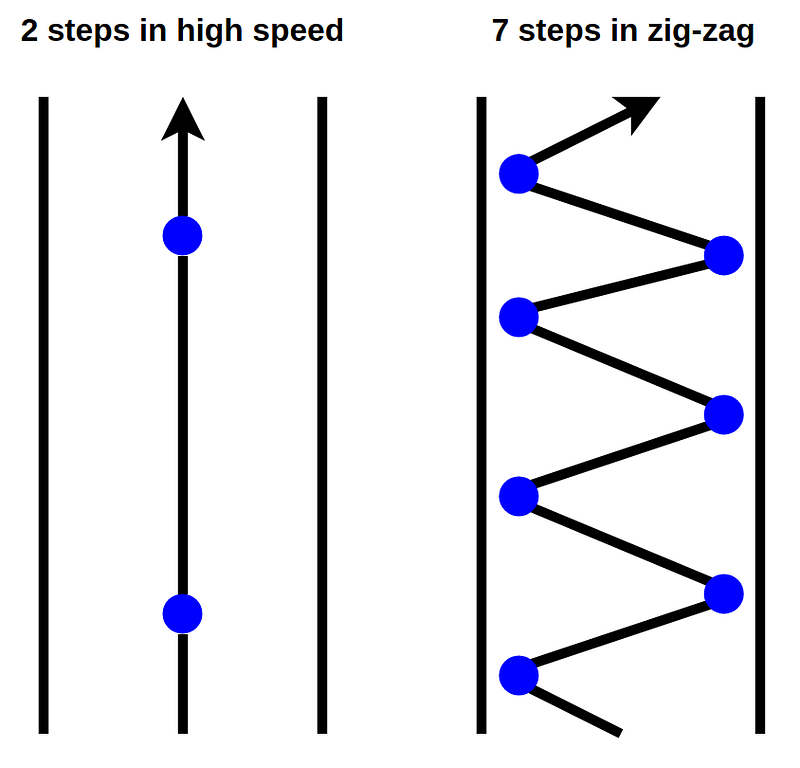
However, I found that in slow speed, the car may perform zig-zag and make the path longer. So in my reward function, I penalise slow speed even further by applying a square on the speed rate.
It doesn’t solve the problem completely. Let’s see how my model performs the hairpin turn in March racing:
Instead of slowing down and using the inner lane to make a turn, my model chooses to keep its speed and use the outer lane. The reason is that my reward function is discouraging it to run slowly.
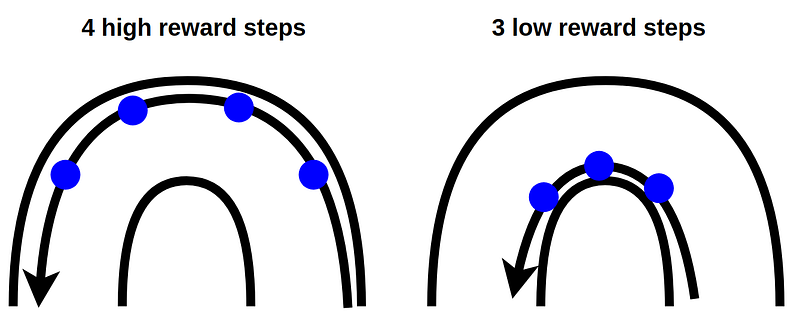
By running fast on the outer lane, the model can perform 4 steps with higher reward (higher speed has higher reward). If it chooses to slow down and use the inner lane, it can only perform 3 steps and get a lower reward from those steps.
2. Rewarding based on progress
Another idea I came up with is to let the model knows what I exactly want. So I have also implemented the following reward function:
If the model can use fewer step (time) to run more progress (percentage of the lap completed), it gets more reward. My thought is that it may eventually find out how to finish the lap fast, but that’s not the case.

Let’s look at this picture. You may think the man I pointed at is slow as he is trailing behind.
But if you watch the video, you can see he wins the race. The reason he was trailing behind is that his teammate runs slowly.
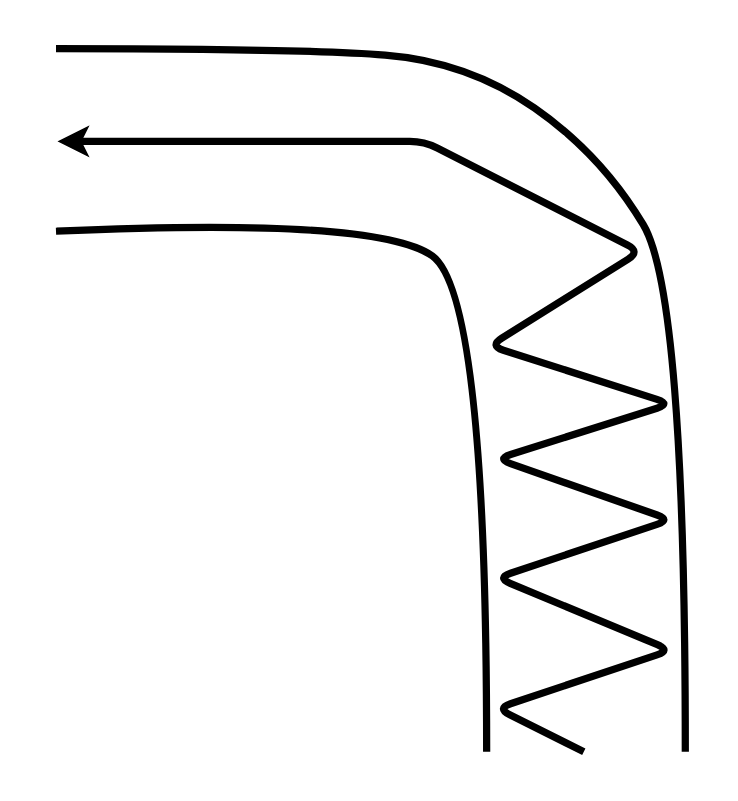
The same thing also happens in my reward function.
Imagine if the model performs zig-zag at first, which I don’t want it to do. And after the turn, it maxes its throttle and goes straight forward.
I should reward the model for its straight run. But because it started badly before the turn, it is already trailing behind after the turn, so my reward function gives it a bad score instead. Just like when we look at the picture, we think the man is running slow.
My model may think “Why I am getting such a low score? Am I running too fast? Am I doing things wrong?” Without knowledge of past actions, the model can’t judge how good is the current action.
Combining 2 methods
What I mean is not combining 2 methods into a single reward function, it only confuses the model. Instead, I am using those 2 reward function alternatively.
First, I use the first reward function to encourage the model to use faster speed. In the beginning, I didn’t apply square on the speed rate to avoid the model from overspeeding and run out of the track.
After the model can run a full lap, I started applying square on the speed rate to encourage the model to run faster. And at some point, I switch to use the second reward function to let the model find a better way to finish a lap faster.
Monitoring the progress
How to decide when to switch the reward function?
As I said, matching the model’s goal and our goal is essential. So I’ve plotted a chart to track if these two match: 1) Total reward 2) Progress per step
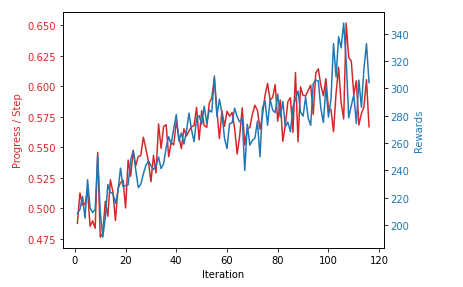
In this image, we can see that the reward is going up along with the progress per step. That means the model is learning to get more reward and running fast at the same time. We can keep the training going.
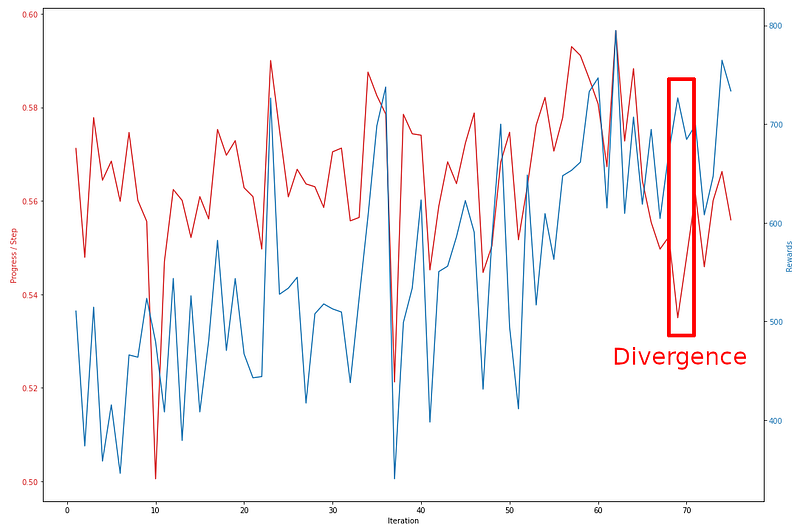
However, these 2 metrics do not always match.
In this image, we can see there is little or even no correlation between two. We can even see a divergence in one training iteration (One goes up, and the other goes down).
One of the reason is that I was using progress per step in the reward function. And for some reason, the model lost its way and started to go off track, making it fail to finish a complete lap. In this case, I stopped the training and switched to use the first reward function and guide the model to complete a lap again.
Afterthought
Although my model is doing well after I used those methods to train. But I still can’t find a one-off method to train the model fast. One of the reason is that DeepRacer uses Markov decision process (MDP). The idea of MDP is that every decision is made only by the current state; no previous experiences are involved.
But as a human, we know that racing is a continuous process; every previous action can affect the next action we decide to take. For example, if the car starts to drift uncontrollably, the driver may try to slow down the car. But without this knowledge, our model may decide to speed up only because it sees a straight track ahead.
CNN vs RNN
DeepRacer uses Convolutional neural network (CNN) to construct the model which is good at analysing patterns across space, like images. In DeepRacer, the input is images taken by the front camera, and it makes sense to use CNN.
However, racing is a continuous process, analysing patterns across time is also essential, and this is what Recurrent neural network (RNN) good at.
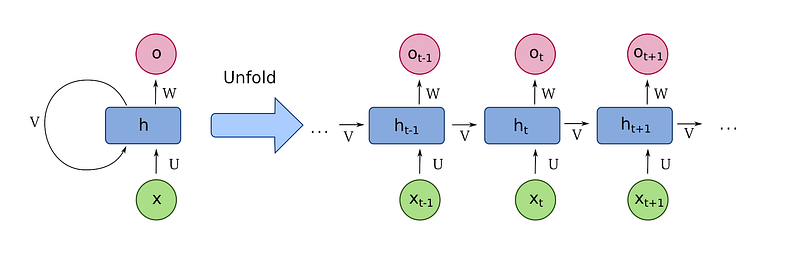
Unlike CNN, outputs in RNN are passed to the next step as its input, so the model can understand what actions it has taken before, and learn how they impact its decision.
By combining RNN into DeepRacer, maybe we can explore some new training method to make our model more intelligent.
DeepRacer uses RL Coach framework and it supports LSTM (a commonly used RNN architecture) as middleware. As I have so much time staying at home now, I will give it a try and see what happens.
Although I have so little knowledge to say if my idea works, DeepRacer still opens the door for me to discover the world of machine learning. And that’s what DeepRacer intended to achieve.
If you haven’t started playing DeepRacer yet, join now and you may have the opportunity to win a trip to AWS re:Invent. Also, we have a Slack channel consist of many great DeepRacer participants, feel free to join and say hello to me!





