
Machine Learning Art
Tracking people and objects in videos
The new TDT-tracker — real-time tracking data

In computer vision, tracking people and objects is a critical job at the heart of many applications. Several sub-tasks must be completed to accomplish tracking. For example, object identification and data association need the system to recognize (possibly numerous) things of interest in the video and relate these objects’ positions as they move across the video. Many techniques to tackle the tracking problem have been explored and are still being proposed. One-stage trackers, which utilize a joint model to forecast both detections and appearance embeddings in a single forward pass, have recently gained a lot of attention and have attained state-of-the-art results on the MOT benchmarks.
- May 2022 — AI art tools update can be found ➡️ HERE ⬅️
One-Stage Approach
However, their performance is contingent on the availability of properly annotated movies with tracking data, which is costly and difficult to come by. This may limit the model’s ability to generalize. The two-stage strategy, which separates detection and embedding, is slower but easier to train since the data is easier to annotate. The authors suggest using a data distillation strategy to integrate the best of both worlds. To produce pseudo appearance embedding labels for the detection datasets, they employ a teacher embedder trained on Re-ID datasets. The enlarged dataset is then used to train a detector that can completely convolutionally regress these pseudo-embeddings. The proposed one-stage approach has the same quality as the two-stage equivalent but is three times quicker. Despite the fact that the instructor embedder has never seen any tracking data during training, the new tracker outperforms certain popular trackers (e.g. JDE) that have been trained with fully labeled tracking data.
Project Page (scroll down)
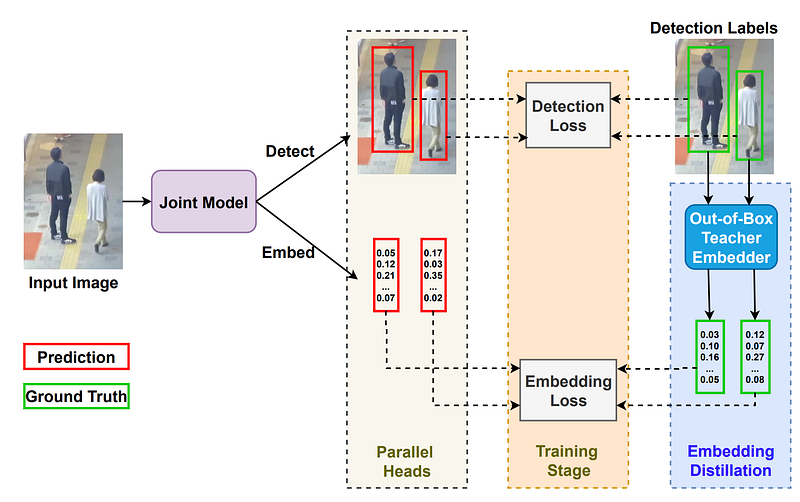
TDT-tracker
The proposed one-stage tracking framework’s training step, with only detection boxes as labels. Through a data distillation strategy, the augmented detection example (top right picture) with pseudo ground-truth embeddings (represented as the embedding vector in green) was achieved. The cropped picture patches (green bounding boxes) are fed through a teacher embedder to produce these embeddings (a pre-trained out-of-box Re-ID network). A joint model takes an input picture and recognizes items of interest (red bounding boxes) while also generating an embedding (red embedding) for each object. Both predictions are supervised using the additional dataset. Different detectors and instructor embedders may be utilized with this system because it is so adaptable.
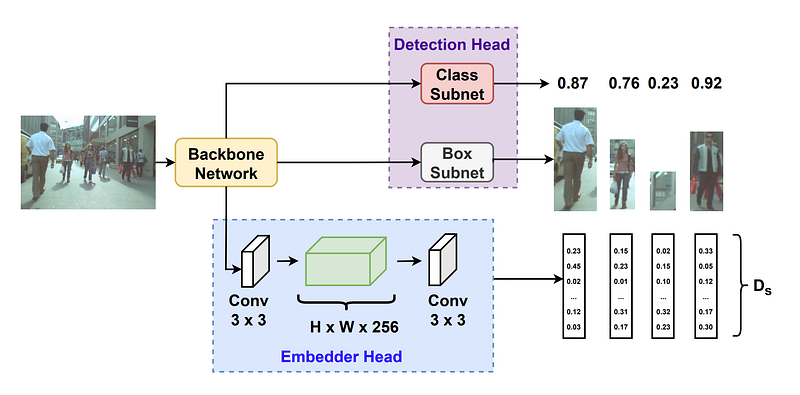
Adapted from RetinaNet, the proposed joint model.
The newly added embedder head is parallel to the detection head and consists of only two convolutional layers. (Above) The backbone network extracts multi-level information from an input picture, which are simultaneously fed into the three sub-networks. The bounding boxes containing the items of interest are predicted by the box subnet. For each projected bounding box, the class sub-net computes a confidence score for each class. The embedder head creates an embedding for each bounding box, which represents the object’s distinguishing traits.
TDT-tracker versus two-stage tracker
The authors suggest a straightforward yet effective embedding distillation approach to address the issue of costly and limited fully annotated real-time tracking data. The new TDT-tracker delivers competitive performance on benchmark datasets, and they examine several features of our approach. Particularly. With better embedders, the tracker obtains better results. In addition, better Re-ID networks are actively being developed, which immediately enhances the one-stage tracker. Thus I feel it’s a good path.
Title : TDT: Teaching Detectors to Track without Fully Annotated Videos
The Authors: Shuzhi Yu Guanhang Wu Chunhui Gu Mohammed E. Fathy Duke University Google LLC
Project Page:
https://arxiv.org/pdf/2205.05583.pdf
Keywords: computer vision, Artificial Intelligence, datasets, Machine Learning, AI art, art, digital art, Tracking people, video, object identification, Detectors, trackers
I invite you to explore the concept of “AI creativity” by reading and learning from the many articles found on 🔵 MLearning.ai 🟠
- Check out my instagram with new material every week
- If you enjoyed this, follow me on Medium for more
- Want to collaborate? Let’s connect on LinkedIn
- https://linktr.ee/datasculptor
- 3D Machine Learning generated model on sketchfab
Data Scientists must think like an artist when finding a solution when creating a piece of code. Artists enjoy working on interesting problems, even if there is no obvious answer.
All our writers (members) receive the opportunity to be promoted on our social media, which increases the popularity of articles published on MLearning.ai