
Towards Understanding Large Language Models: Fine-Tuning
Fine-Tuning LLMs to shape your own GenAI tools — Part of a Series
Introduction
Large language models, or LLMs, are undoubtedly the stars of 2023. Since then, it has taken on an incredible pace. Chat GPT, Character.ai, Bard, etc.—all these tools that are a few months old are powered by these models. They are becoming part of our day-to-day lives, and it is not pacing down. Today, the exciting path lies in your ability to create tools tailored to your needs.
How, you might ask?
Well, one particular great thing about computer science and data science is the open source community—some amazing and selfless people that are developing and building great things for everyone to use. LLMs, as part of that, have their own community that is continuously developing and sharing open-source algorithms and models. To name a few recent examples: Phi2 from Microsoft or Mixtral 8x7b.
These open-source models allow you to build tools that meet your needs without starting from scratch.
The purpose of this article will be to explore and explain the technique enabling that, also known as fine-tuning. At the end of this article, you should be able to understand what this technique is, specifically what it means for LLMs, and how it unravels. Therefore, the answer to:
How can you bend any large language model to your will ?
A first step toward understanding fine-tuning is to understand what a pre-trained model is.
Pre-trained Model
As we mentioned in the introduction, today there are many LLM models available. A pre-trained model is one that has been trained on a large dataset for a specific task.

The purpose of this is to use the knowledge gathered during this training to ease the learning process for other tasks. It may not seem obvious, but it is achievable, and it is inspired by how the human brain learns.
Let’s explore this analogy!
Human Analogy
Imagine a young person “training” to write (learning how to write); after watching his teacher or his parents do it (labeled data set) and trying on his own (training phase), he understands how to hold a pen and how to make it work on a piece of paper. Now he wants to draw. He will know how to hold the pencils and how to move them on the paper. Obviously, he doesn’t know how to draw, and he knows it’s not letters or punctuation, so he’ll start to scribble. The idea I am trying to illustrate is that he didn’t start drawing from scratch, but his brain transferred his writing knowledge to his new discovery.
So for LLM, this knowledge is stored or embedded in what is commonly known as parameters.
Now that this is clearer, let's dive into the star of the show !
Fine-tuning: Bending LLMs to our will
What is fine-tuning for LLMs, and why do we need it?
What is fine-tuning?
Technically speaking, fine-tuning is taking a pre-trained model and training either a set* or all of its parameters on a new set of data. For LLMs, it allows you to take a general-purpose or base model and update its parameters to carry out a particular task.
What is its purpose?
The main purpose is to improve the performance of the base model on one specific task and outperform it Fine-tuning is really good at fulfilling its purpose; even more so, it achieves it while optimizing scales (parameter-wise or data-wise).
Fine-tuning efficiency examples
- Parameter reduction: it enables a small model to outperform a much bigger one. Open AI showed how the InstructGPT¹ model with a 1.3B parameter provided better outputs than the GPT3.5 model with a 175B parameter despite having 100x fewer parameters.
- Data optimization: on another scale, It enabled LIMA², a 65B parameter LaMA model fine-tuned using 1,000 carefully curated prompts and responses to outperforms GPT3.5, another 65B parameter model
Fine-tuning: how does it work ?
Now that we have covered the definition and the purpose, let’s see how it is done!
There are three techniques to fine-tune a pre-trained model :
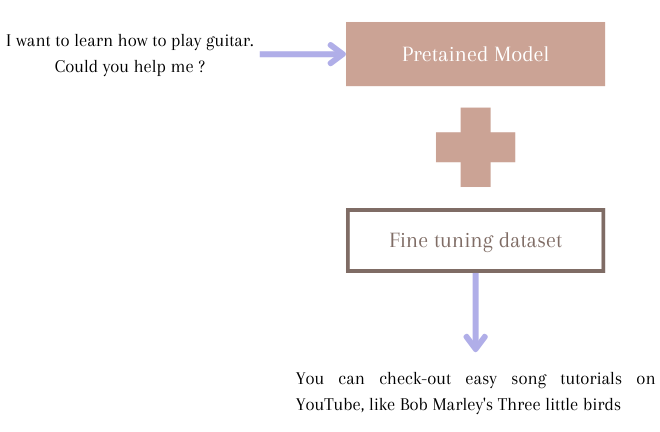
SFT : Supervised fine-tuning
It’s a common technique. It relies on carefully selected data that accurately represents the tasks to train the model. These data can be Input-output pairs or triplets Input-instructions-output. Instructions are incorporated in the parameter to better guide the model regarding the task targeted
This process allows the model to grasp patterns from the provided dataset, therefore optimizing its parameters to perform effectively on the targeted task. One example of application is responding to human prompts
RLHF: Reinforcement Learning from human feedback
This technique is based on two elements: a reward model based on human preferences and an agent-based optimization algorithm like Proximal Policy Optimization (PPO). For clarity, an agent-based optimization algorithm trains an “agent” to explore possibilities and make choices.
The reward model helps the agent judge what is a good or bad possibility. Therefore, the aim of RLHF is to maximize rewards through PPO to capture human preferences. It can be tricky as it involves interaction with the environment, a careful reward system design, and consistent human feedback.
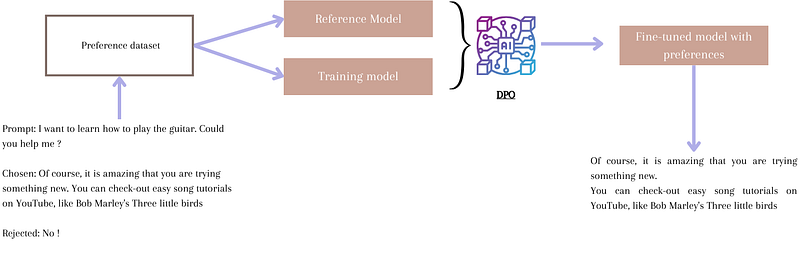
SFT with a preference learning³
I am going to dive a bit more into this one because it is particularly interesting. Thanks to it, it has been possible to leverage SFT's (relative) simplicity and RLHF's main advantage, which is grasping human preferences
The main advantage is that this function requires no reward model, no human feedback, and a lot less hyperparameter tuning. It relies on the DPO (direct policy optimization) algorithm. The trick is based on two things:
- Using the LLM itself as a reward model
- Dataset of triplets (request (prompt), chosen answer, rejected answer).
How can LLM be its own reward model?
This technique takes as input two models: a policy or trained model and a reference model. DPO's mission is to ensure that the output of the trained model is more likely to be the chosen answer than that of the reference model and vice versa for rejected answers. The reference model acts as a reward model because its output is what drives the update process of the trained model. In other words, if the trained model scores better, then it is "rewarded," and if not, it is "penalized.”
So far, we have outlined the process of fine-tuning. However, in real life, when implementing this process, several challenges arise. In this part, we are going to share some of them as well as some remediations.
The challenges of fine-tuning

The major challenge is Catastrophic forgetting
What is it?
Altering a model through fine-tuning necessarily means interfering with the architecture. This can lead to some radical changes in the model’s abilities. The phenomenon known as “catastrophic forgetting” occurs when the learning process, while adjusting to new tasks or data, forgets what it has previously learned.
To illustrate this phenomenon, an analogy will be helpful
The chef’s spice rack
Imagine the spice rack of a 3-Michelin-starred chef specializing in vegetarian dishes. It is obviously well organized, packed, and fits every one of its dishes. However, the chef wants to integrate fish into his cuisine. He needs to “fine-tune” his spice rack to allow him to do so. So, he took the decision to add a few new, fish-specific (“task-specific”) spices. The problem is that the spice rack is small, so when new spices are introduced, the chef might have to take some of the old ones out or reorganize them. Due to these modifications, organization changed, and some spices may have disappeared. So while trying to integrate new elements into his cuisine, the chef may have unintentionally sacrificed other elements. This might make him unable to make any proper dishes. Imagine him through salt and pepper !
Other challenges:
- Memory overload
Fine-tuning a model requires storing a pre-trained model and its parameters. Moreover, you need to add to that all the new computing outputs that need to be stored temporarily or permanently, such as optimizers and loss states. This new load can get big enough to overload memories.
- Computational fever
The previous challenge raised the need for storage; there is also the computing power necessary to refine the pre-trained model parameters and carry out the new operations. All this implies the need for heavy (sometimes very heavy) hardware performance.
- Overfitting
The model can get “stuck” on the training data and perform badly on new data. This happens, especially when the fine-tuning dataset is small or very representative of the context
- Bias and ethical considerations
Since it is obtained from real-world observations, the initial training data reflects societal biases. As a result, a poor fine-tuning dataset can reveal and/or accentuate some biases, posing ethical questions about the model.
Remediation
The fine-tuning is here to improve and enrich the model for a specific task. The reasons that lead to these issues are diverse (e.g., low-quality datasets, poor regularization techniques, etc.).
Some mitigation strategies are more easily spotted than others. For example, the last challenge example requires extensively curated datasets, whereas catastrophic forgetting may require a bit more reflection. An intuitive solution is to find a way to protect the knowledge acquired. It can be done by making it untouchable or by controlling the extent of modification possible.
There is more than one way to achieve that (e.g., multi-task fine-tuning). However, for this article, we will focus on the most famous one: parameter-efficient finetuning.
A little spoiler: it doesn’t only solve the catastrophic forgetting but also computational and memory challenges
PEFT: Parameter Efficient Fine-Tuning
What is it?
The core principle of this method is to reduce the number of parameters that are updated. Instead of taking in all the models’ parameters in the fine-tuning process, PEFT can focus either on a small subset of them or on new parameters or layers added specifically for the fine-tuning process.
It's clear how memory overload and computational fever are avoided.
As for catastrophic forgetting, it might be less intuitive, so I will go back to my analogy of the spice rack. The PEFT enables the chef to either add new spices without replacing or reorganizing the existing ones or carefully modify some spices on its rack.
Therefore, these two options limit the risk of losing knowledge or abilities.
How does it work?
The most commonly used PEFT technique is LoRA⁴—Low Rank Adaptation for LLMs. Basically, using a mathematical technique called “low rank decomposition" reduces the number of the model’s parameters to update. The idea is based on the “Intrinsic Rank Hypothesis,” which states that not all the parameters are equally important; therefore, getting rid of some of them won’t change anything.
On the other hand, it is able to highlight the important ones in an even manner across the layers and acts as a guide for the algorithm.
Pay more attention to adjusting this parameter, it’s crucial for the task!
Other interesting implementations are derived from LoRA. One of the latest is AdaLoRA⁵: Adaptive Budget Allocation for LoRA. It adds a step where it ranks the layers of the subset of layers in terms of importance and activates more parameters the more the layer is important
Another one is (IA)⁶, whose principle is to scale the outputs of the activation function based on the vector of parameters that lead to that output. Reducing or increasing the magnitude of an output will impact the back-propagation and, therefore, the model’s performance.
An example of implementation
In order to make it more concrete, I will share with you a simple but rich process of supervised fine-tuning using LoRA and DPO for preference learning. This example can be improved with a lot of things, such as specifying more training arguments. I leave that for another day.
We can summarize the process as follows :
- Select and load the pre-trained model and its tokenizer
from transformers import AutoModelForCausalLM
from datasets import load_dataset
from trl import SFTTrainer
model_name = "facebook/opt-350m"
# Selecting the model
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.float16, attn_implementation="flash_attention_2")
tokenizer = AutoTokenizer.from_pretrained(model_name)
- Prepare the labeled dataset
# Prepare the dataset
dataset = load_dataset("HuggingFaceH4/ultrachat_200k", split="train")
def tokenization(example):
return tokenizer(example["text"])
tokenized-dataset = dataset.map(tokenization, batched=True)- PEFT using LoRA
# Using LoRa for PEFT
peft_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
)- Fine-tune the model
# Fine-tuning
trainer = SFTTrainer(
model,
train_dataset=tokenized-dataset,
dataset_text_field="text",
peft_config=peft_config,
)- Preparing dataset for preference learning
# an example of DPO dataset
dpo_dataset_dict = {
"prompt": [
"hello",
"Which is the best African football team?",
"Which is the best European football team?",
],
"chosen": [
"Hi, nice to meet you",
"Morroco",
"Italy",
],
"rejected": [
"Leave me alone",
"Not morroco",
"Germany",
],
}- Preference learning with DPO
# DPO preference learning
dpo_trainer = DPOTrainer(
model,
model_ref,
args=training_args,
beta=0.1,
train_dataset=train_dataset,
tokenizer=tokenizer,
)
trainer.train()putApplications of Fine-tuning LLMs
As you know now, a fine-tuned model has a specific mission. ChatGPT is a fine-tuned model based on GPT3.5 for the free version. The applications are diverse; it's not that far-fetched to say that:
The applications are limited to your imagination
We are seeing social media content generation, marketing campaign generation, medical text analysis, code generation and documentation, sentiment analysis in customer support, or even chatbots specializing in business functions such as sales or finance. Any list of application examples will not be exhaustive enough.
Conclusion
In conclusion, a new era of contextualized GenAI has begun with the development of LLMs and the enhancement of fine-tuning procedures. Tailoring a model with fine-tuning is like a chef refining their spice rack; it’s a delicate balance between preservation and adaptation. The difficulties in fine-tuning, which range from catastrophic forgetting to ethical considerations, highlight how complex it is to customize these models for particular purposes. Technologies such as PEFT have the potential to overcome these obstacles, much like a chef intelligently enriching his repertoire without compromising his culinary identity. As far as i am concerned, it looks like GenAI express is on the 9 and 3/4 platforms; if you don’t hope on it, you might miss out on a magical adventure
* a set can be just one parameter Unless otherwise noted, all images are by the author
References
1 — arXiv:2203.02155 — March 2022 —Training language models to follow instructions with human feedback
2 — arXiv:2305.11206 — May 2023 — LIMA: Less Is More for Alignment
3— arXiv:2305.18290 — May 2023 — Direct Preference Optimization: Your Language Model is Secretly a Reward Model
4 — arXiv:2106.09685 — October 2021 — LoRA: Low-Rank Adaptation of Large Language Models
5 — arXiv:2303.10512 — Dec 2023 — AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning
6 — arXiv:2205.05638 — August 2022 — Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning





