
Towards Unbiased Evaluation of Large Language Models
How benchmark leakage and data contamination undermine LLMs evaluation

“Our new LLM beats GPT in every benchmark!”
It is becoming increasingly common to hear bold claims like this, as the hype around LLMs is huge. There are new models every week, and currently everyone is trying to compete with GPT-4, which is still the most powerful LLM.
Benchmarking is a critical part of evaluating progress in large language models.
Benchmarks like MMLU and HellaSwag are the standard for assessing language models on skills like reasoning and comprehension. The scores provide a snapshot of progress, with new state-of-the-art results heralded as breakthroughs. LLMs are usually evaluated in a zero-shot setting, without explicit training on the test set, to gauge their general abilities.
This article shows how easy it is to manipulate benchmark results and offers suggestions to maintain evaluation integrity.
The Trouble with Benchmarks
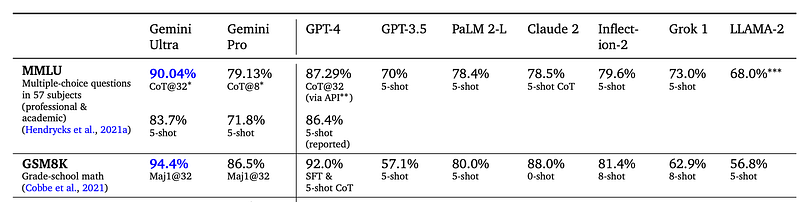
Often, benchmarks don’t reflect usefulness in real-life scenarios. Google’s newest model, Gemini Ultra, scores 90.04% on MMLU. While this is an impressive score, taking a closer look at the evaluation methodology, it is CoT@32 (chain of thought with 32 samples). It means we have to prompt 32 times to get 90% accuracy! Most of us are expecting an accurate answer in the first try, especially when interacting with a chatbot.
Unfortunately, this issue is just the tip of the iceberg of LLMs evaluation.
In machine learning, models are commonly evaluated by measuring their performance on a test set that was not used during training. Typically, this process allows for an unbiased estimate of how the model will generalize to new data.
Benchmark leakage and data contamination are two terms that both refer to a concerning issue: when the test data somehow leaks into the pretraining data of LLMs, leading to inflated performance. It makes comparisons between LLMs unfair and provides an unreliable measure of progress.
The evaluation is compromised if examples from the test set leak into the training data. This data contamination essentially allows the model to cheat on the test.
Contamination can occur in various ways. Test data might be intentionally or unintentionally included in training data. More subtly, if test data is available online, web-scraped training data could inadvertently contain test examples. Models may also be explicitly trained to regenerate test datasets based on format and characteristics. Regardless of the cause, contamination renders empirical comparisons between models invalid.
This benchmark leakage provides an unfair advantage if one LLM has seen data related to the test set, but another has not. It casts doubt on claimed improvements and makes comparisons misleading, undermining the purpose of benchmarks. Unfortunately, leakage is problematic to detect externally and benefits models that exploit it.
Introducing phi-CTNL
Our pretraining data for phi-CTNL is constructed by carefully curating an expert-crafted, non-synthetic data mixture. Specifically, we first choose the downstream academic benchmarks that we wish to evaluate our model on, then pretrain on those benchmarks.
The hilarious paper titled Pretraining on the Test Set Is All You Need highlights the pitfalls of relying too heavily on benchmarks for evaluation.
They show how a small 1 million parameter LLM called phi-CTNL pre-trained on just 100,000 tokens achieves perfect scores across diverse academic benchmarks, outperforming state-of-the-art models like GPT-3. The key? The pretraining data consisted solely of the testing data from those exact benchmarks.
This is the risk of benchmark leakage — when test data leaks into the pre-trained model, evaluation results become meaningless.
Even if meant as a parody, the paper brings attention to a serious issue typically unnoticed by the general public.
Demonstrating the Risks
To concretely demonstrate the risks, Zhou et al. [3] take popular LLMs of varying sizes like GPT-Neo (1.3B parameters) and LLaMA (65B parameters) and continue pre-training them on data related to test sets. They test increasingly severe forms of leakage using the training set, test prompts, and the full test set.
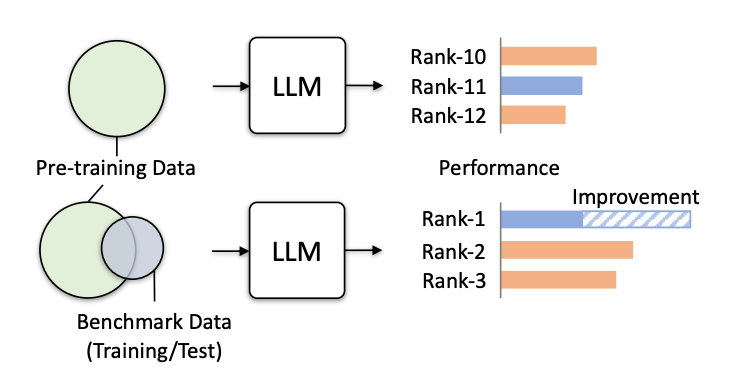
The results are dramatic. On benchmarks like LAMBADA and MMLU, small models leapfrog over far larger ones just by training on associated data, improving 20–30% in some cases. For instance, GPT-Neo surpasses LLaMA on many tasks when given the training set, despite having 50x fewer parameters. Even language tasks in Chinese see a boost, even though the models have little Chinese data overall. Clearly, related training data is hugely valuable.
Incorporating test prompts provides another massive gain, with models regularly achieving over 90% accuracy by learning the exact test format. And with full test set leakage, models can score 100% — they simply memorize all examples.
At first glance, it may seem benchmark leakage only causes misleadingly high evaluation scores. However, it can negatively impact LLMs in multiple ways. Performance gains are restricted to leaked benchmarks, sometimes decreasing scores on other tests. The model becomes skewed toward specifics of leaked data at the expense of general skills.
Benchmark leakage provides illusory progress on a narrow capability while potentially harming broader competence — trading generalization for inflated metrics on a single benchmark.
Data contamination and maintaining evaluation integrity
LLM developers should rigorously check pretraining data against test sets and disclose any risks found. Reporting the full composition of pretraining data also helps detect leakage. Unfortunately, most open-source models don’t publish their training data.
Benchmark leakage is not a new problem, but its scale is magnified with LLMs containing trillions of parameters pre-trained on internet-scale data. LLMs are enormous black boxes, so we can’t know what data has been used to train them.
Benchmarks and independent evaluators must keep pace to prevent misleading claims of progress.
Also, there are benchmarks where GPT is the evaluator (AlpacaEval), and the evaluation may be less meaningful if the tested model is fine-tuned on data generated by GPT itself.
Finding evidence of data contamination
Checking for data contamination is straightforward, and you can do it yourself.
First, pick a dataset you want to evaluate the model on. This dataset should have defined train/dev/test splits. Popular academic datasets like SQuAD, CoNLL 2003, etc, are good choices.
Next, prompt the model to generate examples from the dataset. Use a prompt like:
Please generate 3 examples from the {dataset} {split} split in the correct format.
Now compare the examples generated by the model to actual examples from the dataset. If they match, the model likely memorized parts of that split during training.
This process is used in the LM Contamination index, where they gather evidence of data contamination across different LLMs and benchmarks. There is evidence of contamination in many LLMs and datasets. [4]
If the model is not an instruct fine-tuned one (e.g., a model able to answer questions), prompt the first half of a benchmark instance and see if it can generate the rest. A user on X found evidence of contamination in phi-1.5 on the GSM8k dataset using this process.
Returning to the Gemini technical report, they mention the data contamination issue.
Evaluation on these benchmarks is challenging and may be affected by data contamination. We performed an extensive leaked data analysis after training to ensure the results we report here are as scientifically sound as possible, but still found some minor issues and decided not to report results on [some benchmarks]
The authors conducted extensive leaked data analysis after training the models to identify any potential overlap between the training data and test sets. This process involved thoroughly evaluating each benchmark used and checking for contamination issues.

The authors took steps to report decontaminated results where minor problems were found, such as with the HellaSwag benchmark. For HellaSwag, they measured performance using 10-shot prompting instead of fewer shots to avoid relying on possible training data overlaps.
The authors also emphasized evaluating the models on completely new held-out datasets that had confirmed separation from the training data. Examples include using new test sets like WMT23 and AMC math problems from 2022–2023 that were verified to have no overlap.
For benchmarks where contamination was identified as an issue after initial reporting, such as LAMBADA, the authors decided not to report those problematic results.
Future directions
Benchmark leakage allows LLMs to cheat, faking progress through contamination rather than true improvements in competence. If left unaddressed, this issue undermines trust in both benchmarks and LLMs. Following best practices can mitigate the risks, keeping benchmarks robust and comparisons fair.
Don’t trust claims of LLMs being better than other ones based on benchmarks run by the authors. Benchmarks and evaluation methodology can be cherry-picked to only show favorable scenarios.
Always try new models yourself before having an opinion.
Or why not experiment with creating your own benchmark? While not easy, you can customize it to your use case.
If you enjoyed this article, join Text Generation — our newsletter has two weekly posts with the latest insights on Generative AI and Large Language Models.
Also, you can find me on LinkedIn.





