
Towards Hybrid Reasoning: Assimilating Structure into Subsymbolic Systems
The recent advances in large language models (LLMs) have demonstrated their remarkable fluency and adaptability when generating text. After exposure to just a few examples, these models can produce surprisingly coherent continuations on a wide array of topics, exhibiting signs of flexible understanding and reasoning.
However, further analysis reveals fundamental gaps that temper unbridled optimism. At their core, LLMs accumulate only statistical patterns reflecting correlations of terms in their massive training corpus. They lack any structured representations or explicit modeling of concepts, relationships or rules. As a result, they frequently make basic logical errors, fail at systematic generalization beyond their training distribution, and struggle to sustain coherent reasoning chains.
Their fundamental nature as pattern recognizers driven by data frequencies rather than deeper understanding renders them brittle whenever queries require nuanced inference, causal analysis or compositional generalization. Questions demanding multi-step deduction, unraveling dynamics or synthesis of disjoint facts readily expose these limitations.
In contrast, knowledge graphs provide structured symbolic representations by explicitly encoding concepts as interlinked nodes within a network. Rich semantics are captured by modeling diverse relationships between entities, including taxonomic, logical, temporal and procedural connections. This substrate of validated facts and constraints supports explainable structured querying and analysis.
However, formulating precise formal queries requires expertise, while knowledge graphs also suffer from incompleteness and sparsity. They lack capacities for open-ended reasoning, adaptation or semantically-grounded generalization which neural models exhibit.
The complementary strengths and weaknesses of LLMs and knowledge graphs motivate a coordinated approach leveraging the intrinsic capacities of each representation.
But developing effective interfaces between vast statistical models and structured knowledge networks brings formidable challenges around alignment, traceability, efficiency and mutual enhancement.
Naive approaches fail to fully leverage the representations. Simply retrieving and presenting knowledge graph facts as isolated text to LLMs relinquishes the structure.
Conversely, directly translating questions to formal queries often lacks coverage.
Instead, a dynamic, multi-stage methodology is imperative to genuinely amplify the capacities of both knowledge forms.
This article explores the rationale and techniques for meticulously orchestrating fluid interactions between structured knowledge graphs and flexible neural language models.
The thesis is that effectively bridging these disparate representations requires coordinated pipelines aligning queries, decomposing needs, rapidly retrieving relevant subgraphs, propagating intermediate results across stages, recursively re-planning searches, consolidating evidence, and evaluating explanations — with LLMs acting as the contextual glue between structured knowledge and user needs.

Outline :
I. The Obstacle of Compositionality
We begin by outlining a key limitation of large language models — their struggles with compositional generalization. The brittleness of modularly combining causal knowledge fragments poses barriers to deeper reasoning.
Transition: This analysis of inherent capability gaps motivates exploring systems that can provide structured knowledge scaffolds.
II. Advantages of Knowledge Graphs Over Vector Search
Next we highlight strengths of knowledge graphs over raw vector search techniques for enhancing language model reasoning — modeling richer relationships, explainable trails, focused exploration and structure learning.
Transition: Having established knowledge graphs’ advantages, we analyze the inherent challenges of querying and scaling structured knowledge access.
III. Challenges of Complex Knowledge Graphs
Challenges around scale, noise, incompleteness and sparsity pose barriers to effectively querying real-world knowledge graphs to feed neural models.
Transition: These obstacles underscore the need for a coordinated multi-step approach.
IV. A Structured Assimilation Workflow
We propose an idealized multi-phase workflow focused on iterative analysis, modularization, parallel retrieval and recursive enhancement when assimilating knowledge graphs into language models.
Transition: This conceptual template offers a vision for automation. We discuss example enterprise applications.
V. Infusing Enterprise Operations
Finally, we envision language models conditioned on integrated industry knowledge graphs serving as reasoning engines on business challenges inside companies.
I. Compositionality Challenges
A key limitation of LLMs is their struggle with compositional generalization — flexibly combining modular skills learned separately into new configurations. This hampers systematic causal analysis.
a. Brittle Combination
- LLMs tend to memorize causal claims and inferences as singular chunks rather than structured composable units. For example, the statement “low rainfall causes reduced crop yield” is memorized as an indivisible unit.
- This makes it difficult for them to reliably combine multiple learned causal relations to make novel inferences. The causal links are not modularly separated.
- As a result, novel combinations of causal claims, even simple ones, often break LLMs as their responses become unpredictable without the exact statements seen during training.
For example, an LLM may have encountered these causal claims separately:
“Low rainfall causes reduced crop yield”
“High temperatures cause low rainfall”
But then fails to reliably combine them to deduce:
“High temperatures cause reduced crop yield”
Since the models lack explicit abstraction allowing structured composition of causal knowledge fragments.
b. Long Causal Chains
- Multi-step causal deduction requires maintainingintermediate conclusions across a chain of reasoning steps.
- However, LLMs struggle with this episodic memory needed to sustain facts deduced so far across long causal narratives.
- As a result, they frequently fail to produce consistent logical narratives when asked to elaborate explanations through multiple steps that require chaining sustained conclusions.
- Their inability to reliably track deduced facts hampers systematic causal analysis, especially involving long sequences of inferences.
c. Causal Transition
- Real-world causal reasoning navigates fluidly between interconnected chains rather than isolated snippets.
- For example, heavy rain may cause flooding which then causes mass evacuation and downstream economic losses.
- Hard-coding understanding of all possible transitions between causal chains is practically impossible.
- However, current LLMs cannot reliably generalize to smoothly transition between reasoning over causal chains. Their knowledge is fragmented rather than an interconnected web.
d. Hypothesizing Mechanisms
- Humans can creatively hypothesize new causal mechanisms to explain observed phenomena by constructing explanatory models.
- However, LLMs cannot actively simulate scenarios or intervene in the world to test hypotheses.
- This significantly limits their capability for productive hypothesis invention beyond reconfiguring statements already encountered during training.
- They fundamentally rely upon stated causal mechanisms rather than an intrinsic theory-building capacity involving conceptual abstraction and model testing.
Causal compositionality requires modular knowledge, sustained episodic memory, smooth transitions and creative hypothesizing. LLMs struggle on all these fronts indicating systemic brittleness in flexibly combining causal knowledge towards richer understanding.
This analysis of inherent capability gaps motivates exploring systems that can provide structured knowledge scaffolds.
II. Superiority of KG RAG system over Vector Database
Retrieval augmented generation (RAG) has emerged as a breakthrough technique that combines scalable text corpora with powerhouse language models. A key element in these pipelines is identifying useful passages of text to contextualize model generation using vector search over semantic embeddings.
However, when complex reasoning is demanded, systems relying solely on loose statistical signals around word associations and similarity reach inherent limits. Without appreciation for the interconnected nature of concepts, vector techniques struggle to consistently retrieve chains of facts that empower systematic inference.
This is where explicitly structured knowledge graphs become game-changers for next-generation RAG design. By encapsulating concepts as nodes, properties as attributes, and multidimensional relationships as typed edges, knowledge graphs provide the schematic scaffolding to elevate retrieval. Now instead of chasing ghosts in high-dimensional vector spaces for each query, an inference trail over validated connections brings explainable deduction powered by data-driven machine learning.
Essentially, knowledge graphs overwrite blind spots in pure statistics-driven search with transparent semantics around provenance, ontology and validity. Connectivity lends context to content. The global graph topology grounds local vector proximity with structural relevance. And symbolic, yet computable, element representations create an interoperable substrate for fluid querability.
The result — flexible neural generators securely stabilized on systematic symbolic foundations. Or in engineering parlance, high-level languages firmly grounded by robust operating systems. With structured knowledge retrieval keeping statistical models honest via explainable audit trails, this harmonious hybrid architecture promises more orchestrated augmentation between retrieval and generation.
Richer Relationships
Knowledge graphs model multiple interconnected relationships between entities — including taxonomic, logical, procedural, causal, temporal etc. This structured knowledge representation empowers more systematic reasoning versus just similarity scores.
For example, knowledge of a location’s lat/long coordinates enables geospatial inferences. Or part-whole hierarchies allow inheritance-based deduction. Explicitly qualifying facts to time periods also enables temporal reasoning.
These diverse signals guide precise logical chaining between retrieved facts using validated relations.
In contrast, passage embeddings in vector search encode entities as isolated atomic vectors lacking notions of structured relationships. Valuable relational signals are lost.
Explainable Inference Trails
By tracing paths over entities and relations during multi-hop inference, KGRA systems can expose full graph traversal audit trails. This transparency explains the underlying reasoning, unlike vector search where relevance scores are opaque neural projections.
Users can validate if conclusions rely on trusted regions of the knowledge graph or questionable connections. This auditability improves reliability for deployments where explainability is vital.
Focused Exploration
Explicitly linking related content allows focused exploration around key entities and concepts during information retrieval. This prevents drifting away to tangentially related content as can happen during recursive vector similarity chaining.
For example, directly retrieving other passages connected to “Paris” keeps reasoning centered rather than retrieving all of France’s content.
Modularity
Subgraphs with unique relationships and constraints provide modular knowledge components that can be composed into customized reasoning pipelines. This Lego-like modularity enables plug-and-play mixing and matching of reasoning tools.
In contrast, vector search offers no native mechanisms for modularity or constrained relation-based reasoning.
Structure Learning
By analyzing statistical patterns over graph connectivity, new factual knowledge and ontological constraints can be surfaced automatically. This allows self-improvement to enhance coverage and consistency.
Vector search lacks innate topology for such structure learning. Only external model retraining can incorporate new knowledge.
Here is a comparison table highlighting the key differences between standard vector search retrieval augmentation (V-RAG) and knowledge graph augmented (KG-RAG) systems when it comes to enhancing large language model (LLM) reasoning:
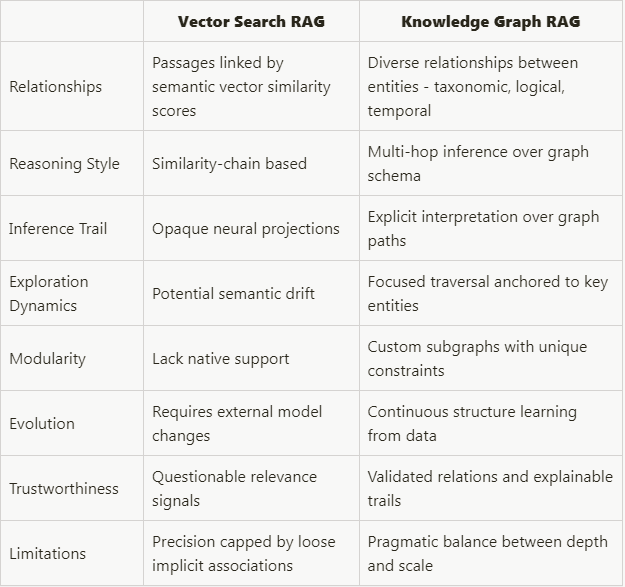
Overall for complex reasoning needs:
- Vector search offers only a notion of similarity between atomic passages
- This limits systematicity and explainability in inference chains
In contrast:
- Knowledge graphs provide diverse typed, hierarchical, lateral, positional, temporal and logical structured relationships
- Enables explainable, focused and ontologically-grounded inference trails
So knowledge graph augmentation scaffolds the construction of more transparent and structurally systematic reasoning. LLM’s still generate responses by ingesting retrieved content. But the upstream retrieval benefits greatly from explicitly encoded world knowledge.
The tradeoff is scalability if entire knowledge graphs are encoded versus selective scope for tractability. But for high-value complex reasoning, systematic knowledge beats shallow similarity.
Having established knowledge graphs’ advantages, we analyze the inherent challenges of querying and scaling structured knowledge access.
III. Challenges of Querying Complex KGs
a. Scale
- Real-world knowledge graphs scale to massive sizes with billions or trillions of facts.
- Reasoning over the full graph becomes intractable for many algorithms with exponential complexity.
- Even retrieving small relevant subgraphs poses efficiency challenges and latency issues at huge scale.
- Multi-hop reasoning requires traversing large intersecting neighborhoods across distant regions of giant heterogenous graphs.
b. Noise
- Automatically constructed knowledge graphs suffer from noise with facts extracted via error-prone information extraction pipelines.
- Resulting inaccuracies degrade query answers and can derail complex reasoning chains sensitive to precise dependencies.
- Cleaning noise through verification at scale remains extremely challenging and manpower-intensive.
c. Incompleteness
- Despite large size, most knowledge graphs are highly incomplete relative to the full scope of human knowledge.
- Important concepts and relationships are routinely missed during construction from limited corpora.
- Reasoning robustly by filling gaps requires broad commonsense background unavailable to algorithms.
- Queries may rely on missing entities or relations rendering them unanswerable due to sparsity.
d. Sparsity
- Most real-world graphs have a power law distribution with long tails.
- Majority of entities may have few direct neighbors and sparse connectivity.
- This exacerbates the incompleteness issue by hampering lookup and inference through sparse regions with minimal links.
- Multi-hop reasoning has an exponentially growing reachability challenge over such scattered graphs with islands of facts.
c. Query Formulation Difficulty
- Precisely mapping complex natural language questions into formal graph query languages like SPARQL or Cypher is challenging even for experts.
- It requires understanding precise semantics and relationships within questions to translate them into equivalent traversals over entities and relations.
- Graph query languages themselves have a steep learning curve limiting access to non-technical domain experts.
This combination of scaling complexity across massive, noisy, incomplete and sparsely interconnected graphs makes precise high-performance query formulation and execution a persistent challenge limiting reasoning potential.
These obstacles underscore the need for a coordinated multi-step approach.
IV. Proposed Hybrid Workflow
Effectively augmenting large language models (LLMs) with external knowledge graphs is a multi-step process that requires careful orchestration.
a. Leveraging an Agent System as a Cyclical graphs :
The fundamental difference between cyclical and acyclic directed graphs highlights useful parallels when architecting complex reasoning systems. Cyclical graphs allow nodes to connect back to themselves or previously visited nodes, introducing recursion, feedback loops and repeated querying based on updated beliefs. In contrast, acyclic graphs have a strict feedforward information flow following a fixed topology.
This distinction maps well to designing mechanisms for integrating large language models (LLMs) with external knowledge graphs. Effectively augmenting LLMs with structured knowledge requires coordinated orchestration across multiple steps — analyzing needs, retrieving relevant subgraphs, propagating intermediate signals, re-assessing remaining gaps, recursively launching additional queries, consolidating evidence, and final sensemaking.
This iterative process mirrors the cyclic nature of agent runtimes that actively query, incorporate knowledge, and then re-query models based on updated understanding. The cycles serve to gradually improve responses through managed injection of external structure.
In essence, effectively assimilating knowledge graphs into LLMs warrants orchestration across feedback loops that iteratively bind relevant external context, assess remaining needs, adjust strategies accordingly, and progressively elevate responses. Architecting these cyclic workflows allows cleanly augmenting LLMs with structured knowledge in a scalable, efficient and reliable manner.
On the other hand, acyclic chains that feed information through predefined rigid stages are inherently less adaptive in addressing complex reasoning tasks requiring dynamic expansion of knowledge retrieval. Carefully designed cyclic augmentation strategies provide the flexibility and controllability needed to methodically enhance LLMs through integration of structured knowledge graphs.
b. The Critical Role of Asynchrony
Effectively assimilating external knowledge graphs into large language models (LLMs) involves coordinating querying, evidence aggregation, sensemaking and incremental refinement across iterative cycles.
With complex reasoning workflows, many of these steps contain independent sub-tasks suitable for parallel execution. For example, concurrently launching queries across disjoint graph segments, or simultaneously requesting vector embeddings for multiple entities.
Handling such asynchronous workflows is vital for an efficient, scalable system architecture. Key advantages include:
- Reduced waiting times by allowing concurrent operations
- Increased computational resource utilization through parallelism
- Faster response times by enabling independent queries to run in parallel
- More flexibility for complex orchestration logic
LangGraph is one framework designed specifically for asynchronous coordination of cyclic decision graphs. The async nodes provide native concurrency while LangGraph handles the overarching workflow.
Other architectures for asynchronous knowledge assimilation include using middleware like Ray or encoding logic directly on asynchronous platforms like FastAPI.
By embracing asynchronous techniques, complex query-generate-refine cycles crucial for knowledge integration can be massively accelerated. This unlocks real-time assimilation at scale.
c. Blending Symbolic and Subsymbolic
We have established that effectively enhancing LLMs requires blending symbolic structured knowledge representations like knowledge graphs with the subsymbolic statistical learning within neural models.
Key strategies for productively blending and conditioning symbolic knowledge onto language models include:
d. Joint Vector Embeddings
Create a shared semantic space combining symbolic ontology elements like entities, relations, constraints with neural text token embeddings.
The common space allows similarity queries across both structured knowledge and free text. Embeddings act as a binding glue.
c. Graph Schema Priors
Inform LLM architectural design choices by encoding symbolic graph schemas — entities, relations, logic rules — directly into the model architecture.
Injection of symbolic biases shapes the reasoning topology.
d. Differentiable Programming
Represent program logic like knowledge graph traversals or queries as differentiable operations.
Allows end-to-end tuning of both structured program and neural model through gradients. Tightens integration.
e. Reasoning Shortcuts
Store curated symbolic rules which act as reasoning shortcuts, allowing models to bypass expensive searches.
For example, definitional rules directly relate concepts instead of requiring multi-hop search.
This selection of strategies exemplifies approaches to productively conditioning LLMs with structured knowledge for enhanced reasoning. The integration of neural interpretation with symbolic manipulation promises more systematic, semantically-grounded inference.
V. Coordinating Orchestration in Idealized Form :
The German sociologist Max Weber originated the notion of an “ideal type” to provide an analytical construct against which to compare empirical realities. An ideal type abstractly models the extreme manifestation of a phenomenon by rhetorically amplifying certain elements.
For example, Weber’s “ideal bureaucracy” extracts the essence of large organizations — hierarchy, specialization, standardization, productivity etc. Real institutions only approximate this conceptual purity to varying degrees.
Similarly, we can characterize the proposed orchestration sequence between knowledge graphs and large language models as an ideal type workflow for effectively assimilating structured knowledge.
The phases present an idealized workflow where reasoning needs are fully analyzed, modular tools launched concurrently, intermediate results propagated efficiently, re-planning recurses flawlessly, assimilation is comprehensive, and explanations evaluated accurately.
Much like Weber’s ideal bureaucracy, this conceptual workflow provides a logical yardstick. Actual implementations may only partially instantiating certain facets due to pragmatic constraints.
But establishing the ideal type gives a hypothesis for how an optimal system could look. It provides an archetype target outcome to motivate technical improvement. And deviations reveal potential gaps between vision and realization.
As an ideal type, the workflow offers an aspirational model for seamless assimilation of structured knowledge into language models. Aspects like concurrent evidence aggregation, automated recursive re-planning, and multi-channel explanations describe hypothetical efficiency peaks.
The vision defines functional facets for a reasoning ecosystem harmonizing symbolic and sub-symbolic capacities. With dedicated research this conceptual template could manifest more concretely. But for now, it serves as an idealized blueprint for augmenting language models through structured knowledge injection.
1. Analyze Reasoning Task
- Thoroughly examine the original reasoning task or question to comprehend the key entities and relationships involved.
- Identify core concepts, determine dependencies between them, disambiguate terminology.
- Deconstruct complex questions into atomic information needs required to assemble the answer.
This yields the basic building blocks for the knowledge retrieval workflow.
2. Decompose into Modular Tools
- Encapsulate targeted subgraph search operations, graph algorithms and vector similarity queries into reusable modular tools that handle lower-level knowledge graph intricacies.
- Create a toolbox of components addressing specific reasoning patterns — node recommendation, fact checking, temporal ordering etc.
- Define clean interfaces and data formats for interoperability between tools.
3. Initialize Multi-Pronged Queries
- Configure and launch modular tool queries in parallel to maximize concurrent evidence collection.
- Leverage approximate vector search to rapidly focus tools on most relevant regions of knowledge graph.
- Runtime optimizer continually adjusts exploration strategy based on intermediate signals.
4. Propagate Intermediate Results
- As modular tools generate outputs, directly populate centralized state store rather than raw dumps.
- Resolve co-references and entities across retrieved content for consolidation.
- Encoder assimilates evidence into shared vector space.
5. Recursive Re-planning
- Based on updated unified view of collected evidence so far, recursively re-evaluate remaining open reasoning needs.
- Dynamically launch additional tool queries as needed to fill gaps in explanation.
- Optimizer tracks progress towards answer completeness goals.
6. LLM Assimilation
- Loader batches updated state digest for ingestion by large language model to interpret, disambiguate and assimilate heterogeneous evidence.
- LLM acts as inference glue reconciling details into coherent narrative while highlighting unrestrained speculation.
7. Evaluation & Explanation
- Assess alignment of assembled explanation with original reasoning query through validation queries and user feedback.
- Construct natural language response elucidating the evidentiary support and chains of reasoning followed in generating the overall answer.
- Exposer translates key graph traversal paths and tool outputs into an interpretable audit trail.
The workflow comprises an integrated pipeline leveraging modularity, parallelism and co-refinement of both structured knowledge and generative language components to converge on high-quality explanatory outputs.
We propose an idealized multi-phase workflow focused on iterative analysis, modularization, parallel retrieval and recursive enhancement when assimilating knowledge graphs into language models.
In Summary
We have explored a multi-faceted approach for effectively assimilating structured knowledge graphs into large language models to create integrated reasoning systems.
The methodology combines the complementary strengths of symbolic knowledge representations and neural semantic capabilities. Careful orchestration across iterative cycles of analysis, retrieval, propagation, re-planning, assimilation and explanation allows efficiently injecting relevant external structure into fluid semantic spaces.
The workflow leverages parallel queries, shared vector embeddings, and controller architectures to synergize modalities. It aspires towards automated augmentation but crucially retains interpretation, evaluation and adjustment loops to ensure human oversight on transparency and quality.
Blending talents allows lifting language models beyond pattern recognition into powerful reasoning engines capable of expert-level deduction yet expressive natural language connectivity.
Enterprise Reasoning Engines
Looking forward, such knowledge-infused large language models could serve as versatile reasoning engines within enterprise operations.
They assimilate an expanding knowledge graph assembling curated industry insights, internal statistics, regulations, precedents and project memories. Vector embeddings learned across this structured data combined with textual corpora impart fluid access.
Agents then invoke enhanced models to tackle customized reasoning challenges posed in natural language or via graphical interfaces. These include forecasting market responses, optimizing supply chain flows, identifying candidate innovations, even advising legal strategies and product positioning.
Over time, instantiated workflows allow teams to frame complex problems for automated analysis by an augmented intelligence with both structural logic and contextual adaptability. Continual assimilation of new knowledge powers perpetual enhancement.
The Bigger Picture
Stepping back, the answer to augmenting neural networks lies not in ever-increasing scale or data volumes but carefully cultivating connectivity to diverse reasoning talent. Only through coordinating specialization can capability compound.
The ideal type workflow offers a conceptual roadmap for productively conjoining graphical precision with textual expression into integrated systems that solve multifaceted challenges. More cohesive computation awaits this harmonious hybridization of neural and symbolic.
—
Chief AI Officer & Architect : Builder of Neuro-Symbolic AI Systems @Fribl enhanced GenAI for HR
In Plain English 🚀
Thank you for being a part of the In Plain English community! Before you go:
- Be sure to clap and follow the writer ️👏️️
- Follow us: X | LinkedIn | YouTube | Discord | Newsletter
- Visit our other platforms: Stackademic | CoFeed | Venture
- More content at PlainEnglish.io





