
Top Python libraries for Time Series Analysis in 2022
Python libraries and frameworks data scientists must know for time series analysis in 2022

Introduction
A time series is a sequence of data points, typically consisting of successive measurements made over a time interval. Time series analysis is the process of using statistical techniques to model and analyze time series data in order to extract meaningful information from them and make forecasts.
Time series analysis is a powerful tool that can be used to extract valuable information from data and make predictions about future events. It can be used to identify trends, seasonal patterns, and other relationships between variables. Time series analysis can also be used to forecast future events, such as sales, demand, or price movements.
If you are working with time series data in Python, there are a number of different libraries that you can use. In this article, we will review most popular libraries in Python in no particular order.
sktime
Sktime is a Python toolkit for working with time-series data. It provides a set of tools for dealing with time-series data, including tools for processing, visualizing, and analyzing data. Sktime is designed to be easy to use and to be extendable, so that new time-series algorithms can be easily implemented.
Sktime provides an extension to scikit-learn API. It includes all of the necessary methods and tools for the efficient resolution of problems involving time-series regression, prediction, and classification. The library contains specialized machine learning algorithms as well as conversion methods for time series. These are features that are not available in any other libraries.
As per the documentation of sktime, “Our aim is to make the time series analysis ecosystem more interoperable and usable as a whole. sktime provides a unified interface for distinct but related time series learning tasks. It features dedicated time series algorithms and tools for composite model building including pipelining, ensembling, tuning and reduction that enables users to apply an algorithm for one task to another.
sktime also provides interfaces to related libraries, for example scikit-learn, statsmodels, tsfresh, PyOD and [fbprophet], among others.”
Example:
from sktime.datasets import load_airline
from sktime.forecasting.model_selection import temporal_train_test_split# from sktime.utils.plotting.forecasting import plot_ysy = load_airline()
y_train, y_test = temporal_train_test_split(y)
plt.title('Airline Data with Train and Test')
y_train.plot(label = 'train')
y_test.plot(label = 'test')
plt.legend()To learn more about this library, check out this link.
pmdarima
pmdarima is a Python library for statistical analysis of time series data. It is based on the ARIMA model and provides a variety of tools for analyzing, forecasting, and visualizing time series data. Pmdarima also provides a variety of tools for working with seasonal data, including a seasonality test and a seasonal decomposition tool.
One of the forecasting models often used in the time-series analysis is ARIMA (AutoRegressive Integrated Moving Average). ARIMA is a forecasting algorithm where we could predict future values based on the information in the past values of the time series without any additional information.
pmdarima is a wrapper over ARIMA model and comes with a auto function that automatically finds best hyperparameters (p,d,q) for arima model. The library includes and features:
- The equivalent of R’s
auto.arima functionality - A collection of statistical tests of stationarity and seasonality
- Time series utilities, such as differencing and inverse differencing
- Numerous endogenous and exogenous transformers and featurizers, including Box-Cox and Fourier transformations
- Seasonal time series decompositions
- Cross-validation utilities
- A rich collection of built-in time series datasets for prototyping and examples
To learn more about this library, check out this link.
TSFresh
tsfresh is a Python package that automates the process of feature extraction from time series. It is based on the idea that the information in a time series can be decomposed into a set of meaningful characteristics, called features. tsfresh takes care of the tedious task of manually extracting these features, and provides tools for automatic feature selection and classification. The package is designed to work with pandas DataFrames and provides a wide range of features for dealing with time series data, including:
- Automatic feature extraction from time series
- Automatic feature selection
- Time series decomposition
- Dimensionality reduction
- Outlier detection
- Support for multiple time series formats
- Support for missing values
- Support for multiple languages
To learn more about this library, check out this link.
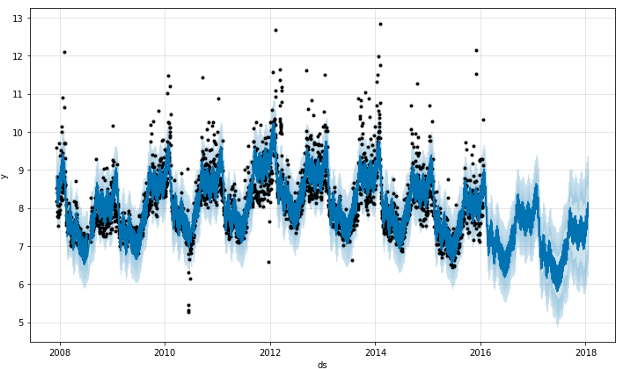
Prophet
Facebook’s Prophet is a forecasting tool available to anyone with data in CSV format. Prophet is open source software released by Facebook’s Core Data Science team. It is based on an additive model where non-linear trends are fit with yearly, weekly, and daily seasonality, plus holiday effects. It works best with time series that have strong seasonal effects and several seasons of historical data. Prophet is robust to missing data and shifts in the trend, and typically handles outliers well.
According to the official documentation, fbprophet works really well with time series data that has significant seasonal impacts and several seasons’ worth of previous data. Additionally, fbprophet asserts that it is resistant to missing data and is capable of effectively managing outliers.
To learn more about this library, check out this link.
statsforecast
Statsforecast offers a collection of widely used univariate time series forecasting models, including automatic ARIMA and ETS modeling optimized for high performance using numba. It also includes a large battery of benchmarking models. As per the official website:
- Fastest and most accurate
AutoARIMAinPythonandR. - Fastest and most accurate
ETSinPythonandR. - Replace FB-Prophet in two lines of code and gain speed and accuracy. Check the experiments here.
- Distributed computation in clusters with ray. (Forecast 1M series in 30min)
- compatible with sklearn interface.
- Inclusion of
exogenous variablesandprediction intervalsfor ARIMA. - 20x faster than
pmdarima, 500x faster thanProphet,100x faster thanNeuralProphet, 4x faster thanstatsmodels. - Compiled to high performance machine code through
numba. - Out of the box implementation of
ADIDA,HistoricAverage,CrostonClassic,CrostonSBA,CrostonOptimized,SeasonalWindowAverage,SeasonalNaive,IMAPANaive,RandomWalkWithDrift,WindowAverage,SeasonalExponentialSmoothing,TSB,AutoARIMAandETS.
PyCaret
PyCaret is an open-source, low-code machine learning library in Python that automates machine learning workflows. It is an end-to-end machine learning and model management tool that speeds up the experiment cycle exponentially and makes you more productive.
In comparison with the other open-source machine learning libraries, PyCaret is an alternate low-code library that can be used to replace hundreds of lines of code with few lines only. This makes experiments exponentially fast and efficient. PyCaret is essentially a Python wrapper around several machine learning libraries and frameworks such as scikit-learn, XGBoost, LightGBM, CatBoost, spaCy, Optuna, Hyperopt, Ray, and few more.
The design and simplicity of PyCaret are inspired by the emerging role of citizen data scientists, a term first used by Gartner. Citizen Data Scientists are power users who can perform both simple and moderately sophisticated analytical tasks that would previously have required more technical expertise.
Although PyCaret is not a dedicated time-series forecasting library but it has a new module dedicated for time-series forecasting. It’s still in pre-release mode but you can try that by installing pycaret with --pre tag.
PyCaret time series module is consistent with the existing API and fully loaded with functionalities. Statistical testing, model training and selection (30+ algorithms), model analysis, automated hyperparameter tuning, experiment logging, deployment on cloud, and more. All of this with only few lines of code.
pip install --pre pycaret
To learn more about this library, check out this link.
Conclusion
There are many time series forecasting libraries available in Python (more than what we have covered here). Each has its own strengths and weaknesses, so it is important to choose the right one for your needs.
Thank you for reading. See you next time!
I write about data science, machine learning, and PyCaret. If you would like to be notified automatically, you can follow me on Medium, LinkedIn, and Twitter.




