Top 9 Open-Source Text-to-Speech (TTS) Models

Are you working on an AI or machine learning project that needs text to be spoken aloud? If so, you’ll likely want to consider using a free and open-source text-to-speech engine. This article will explain how these engines work and recommend some of the best open-source options available.
But first, What is a TTS?
First, let’s break down what a text-to-speech engine is. It’s a computer program that can change written text into spoken words. These engines use natural language processing to understand the text and then convert it into speech that sounds like a person talking. Text-to-speech engines are used in many things you might already use, like smartphone assistants, GPS navigation, and tools that help people with disabilities.
Open-Source Text-to-Speech Engines
Open-source TTS engines offer a powerful way to convert text into speech, making them ideal for building accessible tools, automated voice systems, and virtual assistants. These engines are created and shared by a community of developers, allowing anyone to freely use, adjust, and distribute them. Here is a list of TTS Engine:
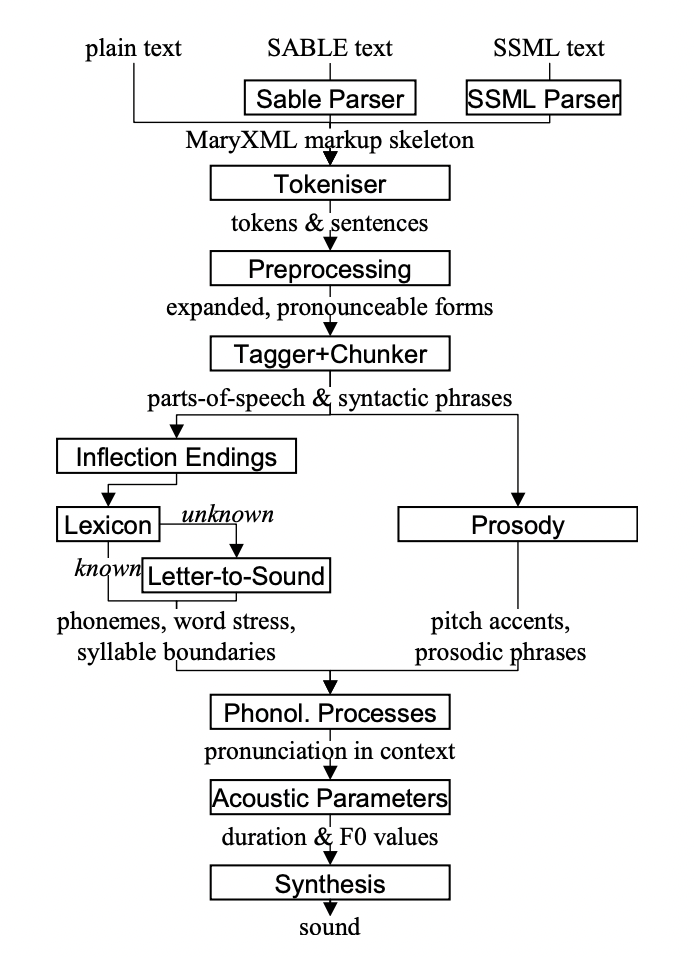
1. MaryTTS
MaryTTS stands out for its adaptability, thanks to its modular design. This means you can build custom text-to-speech systems and even create new voices using recordings. Here’s a breakdown of its key components:
- Markup Language Parser: This component deciphers the special codes embedded within the text, providing instructions for the system.
- Processor: This takes the parsed text and prepares it for conversion, like turning it into speech instructions.
- Synthesizer: The final step! This component generates the actual spoken output, adding natural-sounding qualities like pitch and emphasis.
2. eSpeak: A Simple and Versatile Text-to-Speech Engine
If you’re looking for a straightforward and language-friendly option, eSpeak is a great open-source choice. This software excels at providing clear speech in a variety of languages, all while keeping its size compact. Another benefit is its compatibility with various operating systems like Windows, Linux, macOS, and even Android.
Here’s a quick rundown of eSpeak’s pros and cons:
Pros:
- User-friendly
- Supports many languages and voices
Cons:
- Lacks advanced features and customization options
- Written in C (might require programming knowledge for advanced use)

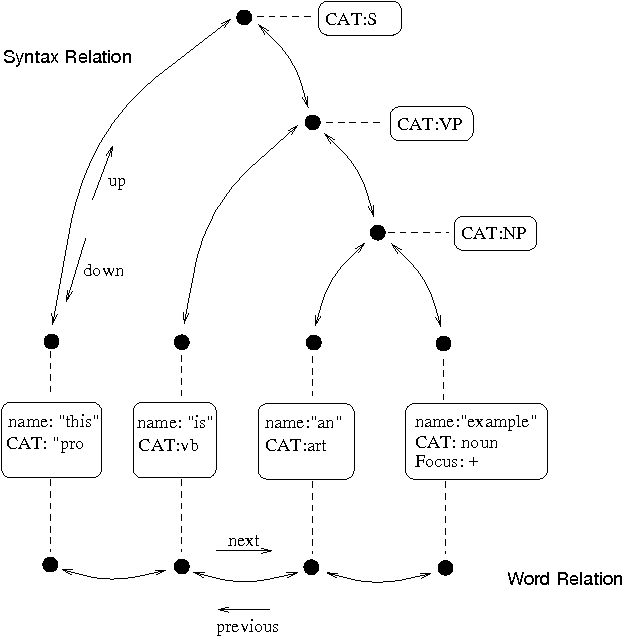
3. Festival: A Powerful Toolkit for Speech Synthesis Exploration
Developed by the University of Edinburgh, Festival is more than just a text-to-speech engine. It provides a comprehensive framework for building and experimenting with speech synthesis systems. This makes it a valuable tool for researchers and anyone interested in learning more about how TTS works.
The included diagram illustrates Festival’s general utterance structure, which resembles a tree with connected nodes. These nodes represent different elements that contribute to the final spoken output.
4. Mimic: Natural Speech with Traditional and Modern Options
Developed by Mycroft AI, Mimic stands out for its ability to generate remarkably natural-sounding speech. It offers two distinct approaches:
- Mimic 1: This method builds upon the well-established Festival Speech Synthesis System.
- Mimic 2: This cutting-edge option leverages deep neural networks for voice synthesis, resulting in even more realistic speech.
Mimic caters to a wider audience by providing both traditional and modern text-to-speech techniques. It also supports various languages. However, it’s important to note that Mimic might have limited documentation available.
5. Mozilla TTS
Mozilla TTS takes a cutting-edge approach to text-to-speech by utilizing deep learning, specifically sequence-to-sequence models. This allows it to generate speech that sounds more natural and human-like compared to traditional methods. Here’s what makes Mozilla TTS so interesting:
- Advanced Deep Learning: By leveraging modern neural network architectures, Mozilla TTS can analyze the complexities of human speech patterns and replicate them more accurately. This results in speech that’s smoother, more nuanced, and less robotic.
- Open-Source and Free: Like the other engines mentioned, Mozilla TTS is freely available for anyone to use and modify. This fosters collaboration and innovation within the open-source community.

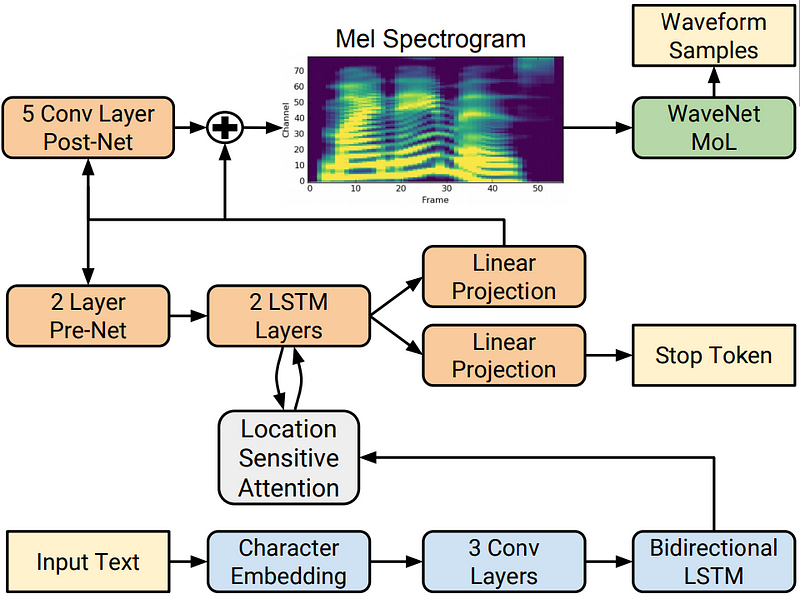
6. Tacotron 2 (by NVIDIA)
Although not an engine per se, Tacotron 2 is a neural network model architecture for generating natural speech. Open-source implementations of Tacotron 2 are available, and it has inspired many developments in speech synthesis technology.
This system allows users to synthesize speech using raw transcripts without any additional prosody information.
Pros: Developed by NVIDIA, good to be used as a neural network model.
Cons: Requires some technical knowledge to implement.
7. GTTS (Google Text-to-Speech)
This option offers a simple interface for those comfortable using Python. While not actively maintained by Google anymore, it can still be a good choice for basic needs with decent language support.
Link: https://pypi.org/project/gTTS/
9. NVidia NeMo TTS
This engine leverages deep learning for high-quality speech generation and is backed by a large tech company like Nvidia. It might have steeper setup requirements due to its use of deep learning models.
Last Words
Hope you find this helpful. Please Clap and comment if you like the article.
In case you need to see more, please consider subscribing:
In Plain English 🚀
Thank you for being a part of the In Plain English community! Before you go:
- Be sure to clap and follow the writer ️👏️️
- Follow us: X | LinkedIn | YouTube | Discord | Newsletter
- Visit our other platforms: Stackademic | CoFeed | Venture | Cubed
- More content at PlainEnglish.io





