
Top 10 NLP Projects on Kaggle to Strengthen Your Portfolio
Ever wish to work on an NLP project, this article is for you

Natural Language Processing (NLP) is a subfield of Artificial Intelligence involving the interactions between a computer and human language, in particular how to program or train an AI model to understand and implement the natural human language.
There are various topics or challenges in NLP tasks such as Tokenization, Lemmitazation, Text Encoding techniques, LSTM, RNN, etc. Combinations of these concepts can be used for NLP scenarios such as Question Answering, Text Classification and Summarization, Sentiment Analysis, Language Recognition and Translation, OCR, and many more.
Did you ever wish you could make an NLP project of your own? Well, this article covers best NLP cometitions.
This article will cover the problem definition and dataset of the top 10 NLP projects, that covers most of the NLP topics. One can learn a lot from working on these past NLP competitions.
Tweet Sentiment Extraction:
Sentiment Analysis is one of the famous case studies every data scientists have tried in their career. Tweet Sentiment Extraction is a competition organized by Kaggle, objective of the competition is to predict the word or phrase from the tweet that exemplifies the provided sentiment. This case study is similar to the Question-Answer system.

Sentiment Analysis objective is to predict only the sentiment of the text, instead, this case study is a step ahead, that predicts the phrase or words in the text that results in the given sentiment. Here, the target class label is the column selected_text , and given a sentiment column and a text column, you need to extract the target column.
Predict Closed Questions on StackOverflow:
Stack Overflow is the largest, most trusted online question and answers community for professional and enthusiast programmers to learn, share their programming knowledge, and build their careers. This competition was organized on Kaggle to predict whether new questions asked on Stack Overflow is closed or not.
Thousands of questions are asked by developers on the StackOverflow platform, so of them being constructive and good questions, and some of the questions being waste or lacked information. This competition was to predict whether a new question or post will be closed or not, and also predict the reason to close the post.
The dataset has several features including the text of question title, the text of question body, tags, Post Creation Date, Owner User Id, Owner Creation Date, and many more. The target class label is columns ‘OpenStatus’, and also includes additional information about Post Id, Post Closed Date, if the post is closed.
StumbleUpon Evergreen Classification Challenge:
StumbleUpon was a discovery and advertisement engine that pushed relevant, high-quality web pages and media recommendations to its users. For this challenge, you have been given web pages from the StumbleUpon site, and the task was to build a classifier to categorize webpages as evergreen or non-evergreen.
The dataset contains features including URL of web pages, boilerplate text, categories from alchemy API, other features about the webpage. This competition also provides raw HTML files of web pages, that will help to learn to work with HTML documents. The target class is binary, whether the webpage is evergreen or not.
Avito Duplicate Ads Detection:

Avito is a Russian classified advertisements website with sections devoted to general goods for sale, jobs, real estate, personals, cars for sale, and services. The objective of this challenge is to develop a model that can automatically spot duplicate ads. It will help Avito to make their platform easier for buyers and make their next purchase with an honest seller.
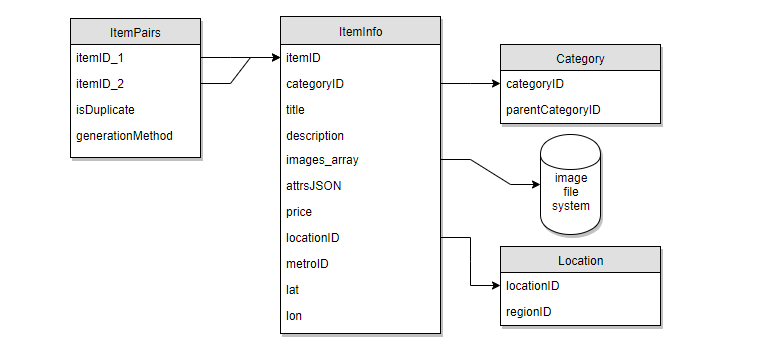
In this data, you have given information about two items, and you need to predict whether they are duplicates of each other or not. The features of the items include text title, description, images, and other information. You can combine concepts of NLP and CNN techniques to develop a model for this case study.
Quora Question Pair Similarity:
Quora is a platform to ask questions and connect with people who contribute unique insights and quality answers. In this challenge, Quora wants Kagglers to develop a model that can classify whether two given questions are duplicates or not. This model can help Quora to develop a platform with an improved experience for Quora writers, seekers, and readers.
The dataset of this challenge has features including the two questions and their unique ids. The target class label is ‘is_duplicate’, which denotes whether the two questions are duplicates or not. You can employ NLP techniques to generate features for the two texts and train a model out of it to classify whether questions are duplicates or not.
Quora Insincere Questions Classification:
Social Media and the Internet are full of toxicity. Quora as a platform wants to be free with toxic comments and questions. In this competition, Quora asked Kagglers to build a model that can detect toxic content to improve online conversations.
Dataset for this competition has features including question id, question text, and binary target class ‘insincere’ that has a value of 1, otherwise 0 . According to Quora, an Insincere statement is that makes any statement rather than looking for any answer, or has had a non-neutral tone, Is disparaging or inflammatory, Isn’t grounded in reality, or uses sexual content.
Toxic Comment Classification Challenge:
This challenge is organized by Jigsaw to identify and classify toxic online comments. You are provided with a large number of Wikipedia comments which have been labeled by human raters for toxic behavior. The text comments in the data are in the English language.
The target class label is the type of toxicity: toxic, severe toxic, obscene, threat, insult, identity hate.
You are expected to develop a model that predicts the probability of each type of toxicity for each comment.
Jigsaw Multilingual Toxic Comment Classification
This challenge is organized by Jigsaw and is very similar to the last challenge. In the last challenge, the text is in the English language, but in this challenge, Jigsaw gives a better problem statement, where your test data will be Wikipedia talk page comments in several different languages.
Keyword Extraction — StackOverflow Tag Prediction:
This challenge was organized by Facebook to recruit data science top performers. The objective of the challenge is to identify keywords and tags from millions of text questions. This case study is a multi-label classification problem, where multiple tags need to predict for a given text.
The features of the data include unique id, question title, body, and the target class is ‘tags’. One needs to predict multiple tags for a given text.
Two Sigma Connect: Rental Listing Inquiries:
This competition was organized by Two Sigma, and the dataset for this competition is from an apartment listing website — renthop.com. The objective of this competition is to predict how much interest will a new rental listing on RentHop receive.
The prediction will be based on the listing content like text description, photos, number of bedrooms, price, etc, and you need to predict the target class label — interest label . The target class has 3 categories ‘high’, ‘medium’, ‘low’, and hence it is a multiclass classification challenge.
Conclusion:
In this article, we have discussed 10 top NLP projects hosted on Kaggle. Implementing these case study requires good knowledge of the NLP, and one can learn a lot from it. An aspiring data scientists should try these NLP projects rather than working on basic projects such as Sentiment Analysis.
Thank You for Reading