
Three-pass reading and concept mapping of scientific papers and other learning material
An effective method for boosting your reading efficiency and learning from scientific papers and other knowledge heavy texts.

As a knowledge worker, you are often facing the need for reading rather large numbers of scientific papers. I am a data scientist and in relation to projects at work, I often find myself trawling the web for scientific papers touching the topics we are working on. Typically, the first round unveils 15–20 papers that are somehow related to the project. Maybe one or two if these are worth a deep investigation and perhaps a reimplementation of the method. At some point, I started to feel that some of my reading was wasted time — not 100% wasted but maybe 70–80% or so.
I realized I needed a more efficient process for reading, which was my motivation for developing the three-pass reading and concept mapping method. I read a lot of scientific papers, but I would say the method works on other short texts as well.
Preparations for reading
I print the paper and the template below to support the reading. The template ensures that I read papers in the same way and log insights and TODOs during the reading process. My template is of course colored by my professional field (data science) and you will most likely have to adapt this to your own reading. Nevertheless, it should give you a general idea of how to formalize your reading. Download the template: PDF
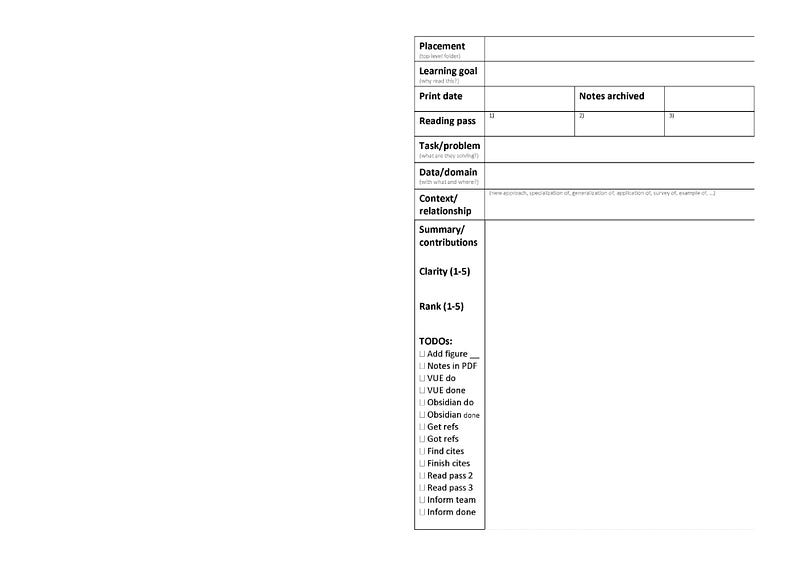
Pass 1 — concept discovery and knowledge matching
In the first pass, the goal is to determine if the paper is worth more time. I typically read the title, the abstract, parts of the introduction, the headlines, bullet point lists, the figures, and parts of the conclusion.
While reading and skimming, I highlight concepts, note down if there are key figures explaining the ideas, and determine how the paper extends my existing knowledge. In this, I draw on concept maps from my previous reading or make a list of new maps to construct if needed — commonly one or two. I typically devote 30–45 minutes to this first pass — or maybe less if I can see the abstract is way off what I am currently trying to build knowledge on.
Pass 2 — concept understanding and concept mapping
The second pass is significantly more meticulous. Here, I read the whole paper in details with the purpose of understanding concepts, how they relate to other concepts in the paper, and concepts of my existing concept maps. The purpose of this step is to understand the contents to a sufficient degree to place it in context of my existing knowledge.
In this step, I also mark papers on the reference list to get and look at google scholar’s citations for other relevant papers of interest if the paper is more than one year old. The reading template’s TODO checkbox list helps to track this and allows me to batch this in case I am reading multiple papers. Finally, I determine if the paper can help solve any of the problems we are dealing with in the projects I am involved in. Hence, if I should spend time on the final pass.
Pass 3 — reimplementation and reproduction of results
The third and final pass is about reimplementing the algorithms and reproducing the results in the article. In case you are in a different field, this step is more generally about repeating the experiment or study. In case you are not reading a scientific paper, see if there are any actions mentioned that you can perform to get a first-hand experience with the contents. Hence, pass 3 is about learning by doing.
Post-processing of notes
As mentioned, each pass ends with a decision of whether or not to read the next pass. Regardless of this, I always end the reading with digitizing my notes. This allows me to throw out the printed version and makes my notes searchable. I have python script that generates a cover page, prepends it to the original pdf, and perhaps copies it to various other folders on my local drive. This final step is to ease the inclusion of the paper in my personal knowledge management system. I use a combination of the concept mapping tool “Visual Understanding Environment” (VUE) and Obsidian in case I need to add longer and more complex texts.
An example — reading a survey on self-supervised learning
I am currently reading about various unsupervised learning paradigms and similar methods requiring no or few labeled training samples. Self-supervised learning is one approach in this realm. Reading into a new area, I usually try to find a survey article that is less than 3 years old. They typically provide a good overview and a suggestion for a taxonomy for sub-topics, which is often a good starting point for my own concept map. In this case, I found
Preparations for reading the survey
After having found the paper, I usually place it in a “To_print” folder to be printed later. This is because I bundle reading and I may find multiple interesting papers to pick from. As I print the paper(s), I also print a corresponding number of the template, which is then folded down the middle, wrapped around the papers and gets the print date field filled out. Once all papers in my “To_print” folder are printed, I relabel the folder to “Printed_YYYYMMDD” to make it easier to find the PDFs later. Then, I make a new “To_print” folder to collect the next batch of interesting stuff I stumble on. As I printed the current paper on the 6rd of December 2022, it temporarily resides in “Printed_20221206” until it is finally processed and moved into my permanent archive.
Pass 1 of reading the survey
In the first pass of my reading, I learned that the key idea in self-supervised learning is to use a pretext process P to assign a pseudo-label to the training sample and train the neural network using this label. I identified four generic applications, i.e., four concepts, and noted figure 3 on my reading template as this figure illustrates the four applications. In this pass, I also noted five data types and how self-supervised learning has been used on them. In this, I marked some papers in the references for further reading. Finally, I concluded that the paper was worth a second pass and it contains concepts to put into my personal knowledge management (PKM) system on AI. These next actions are captured on my template, which looks like this after pass 1.

After digitalization, the page looks like this.
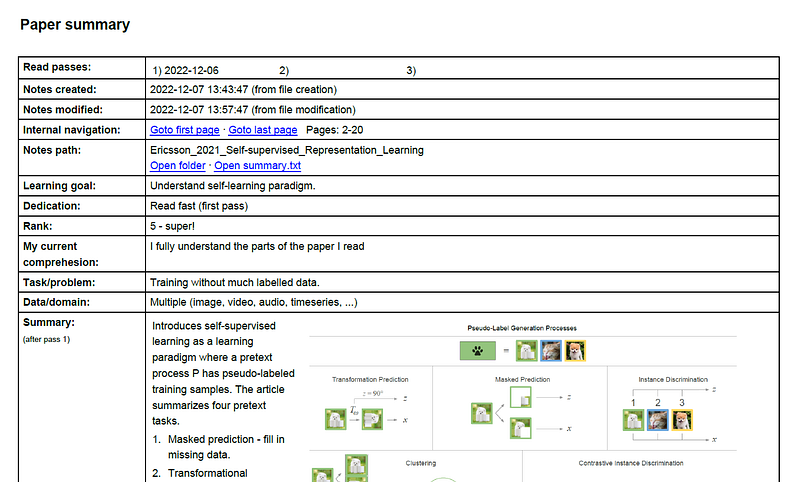
Pass 2 of reading the survey
In the second pass, I read more focused on the pretext process P, which is the key step that differentiates self-supervised learning from other learning paradigms. The survey contains pseudocode for these pretext methods. I am particularly interested in time-series data as the majority of the data I am working with. The paper paraphrases how self-supervised learning may be applied for instance discrimination and clustering and provides a few relevant papers for further reading. I decide not to do a third pass as there are no specific methods (it’s a survey)
Post processing the survey notes
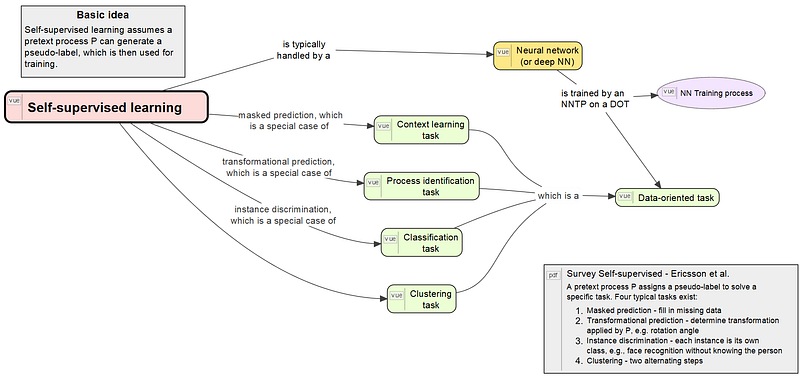
First, I use Adobe Acrobat’s highlighter function to mark passages and save the PDF with these highlighted paragraphs. As noted on my TODO, the paper contains new knowledge to insert into my concept maps. Self-supervised learning requires a new map and the first version looks like this.
After some more polishing the map looks like this. The small icons “VUE” on some of the nodes are links to other concept maps. Also note that I inserted a link to the PDF of the survey. This concept map is about self-supervised learning and will be further extended as I read more papers on the subject, e.g., the papers I found in the survey.
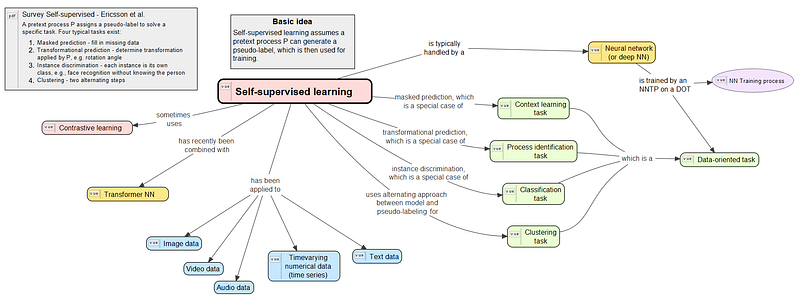
Conclusions
This three pass reading method may seem very elaborate and require extensive work. This may be true at the time you start reading into a subject. After the first few papers, the amount of new knowledge declines and thus also the work needed to capture your knowledge. Furthermore, I only perform second and third pass for very few papers. Around 80% of the papers I come across are pass one papers.
In my view, the concept mapping is worth the effort. First, I am a knowledge worker and my knowledge is to some extent my worth to my employer. The more knowledge I can chip in with in various projects, the higher is my worth. Unstructured knowledge is harder to access and therefore concept maps are a way to structure knowledge in the most accessible way. Thus, the three pass reading and concept mapping is a way to capture, distill and preserve knowledge to make it easily accessible for future use.
Further reading
You may also be interested in:
Finally, please consider to join medium to support my writing.





