
These Are the 3 Langchain Functions I Used to Improve My RAG
There are three retriever functions in Langchain that I usually use to improve my Retrieval Augmented Generation (RAG). In this article, I would like to share those functions.

Introduction
Retrieval Augmented Generation or RAG is one of well known method that usually use together with Large Language model (LLM) to answer external knowledge and reduce LLM hallucinations.
The knowledge limitation of LLM need to be covered by adding Vector database in our AI pipeline, here RAG method will be used to retrieve the relevant document from vector database.
Then LLM will try to summarize the answer based on the selected document, this method will help to reduce the hallucination from LLM as we provide the context for LLM to answer.
However…..
The RAG method is not really that smart, as some of the method still using semantic search similarity to retrieve the relevant documents and also there are some user prompt question that is not relatable with the document is vector database.
This can cause RAG system can not retrieve the correct document and LLM can not summarize the correct answer.
Based on this situation, I shared my 3 favorites retrieval technique from langchain that can be used in your RAG system. Langchain provide a lot of tools that can be used to create a good RAG. Here I would like to list those functions.
1. Multi Query Retriever

Langchain Multi Query Retriever Documentation
The Multi Query Retriever is one form of query expansion. With llm, we will generate more questions from our original query, and each generated question will be used to retrieve relevant documents.
This technique try to answer some cases where the user prompt is not that specific. In such situations, we can use the LLM capability to generate more questions. Those generated questions will be used to retrieve the documents from vector database.
The idea is to make the query more relatable to the topic and this question can retrieve more relevant documents using the generated questions.
Here I will share the code related to this method
#-------------------------------Prepare Vector Database----------------------
# Build a sample vectorDB
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
import os
os.environ["OPENAI_API_KEY"] = "Your Open AI KEY"
# Load blog post
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
data = loader.load()
# Split
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=0)
splits = text_splitter.split_documents(data)
# VectorDB
embedding = OpenAIEmbeddings()
vectordb = Chroma.from_documents(documents=splits, embedding=embedding)
#---------------------------Prepare Multi Query Retriever--------------------
from langchain.retrievers.multi_query import MultiQueryRetriever
from langchain.chat_models import ChatOpenAI
question = "What are the approaches to Task Decomposition?"
llm = ChatOpenAI(temperature=0)
retriever_from_llm = MultiQueryRetriever.from_llm(
retriever=vectordb.as_retriever(), llm=llm
)
#----------------------Setup QnA----------------------------------------
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_core.prompts import ChatPromptTemplate
qa_system_prompt = """
Use the following pieces of retrieved context to answer the question. \
If you don't know the answer, just say that you don't know. \
{context}"""
qa_prompt = ChatPromptTemplate.from_messages(
[
("system", qa_system_prompt),
("human", "{question}"),
]
)
def format_docs(docs):
doc_strings = [doc.page_content for doc in docs]
return "\n\n".join(doc_strings)
rag_chain = (
{"context": retriever_from_llm | format_docs, "question": RunnablePassthrough()}
| qa_prompt
| llm
| StrOutputParser()
)
rag_chain.invoke("What are the approaches to Task Decomposition?")The answer from above question is
There are three approaches to task decomposition:
1. LLM with simple prompting: This approach involves using a language model like GPT-3 to generate step-by-step instructions for a given task. The model can be prompted with a simple instruction like "Steps for XYZ" and it will generate a list of subgoals or steps to achieve the task.
2. Task-specific instructions: This approach involves providing task-specific instructions to guide the decomposition process. For example, if the task is to write a novel, the instruction could be "Write a story outline." This approach helps to provide more specific guidance and structure to the decomposition process.
3. Human inputs: This approach involves involving human inputs in the task decomposition process. Humans can provide their expertise and knowledge to break down a complex task into smaller, more manageable subtasks. This approach can be useful when dealing with tasks that require domain-specific knowledge or expertise.
These approaches can be used individually or in combination depending on the nature of the task and the available resources.2. Long Context Reorder
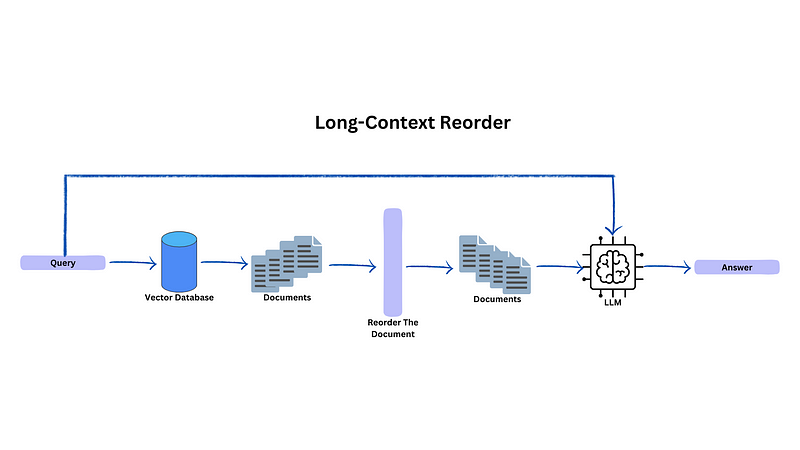
Langchain Long Context Reorder Documentation
This method is really suitable for the cases where we want to return more than 10 documents from the vector database. Why we need to return that many documents? Perhaps, our chunks is short and the vector database store a lot of chunks.
When LLM asks a question with this many documents, there are some cases where LLM not be able to understand the context from documents positioned in the middle of the retrieval documents.
This idea written in this paper

This issue can be solved by using Langchain function that can help to reorder your relevant documents. This ensures that the relevant documents are positioned at the beginning and the end of the documents list.
This steps need to be done before feeding them to the LLM for summarization.
Here I will share the code related to this method
#-------------------------------Prepare Vector Database----------------------
# Build a sample vectorDB
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
import os
os.environ["OPENAI_API_KEY"] = "Your Open AI KEY"
# Load blog post
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
data = loader.load()
# Split
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=0)
splits = text_splitter.split_documents(data)
# VectorDB
embedding = OpenAIEmbeddings()
vectordb = Chroma.from_documents(documents=splits, embedding=embedding)
#--------------------------------QnA Part and Reordering------------------------------------
from langchain.chat_models import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_core.prompts import ChatPromptTemplate
from langchain_community.document_transformers import (
LongContextReorder,
)
llm = ChatOpenAI()
qa_system_prompt = """
Use the following pieces of retrieved context to answer the question. \
If you don't know the answer, just say that you don't know. \
{context}"""
qa_prompt = ChatPromptTemplate.from_messages(
[
("system", qa_system_prompt),
("human", "{question}"),
]
)
def format_docs(docs):
#Called the reordering function in here
reordering = LongContextReorder()
reordered_docs = reordering.transform_documents(docs)
doc_strings = [doc.page_content for doc in reordered_docs]
return "\n\n".join(doc_strings)
rag_chain = (
{"context": vectordb.as_retriever() | format_docs, "question": RunnablePassthrough()}
| qa_prompt
| llm
| StrOutputParser()
)
rag_chain.invoke("What are the approaches to Task Decomposition?")The answer from above question is
There are three approaches to task decomposition:
1. LLM with simple prompting: This approach involves using simple prompts to guide the agent in breaking down a task into smaller subgoals. For example, the agent can be prompted with "Steps for XYZ" or "What are the subgoals for achieving XYZ?" This approach relies on the language model's ability to generate appropriate subgoals based on the given prompts.
2. Task-specific instructions: In this approach, task decomposition is done by providing task-specific instructions to the agent. For example, if the task is to write a novel, the agent can be instructed to "Write a story outline." This approach provides more specific guidance to the agent in decomposing the task.
3. Human inputs: Task decomposition can also be done with the help of human inputs. This approach involves receiving input or guidance from a human to break down the task into smaller subgoals. The human input can be in the form of instructions, suggestions, or feedback provided to the agent.3. Contextual Compression
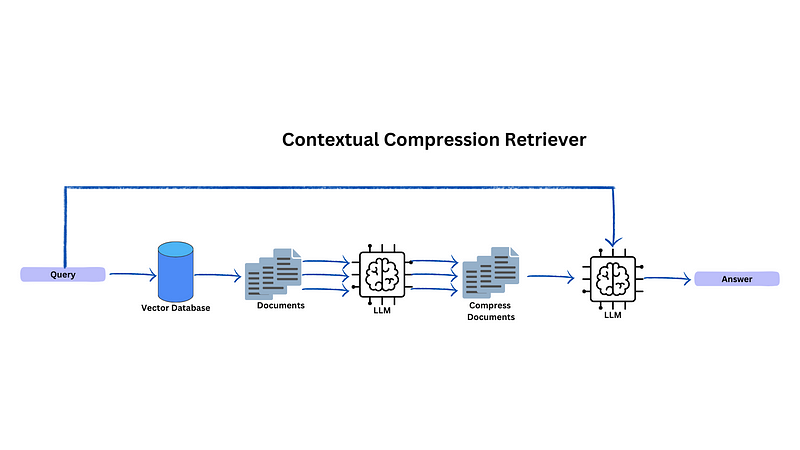
Langchain Contextual Compression Documentation
As the first method we try to use LLM to expand our query, for this method we try to compress or reduce the information from our relevant document.
There are some cases where the number of token in each of the chunks inside our vector database is very high and each chunks sometimes consist of irrelevant information in some of paragraphs.
To make our LLM able to summarize correctly, we need to remove those irrelevant paragraphs from our retrieved documents using LLM.
Here I will share the code related to this method
#-------------------------------Prepare Vector Database----------------------
# Build a sample vectorDB
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
import os
os.environ["OPENAI_API_KEY"] = "Your Open AI API KEY"
# Load blog post
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
data = loader.load()
# Split
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
splits = text_splitter.split_documents(data)
# VectorDB
embedding = OpenAIEmbeddings()
vectordb = Chroma.from_documents(documents=splits, embedding=embedding)
#----------------------------Contextual Compression Setup---------------------
from langchain.retrievers.document_compressors import DocumentCompressorPipeline, EmbeddingsFilter
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.document_transformers import EmbeddingsRedundantFilter
from langchain.retrievers import ContextualCompressionRetriever
splitter = CharacterTextSplitter(chunk_size=300, chunk_overlap=0, separator=". ")
redundant_filter = EmbeddingsRedundantFilter(embeddings=embedding)
relevant_filter = EmbeddingsFilter(embeddings=embedding, similarity_threshold=0.76)
pipeline_compressor = DocumentCompressorPipeline(
transformers=[splitter, redundant_filter, relevant_filter]
)
compression_retriever = ContextualCompressionRetriever(
base_compressor=pipeline_compressor, base_retriever=vectordb.as_retriever()
)
#--------------------------------QnA Part------------------------------------
from langchain.chat_models import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_core.prompts import ChatPromptTemplate
llm = ChatOpenAI()
qa_system_prompt = """
Use the following pieces of retrieved context to answer the question. \
If you don't know the answer, just say that you don't know. \
{context}"""
qa_prompt = ChatPromptTemplate.from_messages(
[
("system", qa_system_prompt),
("human", "{question}"),
]
)
def format_docs(docs):
doc_strings = [doc.page_content for doc in docs]
return "\n\n".join(doc_strings)
rag_chain = (
{"context": compression_retriever | format_docs, "question": RunnablePassthrough()}
| qa_prompt
| llm
| StrOutputParser()
)
rag_chain.invoke("What are the approaches to Task Decomposition?")The answer from above question is
There are several approaches to task decomposition: 1. LLM with simple prompting: This approach involves using a large language model (LLM) like OpenAI's GPT-3 to decompose tasks. By providing simple prompts such as "Steps for XYZ" or "What are the subgoals for achieving XYZ?", the LLM can generate a list of subgoals or steps necessary to complete the task. 2. Task-specific instructions: In this approach, task decomposition is guided by providing specific instructions tailored to the task at hand. For example, if the task is to write a novel, the instruction could be "Write a story outline." This helps the agent break down the task into smaller components and focus on each step individually. 3. Human inputs: Task decomposition can also be done with the help of human inputs. Humans can provide guidance, expertise, and domain-specific knowledge to assist in breaking down complex tasks into manageable subgoals. This approach leverages the problem-solving abilities and intuition of humans to aid in the decomposition process. It's important to note that these approaches can be used in combination or separately, depending on the specific requirements and constraints of the task.
Conclusion
Hope all these techniques can be used in your next project. All this techniques can be combined together if there are some cases that is overlapping with each other.





