
Deep Learning
The Unreasonable Ineffectiveness of Deep Learning on Tabular Data
And the recent work to address its poor performance on tabular data

Deep neural networks have led to breakthroughs in various domains that have long been considered a challenge. Two notable examples are computer vision and natural language processing (NLP).
We have seen speedy development in computer vision, beginning with the breakthrough development of AlexNet, winning the ImageNet challenge in 2012. We have ResNet¹ in 2015 achieving superhuman accuracy for the first time on the ImageNet benchmark dataset. We then witnessed the birth of generative adversarial networks (GANs)² in 2014, to the rapid improvements that ultimately led to the lifelike portraits of fake people from SyleGAN today.
In NLP, deep neural networks models are now state-of-the-art, outperforming conventional machine learning algorithms on benchmark datasets. Models such as GPT-2³ and BERT⁴ are the new gold standard. Google has deployed BERT in its search engine in 2019, the single largest update to its search engine in the past few years. GPT-2 is used in chatbot applications, and in some interesting ways such as a popular text adventure game called AI Dungeon. It wouldn’t be long now that these solutions will become commonplace in commercial products.
It is clear from these breakthroughs that deep neural networks have taken over the domain of unstructured data.
The success of deep learning boils down to the exploitation of inductive biases in these data, such as spatial correlations in the case of the convolutional neural network.
Yet it seems that there is no deep learning equivalent for tabular data.
Like it or not, unless you’re working in a company that works on signal processing applications or natural language processing, most data exists in relational databases and Excel spreadsheets. In fact, this state of affairs is not going away anytime soon!
Structured data
Data from relational databases and spreadsheets are examples of structured data. Structured data are highly organized in a tabular structure to allow efficient operations on the table columns such as search and joins. Typically a schema defined for the data: each attribute is named, and its value type is specified, which could be a string or integer for example. A unique identifier is also assigned in each schema. Usually, in order to perform a task, data needs to be drawn from several databases, each possessing their own schema.
Consider a movie streaming platform which provides monthly subscriptions.
The figure below shows an example of a several of the company’s databases with their associated schema. Here, we can see that there are tables storing
- user information such as the first name, last name, email,
- the names and descriptions of the company’s movie catalogue,
- ratings on movies watched by users, and
- tags on each user and movie interaction.
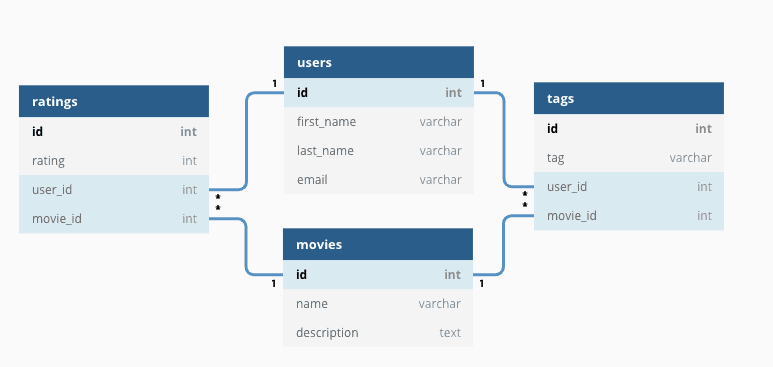
Relational databases are a well-studied, relatively mature technology. They are the de facto standard for storing tabular data. Given that so much data in the world exists in a tabular format, such as the above, it is no surprise that there is a strong motivation to predict from tabular data.
For example, we can predict the churn of a user based on the data from the tables using:
- demographic information such as age, gender, which country they are from, which landing page did they sign up at, as found in the users database,
- how they rated each movie, and when they watched it,
- the name and description of the movie, perhaps even its genre (action, comedy etc.), and
- enriched information on the movies and user email domains by joining them with external databases.
Surprisingly, despite the success of deep neural networks elsewhere, they don’t work particularly well on tabular data, and don’t seem to beat the performance of shallow neural networks.
The case for deep neural networks
Why consider deep neural networks at all? What are the advantages of deep neural networks that learn effectively from tabular data?
Automated Feature Engineering
Deep neural networks have a powerful feature preprocessing ability. We can construct feature preprocessors by stacking layer upon layer to learn a hierarchical representation of the data. Moreover, this feature preprocessing ability is finetuned via backpropagation as the network learns from labels in the supervised setting. Fittingly, the focus of a data scientist shifts from feature engineering to constructing a good architecture. Let’s face it, next to data cleaning, feature engineering is the second-least favorite activity of a data scientist.
Transfer Learning
The success of deep learning in computer vision and NLP owes in large part to the remarkable ability of these models to transfer what they have learned to an adjacent task. For instance, a data scientist can download a computer vision model, fully pretrained on ImageNet, and finetune it on her own dataset to classify diseased crops in agriculture. We are then able to share models with others, speeding up development of applications. Similarly, it is conceivable that a deep learning model can be pretrained on large sets of tabular data, providing a method to “pretrain” a base of knowledge (akin to a knowledge graph) and use it a module to speed up training of another model for a related task.
Bridging structured and unstructured data in a single model
An end-to-end deep learning model provides a way to link structured and unstructured data via the magic of backpropagation, all in a single model. At Canva (where I work), one application would be to combine user demographic information (such as their profession) with image features from design templates and images they have chosen. We can then provide a better prediction on the kind of design styles they like, and templates they might want to use. User demographic information exists in structured tabular data in relational databases, while the latter exists as unstructured image data. Linking a tabular data learning model with a convolutional neural network can be easily done in a deep learning framework such as TensorFlow. This is in contrast to gradient boosted trees where gradient information is not available to link it to another model.
Why does deep learning perform poorly?
Undoubtedly, the reigning champions of learning from tabular currently are decision tree-based algorithms. Gradient boosted trees are often the tool of choice, evidenced from their popularity in Kaggle contests, with XGBoost, CatBoost and LightGBM being crowd favorites.
At first glance, it is puzzling why deep learning are not competitive with tree-based algorithms. After all, features from combined databases do form high dimensional spaces, which deep learning exploits very well.
For a model to learn effectively from tabular data, there are several key issues that have to be addressed:
- features constructed from tabular data are often correlated, so a small subset of features are responsible for most of the predictive power,
- missing data in the form of
NULLvalues in a database, and - there is usually a strong class imbalance in the labels (in the supervised setting), for instance, users prefer only a small collection of movies in a movie catalogue.
Moreover, from a business intelligence perspective, predictions are not only the main goal, but finding the factors in the data for intrepretability of the predictions is just as, if not more, important.
Correlations between columns in a relational database and spreadsheets are common. There is often a small set of features (or combination of features) that contribute to the predictive power of the task. In short, our inductive bias is that there are (highly) correlated features, so selecting the minimum set of features is the best strategy.
Decision trees and their more advanced siblings, the random forest and gradient boosted trees, select and combine the features very well, via a greedy heuristic.
A key difference with the unstructured data, however, is that tabular data is often heterogenous. The features constructed from tables come from various unrelated sources, each with their own units (e.g., seconds vs. hours) and associated numerical scaling issues. The second difference is that the features themselves are sparse: unlike data from images, audio and language, there can be little variation in a column of a table. There are also typically more categorical features, in which the order (and value) of the features themselves are not important, and unlike numerical features, are discrete by nature. To handle this, preprocessing often has be done carefully for neural networks by learning dense embeddings.
These differences lead to features in a high-dimensional space that is generally not dense and continuous, making it difficult to exploit for a typical deep neural network. What needs to be done is to preprocess the space in such a way that the space is “friendlier” for a deep neural network.
Fortunately, recent developments in attention and sparse regularization now pave the way to learn more efficiently from structured data.
Overview of some recent work
Recently there has been a focus on improving the performance of deep neural networks on tabular data. Naturally, these works overcome the problems of canonical deep neural networks by emulating the best qualities of tree-based algorithms. We cover two recent works in this area, with a little more emphasis on the first since I’ve been experimenting with it recently.
TabNet
TabNet is a deep neural network specifically designed to learn from tabular data⁵. Its design departs from other works which are modified tree-based hybrids.
The key to TabNet is a learnable mask on the input features. Moreover, the learnable mask should be sparse, i.e., favor the selection of a small set of features that solves the prediction task.
An advantage of the learnable mask over trees is that the feature selection is not an all-or-nothing proposition. In decision trees, a hard threshold is placed on the value of a feature, so if the value exceeds a threshold T, then go down the right branch of the tree, otherwise go left. With a learnable mask, soft decisions can be made, meaning that the decision can be made on a larger range of values, not just a single threshold value.
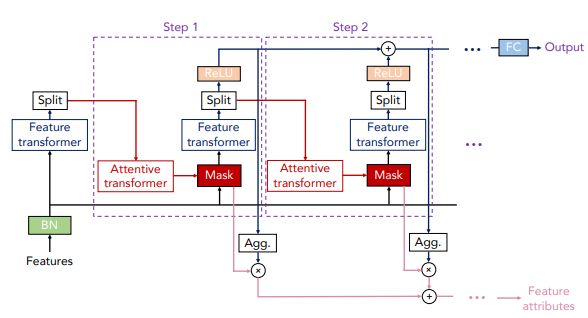
The TabNet encoder, seen in the figure above, consists of sequential decision steps which encodes and selects features via a learnable mask. TabNet trains on each row from a table, selects (attends to) the relevant features in each step using a sparse learnable mask, and aggregates the predictions from each step to emulate an ensemble-like effect when making predictions. More steps in the encoder means that more ensembles are constructed.
The two main components of the encoder are:
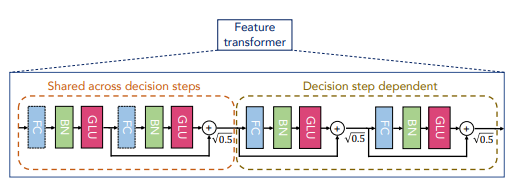
- the feature transformer: where the feature processing and engineering happens. There are two shared feature blocks to allow processed features to be shared between decision steps, and two decision step-dependent feature processors.
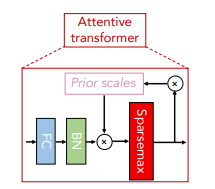
- the attentive transformer: where the learning of the sparse mask takes place. A sparsemax layer⁶ is used to promote sparsity in the learnable mask while it learns to attend to certain features. Feeding back information of prior scales allows TabNet to learn and control how much a feature has been used before in prior decision steps. A hyperparameter can be specified beforehand to control the amount of feature reuse between decision steps.
There is also a sparsity regularization loss function via Shannon entropy to control the overall sparsity of the masks in each decision step during training.

We can visualize the feature importance of each decision step, as well as an aggregated version. In the figure below, we plot the masks for the aggregated mask, and masks for decision steps 1, 2 and 3 for the Poker Hands dataset⁷. The rows of the image denote the number of test samples, while each column denote a feature. We can see some feature reuse between the different steps, with importance placed on some features for some test samples.
Interestingly, TabNet can be trained in an unsupervised manner. If the model is modified to an encoder-decoder structure, then TabNet works as an autoencoder on tabular data! The paper discusses one potential architecture for the decoder, which is a rather simple one that consists of feature transformers. Training involves deliberately censoring cells (as seen in the figure below) in the table in order to get the model to learn relationships between the cell and adjacent columns by predicting the missing values. Once training is complete, TabNet can be used as a pretrained model for classification and regression tasks.
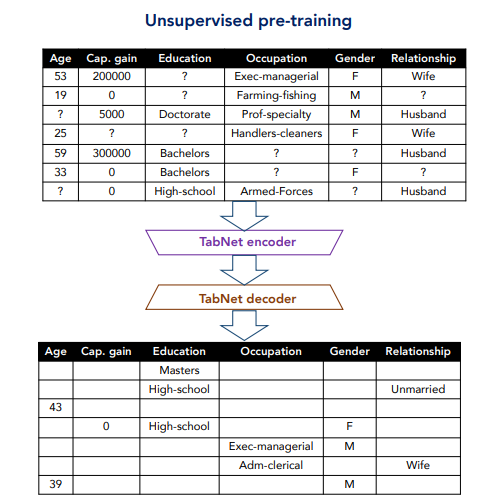
In my own experiments with TabNet, I have observed that:
- I didn’t have to perform feature preprocessing beyond specifying whether my features are integer, floats, booleans or string values.
- TabNet handles class imbalance automatically.
- TabNet is competitive with XGBoost, and in some cases, even surpasses it. In one test, it had 9% higher accuracy than XGBoost, which is a huge margin of outperformance!
- TabNet is surprisingly robust in its hyperparameters, and default hyperparameters often provided good performance. The one case where there was high sensitivity to hyperparameters was on the Poker Hand dataset, and the hyperparameters stated in the paper provided the highest accuracy.
- there was no drop in performance when the feature transformer was reduced to one shared block and one decision step dependent block, unlike the original paper, at least on my datasets.
It would be interesting if TabNet can be augmented with sequential adaptivity, so that the number of decision steps taken can be learned on the fly as per the adaptive computation trick used in recurrent neural networks⁸. Then it would be possible for the model to automatically figure out the number of decision steps it needs.
Another architecture change would be to replace the sparsemax function with EntMax instead (see below). It has been shown that EntMax performs better than sparsemax in other applications, so it would be worth trying.
Also an application of TabNet’s unsupervised mode is to allow it to impute missing values in tabular data. This is especially useful when analytics collection may be problematic, resulting in outages and missing data.
Update: I modified TabNet here. Check it out!
Neural Oblivious Decision Ensembles (NODE)
Recently accepted at ICLR 2020, a NODE module⁹ is composed of a prespecified number m of oblivious decision trees (ODTs), each with equal depth d. The twist, compared to other tree-based algorithms, is that these ODTs are differentiable, so error gradients can be backpropagated through them. Just like TabNet, NODE is an end-to-end deep learning model.
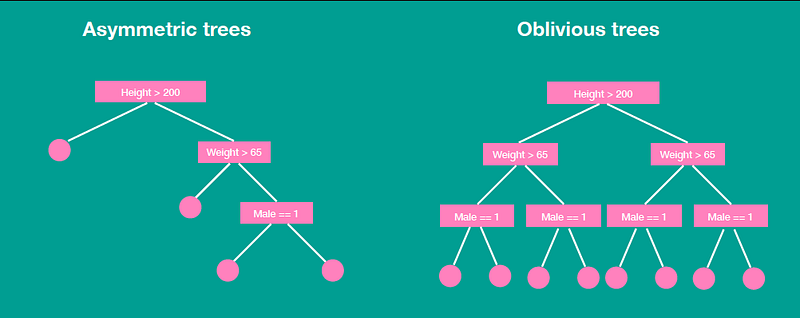
Let’s begin by looking at a vanilla ODT. Unlike asymmetric trees in the figure above (which are the base components of XGBoost and LightGBM), ODTs split data along d splitting features and compares each feature to a learned threshold. We can see from the figure that the split is made on a hard threshold, for example, all persons with weight above 65 kg always traverses down the right branch. Also note that exactly one feature is chosen for split at each level, giving rise to an all-or-nothing proposition.
Effectively, this means that
- each output from a single ODT is one of 2ᵈ binary strings,
- each ODT has exactly depth d, and
- each ODT is balanced.
The advantage of having balanced trees is that they are computationally efficient since each ODT can be represented as a decision table, and the splits can be computed in parallel. During inference, no if statements are evaluated since the result can be looked up from the pre-computed decision table. Secondly, the depth restriction of ODTs minimizes overfitting.
Each ODT is a weak learner, but when an ensemble of them are used together, the ensemble becomes a strong learner.
As an aside, ODTs are the main component used in CatBoost. It is not surprising that ODTs are the base component of choice for NODE, as the authors of the paper are from Yandex, which developed CatBoost.
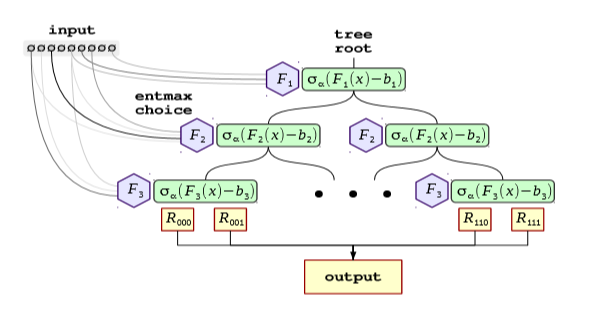
Now, the difference between NODE’s and CatBoost’s ODT lies in the choice of splitting feature and the splitting function used in the tree. Instead of a hard versions of these functions, soft, differentiable ones are used. NODE uses the EntMax¹⁰ rather than sparsemax to promote sparsity in both of these functions. EntMax is a recent development which generalizes the sparsemax and softmax functions, with the ability to learn sparse but smoother decision rules than sparsemax, giving better trade-off between sparsity and decision.
The NODE layer will, over time during training, choose a minimal set of features to split at each level (rather than just 1), and the splitting threshold covers a range of values (rather than just a single threshold).
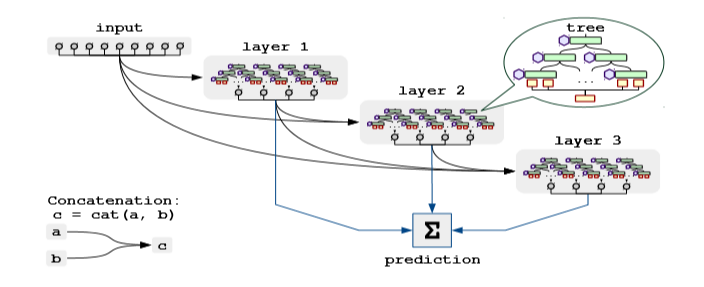
The deep in the architecture comes from stacking NODE layers one atop another. Each NODE layer takes in inputs from the original feature input and all other NODE layers preceding it. This is similar to the sequential decision steps in TabNet, as each NODE layer shares processed features with subsequent NODE layers. With this structure, the model can capture shallow and deep decision rules. The architecture was inspired from DenseNet¹¹.
The paper showed that NODE is competitive with other tree-based algorithms. It outperforms most gradient boosted tree algorithms, including CatBoost, but is sometimes beaten by XGBoost when tested on 6 publicly available datasets.
One interesting direction for NODE is to incorporate asymmetric trees in the layers, as it turns out, according to tests in the paper, that asymmetric trees perform better on some datasets than ODTs.
Conclusion
There is now an interest in developing deep neural networks that will hopefully unseat tree-based algorithms from their reigning status as the best learners on tabular data.
While these recent developments have been very exciting, I end on some practical considerations:
- Deep learning models that learn efficiently on tabular data allow us to combine them with state-of-the-art deep learning models in computer vision and NLP. This is a powerful advantage over gradient-boosted trees.
- Gradient-boosted trees can be efficiently trained on CPU, unlike their deep learning counterparts. They are also performant at inference time on CPU. Unless a deep learning model’s metrics are significantly better than gradient boosted trees (for example, 10% higher F1 score), the latter may still be more preferable as they are cheaper to train and deploy.
- Optimizing the feeding of data from a CSV file to the GPU is important if you want to optimize GPU utilization. Otherwise, it is very easy for the slow I/O operations of reading and creating batches from a large CSV file to starve your GPU.
- All these algorithms have a number of hyperparameters to tune. It is more practical to start with the simplest model you can find, and work your way from there.
[1] Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, Deep Residual Learning for Image Recognition, Proc. Computer Vision and Pattern Recognition (CVPR), IEEE (2015).
[2] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio, Generative Adversarial Networks, Proceedings of the International Conference on Neural Information Processing Systems (NIPS 2014), pp. 2672–268.
[3] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, Language Models are Unsupervised Multitask Learners (2019).
[4] Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova, BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (2018).
[5] Sercan Ö. Arık, Tomas Pfister, TabNet: Attentive Interpretable Tabular Learning (2019).
[6] Andre F. T. Martins, Ramon F. Astudillo, From Softmax to Sparsemax: A Sparse Model of Attention and Multi-Label Classification, Proc. 33rd International Conference on Machine Learning (ICML ‘16), vol. 48, pp.1614–1623 (2016).
[7] Poker Hand Dataset, UCI Machine Learning Repository (2007).
[8] Alex Graves, Adaptive Computation Time for Recurrent Neural Networks (2016).
[9] Sergei Popov, Stanislav Morozov, Artem Babenko, Neural Oblivious Decision Ensembles for Deep Learning on Tabular Data, International Conference on Learning Representations (ICLR) (2020).
[10] Ben Peters, Vlad Niculae, André F. T. Martins, Sparse sequence-to-sequence models, ACL 2019, pp. 1504–1519, (2019).
[11] Gao Huang, Zhuang Liu, Laurens van der Maaten, Kilian Q. Weinberger, Densely Connected Convolutional Networks (2017).





