
The Silent Information Transformation with LLMs: Building Knowledge Graphs with Maximum Automation
As AI permeates across industries, a silent transformation is underway in how AI systems are built.
Recent advances in LLMs have exposed their limitations around reasoning and grounding.
The exponential growth of data has brought both opportunities and challenges. While we create over 2.5 quintillion bytes of data daily, extracting value from this data remains difficult.
This is where knowledge graphs can play a transformational role — by structuring information to reveal insights.
However, building knowledge graphs manually is cumbersome. This article outlines how recent advances in large language models (LLMs) enable automating major portions of the knowledge graph construction process from unstructured data.
These trends underscore the need for structured knowledge in delivering accurate, safe and responsible AI applications.
Knowledge graphs fill this gap by encoding concepts and relationships in machine-readable ontologies to drive reasoning and semantics.
However, constructing massive enterprise knowledge graphs manually does not scale. This is where LLMs come in — by automating ontology extraction from unstructured corpora.
We detail a scalable methodology to generate high-quality knowledge graphs leveraging LLMs. But knowledge alone is not sufficient.
Emergent techniques like graph neural networks, node2vec and GraphSAGE operationalize knowledge graphs by learning powerful embeddings.
By coupling graph embeddings powered retrieval with LLMs in a RAG framework, requests are guaranteed to be grounded in truth. Any hallucinated claims can be automatically flagged through verification queries on the knowledge graph.
Beyond improved accuracy, knowledge graphs also equip LLMs with commonsense reasoning and multi-step inference. This holds the potential to elevate RAG systems from narrow AI to more general machine intelligence.
Together, Knowledge Graphs and Embeddings will form the bedrock of next-gen AI by grounding language models, enabling reasoning and semantics. They provide the infrastructure for machine knowledge representation — much like databases did for software systems.
Mastering this stack will become pivotal engineering expertise as AI becomes ubiquitous.
It unlocks enormous potential for performant and responsible AI across domains like healthcare, finance, science and sustainability.
The methodologies discussed form the blueprint for knowledge-driven AI.
LLMs and KG construction :
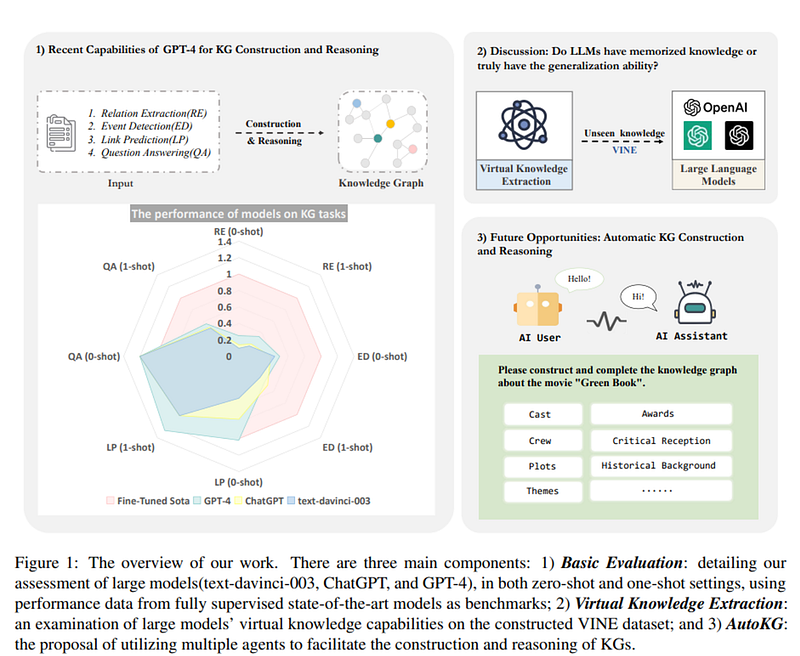
Zhu et al 2023 evaluates prominent LLMs such as ChatGPT and GPT-4 on various KG construction tasks like entity extraction, relation extraction, event extraction, and entity linking.
The performance of LLMs on KG construction tasks does not yet surpass specialized fine-tuned models developed specifically for these tasks. This is likely because KG construction involves multiple complex subtasks like named entity recognition and relation extraction :
- Relation Extraction (RE)
- Event Detection (ED)
- Link Prediction (LP)
- Question Answering (QA)
However, LLMs show promising capability improvements in one-shot and zero-shot settings over previous benchmarks. For example, GPT-4 demonstrates enhanced performance over ChatGPT in extracting relations from complex sentences.
There are several factors that currently limit the capabilities of LLMs for KG construction tasks, including dataset noise, semantic ambiguity, lack of type specifications, and prompt engineering.
The study introduces the concept of “Virtual Knowledge Extraction” to discern if LLM performance stems from memorized knowledge or true generalization ability. Initial findings indicate models like GPT-4 can rapidly acquire new extraction capabilities when provided sample instructions.
There are significant opportunities to enhance LLM capabilities for KG construction by optimizing prompt design, drawing on instructive examples for one-shot learning, accounting for dataset limitations, and leveraging human feedback.
While LLMs show promise for KG construction their capabilities do not yet exceed specialized systems. However, their ability to generalize provides optimism for future advancement in assisted and semi-automated KG construction pipelines.
Step 1: Set Up the LLM Pipeline
Open-source models like Zephyr 7B can be leveraged instead of commercial API-based models like GPT-3. Zephyr 7B is compatible with the Transformers library, allowing it to be used in a scalable pipeline.
For example:
# Install transformers from source - only needed for versions <= v4.34
# pip install git+https://github.com/huggingface/transformers.git
# pip install accelerate
import torch
from transformers import pipeline
pipe = pipeline("text-generation", model="HuggingFaceH4/zephyr-7b-alpha", torch_dtype=torch.bfloat16, device_map="auto")The LLama index combined with Neo4j functionality allows combining vector embeddings with graph data by indexing documents into a searchable store. The KnowledgeGraphIndex builder extracts triplets from text while storing embeddings:
from Llamaindex import LLMPredictor, KnowledgeGraphIndex
documents = SimpleDirectoryReader(
r"GraphCreation"
).load_data()
index = KnowledgeGraphIndex.from_documents(
documents,
query_keyword_extract_template=qa_template,
storage_context=storage,
max_triplets_per_chunk=20,
service_context=service,
include_embeddings=True
)This sets up an end-to-end pipeline leveraging Zephyr for text processing, with fine-tuning for information extraction, and LLama indexing for embedding powered search over the graph data.
The pipeline focuses on scalability via the Transformers and Llama inex libraries. Embeddings and incremental updates can enhance analysis.
II. Create Structured Extraction Guidelines
Step 1: Define Entity Types
Clearly specify the types of entities the LLM needs to extract (people, organizations, locations, medical conditions, etc.) along with definitions and examples of each entity type.
Step 2: Specify Relationships/Properties
Define the relationships and properties the LLM should identify between entities, providing schema examples. E.g. “employed_at”, “diagnosed_with”, “capital_of”
Step 3: Set Rules for Entity Resolution
Provide rules for how entities with similar surface forms should be resolved to canonical entities. Explain how to handle abbreviations, synonyms, alternate spellings, etc.
Step 4: Outline Numerical Data Handling
Instruct how to interpret and normalize numerical data — percentages, currency, measurements, etc. Specify any units that should be captured.
Step 5: Set Expectations for Output Structure
Show examples of the expected output structure — whether an ontology language like OWL, a graph query language like Cypher, or structured JSON.
Step 6: Include Corner Case Examples
Supplement guidelines with examples of complex inputs and how the LLM should handle them. Focus on areas humans also find tricky.
Step 7: Iterate on Real-World Cases
Test guidelines on actual samples from the target domain and update accordingly. The end guidelines should encode human logic.
By methodically building up these guidelines with concrete examples tailored to the application, we can tune LLMs to eliminate inconsistencies and errors in information extraction. This level of structure is essential for mapping unstructured data into clean knowledge graphs.
Example :
The overall goal is to define a template that instructs the language model how to extract ontology elements like classes, instances, and properties from text and output them in a structured format.
It starts by allowing the configuration of allowed node (entity) types and allowed relationship types:
doc = {
'allowed_nodes': [],
'allowed_rels': []
}
allowed_nodes = doc.get('allowed_nodes', [])
allowed_rels = doc.get('allowed_rels', [])This allows constraining the output schema to fixed sets of classes and relationships.
The template content explains the key elements to extract:
- Classes — Categories of entities
- Instances — Individual entities belonging to classes
- Properties — Attributes of and relationships between entities
It provides guidelines enforced by the prompt:
- Use consistent class labels
- Output human-readable instance IDs
- Handle numerical data and dates as properties
- Resolve coreferences
- Infer new knowledge from existing extraction
- Strict compliance with guidelines
The allowed nodes and relationships are inserted dynamically based on the config.
Finally, the template is wrapped into a Prompt object from LangChain for easy reuse:
qa_template = Prompt(template)
This template can now be utilized in Llamaindex pipelines to instruct models like LLMs to output ontology extractions in a structured format according to predefined guidelines.
from llama_index import Prompt
doc = {
'allowed_nodes': [],
'allowed_rels': []
}
allowed_nodes = doc.get('allowed_nodes', []) # Replace with your list of allowed nodes
allowed_rels = doc.get('allowed_rels', []) # Replace with your list of allowed relationships
template = (f"""
You are a top-tier algorithm designed for extracting information in structured formats to build an ontology.
- **Classes** represent categories or types of entities. They're akin to Wikipedia categories.
- **Instances** are the individual entities belonging to these classes.
- **Properties** define attributes and relationships between instances and classes.
Here are the guidelines you should follow:
## 1. Identifying and Categorizing Entities
- **Consistency**: Use consistent, basic types for class labels.
- **Instance IDs**: Use names or human-readable identifiers found in the text as instance IDs. Avoid using integers.
- **Allowed Class Labels:** {", ".join(allowed_nodes)}
- **Allowed Property Types:** {", ".join(allowed_rels)}
## 2. Defining Hierarchical Relationships
- Identify superclass-subclass relationships between classes. For example, if you identify "bird" and "sparrow", establish that "sparrow" is a subclass of "bird".
## 3. Handling Numerical Data and Dates
- Numerical data should be incorporated as properties of the respective instances or classes.
- Do not create separate classes for dates or numerical values. Always attach them as properties.
## 4. Coreference Resolution
- Maintain consistency when extracting entities. If an entity is referred to by different names or pronouns, always use the most complete identifier.
## 5. Inferring New Knowledge
- Use the existing information in the ontology to infer new knowledge. For example, if "sparrows" are a type of "bird", and "birds" can "fly", infer that "sparrows" can "fly".
## 6. Strict Compliance
- Adhere to these rules strictly. Non-compliance will result in termination.
""")
qa_template = Prompt(template)Instead, it relies completely on in-context learning, where the model is prompted to perform named entity recognition on a given input text by providing it a few examples of the task. So the parameters of GPT-3 itself remain fixed.
GPT-NER :
The key aspects of the approach are:
- Transforming NER into a text generation problem by having the model output special tokens around entities.
- Carefully designing the prompt with a task description, demonstrations, etc. to guide the model.
- Using an entity-level embedding technique to retrieve high-quality demonstration examples that are relevant to the input text.
- Adding a self-verification module to mitigate against GPT-3’s tendency to hallucinate non-existent entities.
GPT-NER shows how large pre-trained language models like GPT-3 can achieve strong performance on downstream tasks through prompt and demonstration design, without any fine-tuning or parameter updates. The authors leverage GPT-3’s capabilities as a few-shot learner here.
III. Tune the Model with Quality Datasets (optional)
Step 1: Create Labelled Training Data
- Sample representative text from the target domain (e.g. medical journals)
- Manually annotate entities, relationships, classes in the samples
- Create input-output pairs for LLM fine-tuning
For example:
Input: Penicillin is an antibiotic used to treat bacterial infections. It was discovered by Alexander Fleming.
Output:
{
"Instances": [
{"id": "penicillin", "type": "antibiotic"},
{"id": "Alexander_Fleming", "type": "person"}
],
"Relationships": [
{"from": "penicillin", "type": "used_to_treat", "to": "bacterial infections"}
{"from": "penicillin", "type": "discovered_by", "to": "Alexander_Fleming"}
]
}Step 2: Train and Evaluate Models
- Fine-tune language model (e.g. Zephyr) on labelled dataset
- Validate model accuracy on separate test set
- Plot metrics like precision, recall over time
- Compare models trained with different hyperparameters
- Select best performing model
Step 3: Iterative Improvement
- Identify error categories (e.g. parse errors, missed entities etc.)
- Expand training data with more examples fixing errors
- Retrain model and confirm metrics improve
- Repeat process until accuracy plateaus
This will tune the LLM to accurately extract key ontology components tailored to the domain, enabling high-quality knowledge graph construction.
IV. Extract Entities and Relationships
Step 1: Text Chunking
- Split input documents into small chunks of ~500 words
- Balance chunk size to provide context while ensuring entity resolution
chunker = TextChunker(chunk_size=500)
chunks = chunker.chunk(documents)Step 2: Ontology Extraction per Chunk
- Input each chunk text into fine-tuned LLM
- LLM executes extraction prompt template
- Outputs JSON with entities, relationships, classes
kg_extractor = Pipeline(model=zephyr, tokenizer=tokenizer, template=extraction_template)for chunk in chunks:
output = kg_extractor(chunk)Step 3: Post-process Extractions
- Normalize entity names, classes, IDs for consistency
- Attach metadata like source chunk ID
def process(extractions):
# normalize, attach metadata etc
return processed_extractionsoutputs = [process(o) for o in outputs]Step 4: Quality Checking
- Spot check extractions
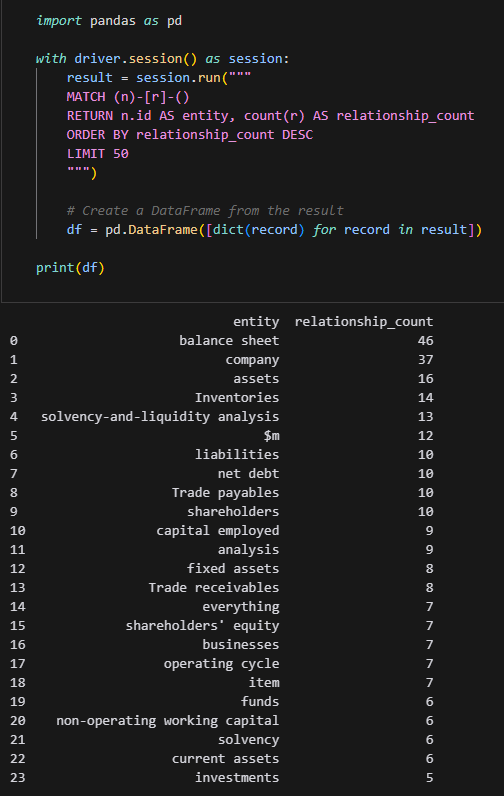
- Identify systematic errors through small sample audits
- Retrain LLM on errors if needed
Entity Disambiguation
Since text chunks are processed independently, the same real-world entity can be extracted with slight variations across chunks. This causes multiple nodes representing the same entity.
Some solutions:
- Entity linking models
- Second LLM pass focused on disambiguation
- Graph algorithms to cluster duplicate nodes
This is a critical step for accuracy. Without it, downstream applications on the knowledge graph become less effective.
import openai
from tqdm import tqdm
# Improved disambiguation prompt
disambiguation_prompt = """
You are an AI model specialized in entity disambiguation. Your task is to identify which values reference the same entity.
For instance, if I provide you with the following entities:
- Apple Inc.
- Apple
- Microsoft
You should return:
- Apple Inc., 1
- Apple, 1
- Microsoft, 2
This indicates that 'Apple Inc.' and 'Apple' refer to the same entity (1), while 'Microsoft' refers to a different entity (2).
Now, process the following entities:
"""
from openai import OpenAI
def disambiguate(entities):
client = OpenAI(api_key='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') # replace 'your-api-key' with your actual OpenAI API key
completion = client.chat.completions.create(
model="gpt-3.5-turbo-16k-0613",
messages=[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": disambiguation_prompt + "\n".join(entities)
}
]
)
return completion.choices[0].message.content
# Get all node names from the updated graph
driver = GraphDatabase.driver(url, auth=(username, password))
with driver.session() as session:
result = session.run("MATCH (n) RETURN n.id AS name")
node_names_updated = [record['name'] for record in result]
# Disambiguate the node names
disambiguation_results_updated = []
for name in tqdm(node_names_updated, desc="Disambiguating entities"):
disambiguation_id = disambiguate(name)
disambiguation_results_updated.append((name, disambiguation_id))
# Print the disambiguation results
for result in disambiguation_results_updated:
print(result)
# Update the graph with the disambiguation results
for name, disambiguation_id in disambiguation_results_updated:
escaped_name = name.replace("'", "\\'") # Escape single quotes
query = f"MATCH (n) WHERE n.id = '{escaped_name}' SET n.disambiguation_id = '{disambiguation_id}'"
print(query)
with driver.session() as session:
session.run(query)Step 5: Consolidate Chunk Graphs
- Maintain mappings of coreferring entities across chunks
- Resolve to canonical entities
This pipeline robustly processes large volumes of text, leveraging the fine-tuned LLM to extract ontology triplets from each chunk, while ensuring quality.
V. Build the Final Knowledge Graph
Step 1: Node and Edge Consolidation
- Maintain a mapping of canonical node IDs
- Replace any duplicate node IDs across chunks with canonical ID
- Consolidate duplicate edges into a single edge
- Sum edge weights when consolidating
This eliminates duplicates and creates a unified node and edge set.
def consolidate(graphs):
nodes, edges = {}, {}
for g in graphs:
map_nodes(g, nodes)
map_edges(g, edges)
return build_graph(nodes, edges)Step 2: Attach Metadata
- Store source document ID, chunk ID, etc as node/edge properties
- Timestamp extraction date, model version etc.
- Enables tracking provenance
def tag_metadata(graph):
for node in graph.nodes:
node['extracted_on'] = datetime
node['source_doc'] = doc_id
for edge in graph.edges:
edge['model_version'] = 2.1Step 3: Graph Analysis
- Community detection to find related node clusters
- Centrality measures like PageRank to ID important nodes
- Visualize communities and centralities
communities = community_detection(graph) pageranks = pagerank(graph) visualize(graph, communities, pageranks)
Step 4: Knowledge Graph Store
- Bulk load consolidated property graph into Neo4j
- Optimized for complex analytics queries
- Scales to enterprise data
This brings together extracted knowledge from all documents into an integrated, analytics-ready knowledge graph with metadata tracking and community topological analysis.
VI. Benefits Over Manual Approaches
The methodology automates ontology development from unstructured data at scale. It saves thousands of human hours otherwise required for manual reading, labeling and linking. Being programmatic enables easier debugging, metrics-driven iteration and integration of emerging LLMs. The final knowledge graph is primed for analytics.
High Volume Scalability
- LLMs process thousands of documents per hour
- Scales linearly with compute resources
- Human review bandwidth is bottleneck for manual labeling
Rapid Iteration and Improvement
- Model correctness metrics guide LLM retraining
- Frequent model updates possible, unlike manual process
- Enables leveraging latest LLMs like GPT-4
Easier Debugging
- Granular extraction logs point to error sources
- Fixing requires prompt and dataset changes
- Hard to diagnose human errors
Structured Analytics Enablement
- Query explicitly defined schema and properties
- Knowledge inference through semantic queries
- Ad-hoc queries not feasible with unstructured data
Consistency and Reuse
- Precise guidelines maximize ontology consistency
- Extraction reproducibility enables incremental addition
- Manual process prone to semantic drift
The LLM automation provides order-of-magnitude efficiency gains over manual labeling, while knowledge graph integration and queryability unlocks previously inaccessible insights.
The rapid iteration, metric-driven improvements and emerging LLM integration further differentiates this methodology from traditional ontology engineering.
VII. Use Cases and Limitations
LLM-based knowledge graph construction shines for large document corpora where manual labeling is infeasible.
Applications include medical research, legal contracts, customer engagement systems and financial reports. However, output quality hinges on training data and guidelines.
Using LLMs as black boxes can propagate unintended biases. A hybrid human-LM approach with checks and balances is prudent.
Looking Ahead As LLMs become robust at multimodal information extraction spanning text, images, speech and video, the methodology will grow more versatile.
Immediate opportunities lie in iterative knowledge graph construction — where existing graphs are automatically updated as new documents are ingested.
Such self-supervised Lifelong learning approaches will usher the next evolution in extracting intelligence from exponentially growing information.
Bonus : AutoKG, a multiagent framework
AutoKG which utilizes multiple conversational agents to automatically construct and reason about knowledge graphs.
Main Function
- Sets up the assistant and user roles, defines a sample task prompt, and specifies the conversation flow using the
starting_convoandget_sys_msgsfunctions.
CAMELAgent Class
- Defines an agent that can participate in conversations by maintaining context, stepping through messages, and querying an underlying chat model (ChatGPT) to generate responses.
Starting Conversation
starting_convoinitiates the conversation by asking the assistant agent to specify the initial task.get_sys_msgsthen sets up the initial system messages that define the role, task, and conventions for the assistant and user agents.
Conversation Loop
- The main loop manages a conversation between the assistant and user agents, stepping each one to generate responses.
- The assistant agent has the ability to retrieve supplementary information from search to aid in responding.
Retrieval Agent
Retrieval_Msgdefines an agent that can specify a focused search query based on the current conversation and task.- It then retrieves summarizations and facts from the search results to enhance the assistant agent’s knowledge.
AutoKG employs multiple conversational agents with differentiated capabilities (conversation, retrieval etc) to automate the process of constructing and reasoning about knowledge graphs via an assisted dialogue. The system manages role assignments, task prompting, information retrieval, and response generation to complete the specified knowledge graph construction task.
task_specifier_prompt:
- This prompt is used by the
starting_convofunction to ask the assistant agent to specify the initial task in more detail. - It instructs the assistant to restate the task, while being creative and imaginative, in a constrained number of words.
assistant_inception_prompt:
- This prompt sets up the initial system message for the assistant agent, defining its role, relationship with the user agent, guidelines for solving the task through a collaborative dialogue.
user_inception_prompt:
- Similarly, this prompt defines the initial system message for the user agent, explaining its role as the instructor providing guidelines and inputs to help the assistant agent complete the task.
retrieval_specifier_prompt:
- This prompt is used to ask the assistant agent to formulate a focused search query based on the current task and conversation, in order to retrieve supplementary information from the web.
HumanMessagePromptTemplate:
- This is a template class used to parameterize and format prompt templates to generate
HumanMessageinstances, which contain the formatted message text.
SystemMessagePromptTemplate:
- Similarly, a template to generate
SystemMessageinstances which contain the initial instructions for the agents.
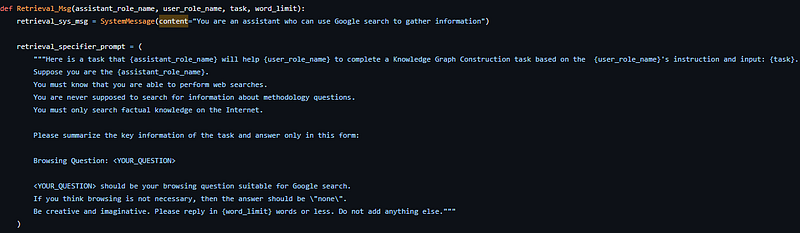
AutoKG uses specialized prompts for task specification, role inception, and information retrieval by assistant and user agents. Template classes help parameterize and generate these prompts to set up the conversational flow. The prompts provide precise instructions to agents on how to collaborate to construct knowledge graphs.

PlainEnglish.io 🚀
Thank you for being a part of the In Plain English community! Before you go:
- Be sure to clap and follow the writer️
- Learn how you can also write for In Plain English️
- Follow us: X | LinkedIn | YouTube | Discord | Newsletter
- Visit our other platforms: Stackademic | CoFeed | Venture



