
The Shift in AI Trends: Keep Up with LLM / NLP in 2023 (Summary)
This blog provides a high-level overview of the shift in AI trends and does not cover all the nuances and details of the subject matter.
Artificial Intelligence (AI) has witnessed remarkable advancements in recent years, with researchers continually pushing the boundaries of what is possible. One notable trend in AI has been the development of novel architectures, such as transformers and visual transformers, which have revolutionized various domains. However, there is a noticeable shift in the current AI landscape towards the optimization of large models, particularly Language Models (LMs) like GPT. There have been so many papers that it is getting difficult to keep up with the trends.
In this blog, we will explore the recent trends and provide useful papers for you to stay updated with this crazy area.
Large Language Models
Large Language Models (LLMs) have emerged as an unrivaled force. OpenAI was at its infant stage as Transformer was introduced to the world. Inspired by Transformer, OpenAI came out with their own model that explored the potential of Generative Pre-Training method, which later developed into the famous ChatGPT. And as technology progresses, OpenAI released their largest LLM model (GPT-3) in June, 2020 with 175 billion parameters.
Following the mainstream sensation ChatGPT, LLMs have transformed from an obscure AI model to becoming conversational topics for non-tech folks. The year 2023 is predicted to witness an even wider adoption of this technology, creating a likely battleground for huge companies like Microsoft and Google.
Industry: Google and OpenAI
That said, 2023 is expected to bring significant developments. Firstly, Google’s public use of their FLAN family of models will create an impact. Secondly, OpenAI, along with its challengers, is likely to tackle the trillion scale parameter count with the much-anticipated GPT-4, provided all optimization challenges are successfully addressed. While the cost implication may restrict these models from primarily powering LLMs as a Service, they will feasibly become the next headline-making tech in AI.
Open Science & Open Source
As part of Meta’s commitment to open science, they publicly released LLaMA (Large Language Model Meta AI), a state-of-the-art foundational large language model designed to help researchers advance their work in this subfield of AI. Smaller yet more performant models such as LLaMA enable others in the research community who don’t have access to large amounts of infrastructure to study these models, further democratizing access in this important, fast-changing field.
Being smaller than many other models, one of the main advantages of LLaMA is that it is more cost-efficient than other models, which makes it more accessible to a wider range of users. Additionally, It is more accessible to researchers and other organizations because it is available under a non-commercial license.
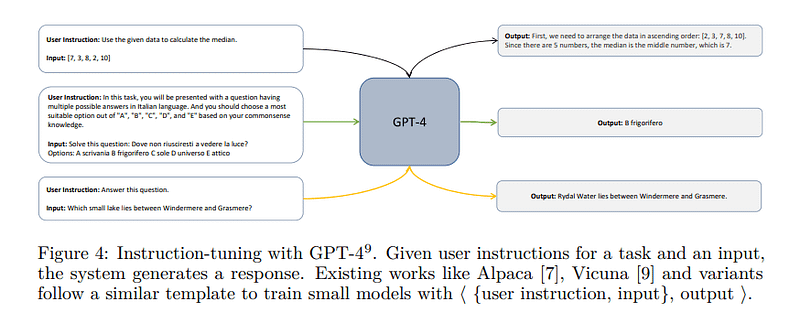
Microsoft, unexpectedly, has presented Orca, an open-source much-smaller-than-ChatGPT model that, using an innovative training method. Orca is a 13-billion parameter model that learns learns from rich signals from GPT-4 including explanation traces; step-by-step thought processes; and other complex instructions, guided by teacher assistance from ChatGPT. ORCA became the first model to ever outpace ChatGPT on Vicuna’s benchmark.
Bloom is a decoder-only Transformer language model and the world’s largest open-science, open-access multilingual large language model (LLM) with 176 billion parameters. The model was trained on a large amount of text data using industrial-scale computational resources in 46 natural languages and 13 programming languages. Bloom achieves competitive performance on a wide range of benchmarks, with even stronger results after multitask prompted finetuning.
LLM Optimization
Researchers at Google show how to leverage LLMs for Language Model distillation and potentially outperform LLMs and task-specific supervised models.
- The approach outperforms both fine-tuning and distillation with upto 85% lesser data
- The models are upto 2000x smaller than LLMs
- The approach simultaneously uses smaller models and dataset size
- Smaller models still outperform LLMs with only unlabelled data too
Researchers at Microsoft propose a method called Low-Rank Adaptation (LoRA) for natural language processing.
- LoRA aims to reduce the number of trainable parameters and GPU memory requirements for downstream tasks.
- Compared to fine-tuning, LoRA can reduce trainable parameters by 10,000 times and GPU memory requirements by 3 times.
- Despite having fewer trainable parameters, LoRA performs on-par or better than fine-tuning on various language models.
- The approach of using smaller models and dataset size simultaneously outperforms both fine-tuning and distillation with up to 85% less data.
- The researchers also investigate rank-deficiency in language model adaptation, shedding light on the effectiveness of LoRA.
Researchers at Meta propose LIMA, a 65B parameter LLaMa language model.
- LIMA is fine-tuned with the standard supervised loss on only 1,000 carefully curated prompts and responses, without reinforcement learning or human preference modeling.
- LIMA shows strong performance, learning to follow specific response formats from only a handful of examples in the training data.
- The model also generalizes well to unseen tasks that were not in the training data.
- In a controlled human study, responses from LIMA are either equivalent or preferred to GPT-4 in 43% of cases.
- When compared to Bard and DaVinci003, which were trained with human feedback, LIMA is preferred in 58% and 65% of cases, respectively.
- These results suggest that almost all knowledge in large language models is learned during pretraining, and only limited instruction tuning data is needed to produce high-quality output.
Existing methods for gaining steerability collect human labels of model generations and fine-tune the LM using reinforcement learning from human feedback (RLHF). RLHF is complex and unstable, involving fitting a reward model and fine-tuning the unsupervised LM using reinforcement learning. Direct Preference Optimization is a novel approach to training LMs given a dataset of the form
- DPO is stable, performant, and computationally lightweight, eliminating the need for reward model fitting, sampling from the LM, or hyperparameter tuning.
- Experimental results show that DPO can fine-tune LMs to align with human preferences as well as or better than existing methods.
- DPO outperforms RLHF in controlling sentiment of generations, improves response quality in summarization and single-turn dialogue, and is simpler to implement and train.
Community
For more papers around LLM, there are many threads and forums where people share useful works. One of them is LinkedIn provided you connect/follow people in the industry. Another option I found is the following forum:
where people share papers they found insightful regarding the recent trends in LLM.
Pytorch introduces ultra-low latency inference on LLaMA, the powerhouse language model accelerated by PyTorch/XLA on Google Cloud TPU! 💪✨
They have turbocharged the inference latency of the LLaMA 65B parameters model by 6.4x.
Lightning AI launched a fully open-source (Apache 2.0) implementation of LLaMA.
Some Last Words
Significantly, the progress in LLMs will have beneficial cascading effects on other AI fields like Computer Vision, Information Retrieval, and Reinforcement Learning, as observed in 2022.
A key area where LLMs have already made an impressive impact is coding. For over a year, GitHub Copilot, backed by an LLM, has been subtly redefining the manner in which coding is undertaken. Google revealed in 2022 that 3% of its coding was already being done by LLMs. Given continuous advancements, it’s conceivable that code completion via LLMs will extend this trend, leading to an evolutionary shift in coding practices.

In conclusion, the central role of LLMs in the AI landscape is becoming more crucial. With technological titans vying for a piece of the pie, LLMs’ impact across various fields such as coding and other AI domains is only set to widen in the future.