
The Secret Sauce Behind Spotify Recommendations

Have you ever been listening to a playlist on Spotify, and when it ends Spotify keeps playing absolute quality songs? I’ll be honest, I’ve found more of my favourite songs that way than from my friends “great” recommendations. It’s almost as if Spotify knows me better than my friends…
I wanted to find out more about how Spotify categorizes and analyzes music and how it doesn’t miss the mark with its song recommendations. But first things first, I needed to collect some data.
Designing The Data Schema:
I decided to design and build my own dataset so I can comfortably run SQL queries against it and draw some conclusions. The best way to do that is using Spotify’s developer API: https://developer.spotify.com/documentation/web-api/reference/#/
From their API documentation (which is impeccable by the way), I found out what data I wanted to analyze:
- Tracks (songs): their popularity and release dates, this will help me find if theres a pattern between a songs audio qualities and its popularity, and how that has evolved over time
- Audio attributes: Spotify assigned each track audio attributes that describe its basic elements, I decided to focus on these three: danceability, valence and energy.
- Playlists: genres, dates, followers and its tracks. What makes a playlist flow? What makes a genre a genre?
- Artists: popularity and followers. I wanted to see if there’s a correlation between the type of music an artist releases and the artist’s popularity, but this is difficult because an artist can release varying types of music.
From this information I designed a schema that obeys the basic ideas around database design: reduce duplicated information, reduce nulls and keep the tables connected.
The Relational Schema
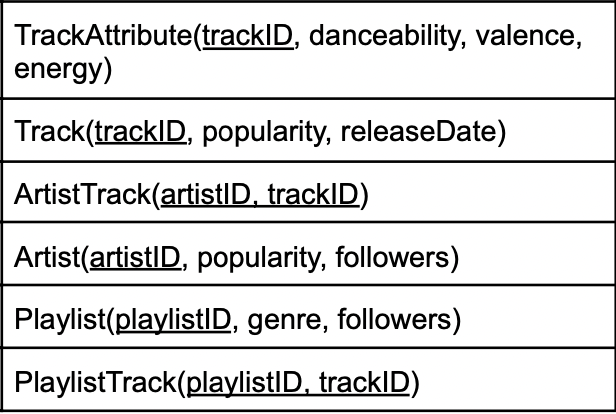
For those who aren’t familiar with relational schemas, underscores denote the key of that table. For example, the Track table has the trackID key, meaning no two tracks in that table can have the same trackID, but they can have the same popularity. PlaylistTrack has a composite key, meaning that PlaylistTrack may have multiple items with the same trackID (meaning the same track can be repeated), but that trackID cannot exist with the same playlistID more than once.
I considered adding the data dictionary and integrity constraints here, but I decided against it because I didn’t want this to become a pure relational database post. Let me know if you want to see the full design of the database and the data I collected!
Using Python To Collect & Clean Data
I used Python in the Google Colab environment to collect the data and save it into csv files to run SQL queries on. It was fairly simple after navigating the Spotify API documentation, here are some blocks of code I wrote to extract the data:
These are only some of the code blocks I wrote to aggregate the data. The process is tedious but straightforward: get authorization headers and them to make requests to the Spotify API. Useful tip: don’t run Spotify API requests in a loop, eventually, after a couple of dozen requests or so, Spotify will stop responding to your requests. If you do want to run it in a loop, then use a delay between API requests.
After collecting the data, I was ready to run my queries and answer some of the main questions I had about how Spotify operates, and how people consume music.
Questions & Results
Question 1: do different genres inherently have different energy levels?
In other words, is a genre mainly characterized by the amount of energy in its songs? Intuitively that makes sense, I listen to smooth jazz when I want to unwind, but would be embarrassed to play anything other than EDM and hip hop at a party. I ran a few SQL queries to do some aggregation and got the following result:

Some of the results matched my expectations, for example classical music having a significantly lower energy levels than the other genres. However, it was interesting to see that some genres which I would consider calm, such as Smooth Jazz, had a max energy and average energy near that of Hip Hop and higher than R&B. Somehow though, the maximums and minimums varied greatly for energy levels for the genres, indicating that generally, a genre isn’t defined by its energy levels. This pattern also follows for danceability and valence. So, are these attributes related somehow?
Question 2: Are The Different Track Attributes Related?
It seems that since they followed a similar trend, they might correlate. To answer this question, I ran a few queries to find the differences between energy levels, danceability and valence for every track and aggregated them into some tables:

Intuitively, we know that the lower the difference between two measurements the more similar they are. However, using the linear measurement would be ill-advised; for example if the difference is 0.1, does that indicate high similarity or low similarity? If we are comparing energy and valence for example with the respective measurements of 0.9 and 0.8 we would consider those more similar than if they were 0.2 and 0.1, as the difference of the first example is proportionally lower than the second. To adjust for this, I measure the difference against a percentage of the track attributes value. If the difference is within 5 percent inclusive of the value, I categorize that the similarity is high, if it’s between 5 and 15 percent then it is similar but not highly similar, and anything above 15 percent I consider not similar.
At first sight, these results indicated that the track attributes are largely unrelated, as the not similar numbers dominate the similar numbers, for example energy_dance_not_similar stands at 616 while energy_dance_very_similary is only 74 and energy_dance_similar is 121. However, the sum of the very similar and similar results yield 195, which is 24% of the data in the range of 15% proportionate to the track attribute, which shows that the track attributes are somewhat related, but not necessarily strongly related.
I suppose this makes sense, one of the happiest songs of all time (at least in my opinion), Three Little Birds by Bob Marley, is both low energy and would be challenging to dance to, to say the least. But in general, most upbeat, high energy songs are happy and easy to dance to.
Question 3: Are more popular artists releasing songs that are happier?
Finally, I wanted to know what made artists popular. Are artists that release high energy, happy songs generally more popular and successful? Could I be a successful artist despite having a horrible voice if I just make the songs really cheerful? (I was really hoping for a yes here)
I began investigating this question by grouping the artists tracks with their artists, followers and popularity, and then grouping the result of that with the track attribute of valence, which is Spotify’s measure of happiness per song. I then quickly realized that perhaps it would be wise to add the other track attributes of energy and danceability as well to investigate which track attribute influences artist popularity more. I then averaged the track attributes against the artists, which will give a better measurement as my hypothesis is that artists who consistently release happier songs will rank higher in followers and popularity. I plotted the results and received the following plots:
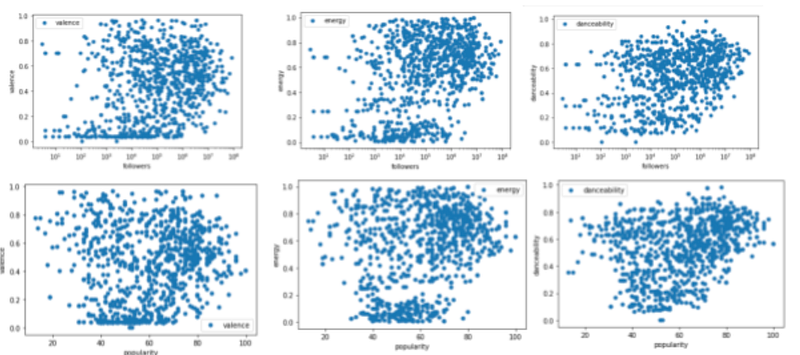
From these graphs we can draw some conclusions; having high measurements of danceability, energy and valence does not guarantee success for artists, there are many artists with relatively low followers and popularity who score high on energy, danceability and valence. However, for artists with the most followers and highest popularity, we can see that the scatter plots for danceability and energy trend upwards, meaning that more popular and more followed artists tend to make tracks that are more energetic and easier to dance to. The same cannot be said for valence however, as we can see the scatter plot for valence is generally normally distributed so no relationship can be asserted between popularity and valence.
In conclusion, its unlikely that my horrible voice will attract a lot of followers, even if the song is extraordinarily upbeat, because upbeat songs aren’t necessarily a recipe for success despite the most popular performers generally releasing happy songs.
Final Thoughts
I answered some basic questions here from the data I gathered from Spotify, but there’s a lot more to investigate. Spotify uses a bunch of the aforementioned track attributes and metrics to recommend songs to users according to what they’ve been listening to, and they’re not shy about letting developers use their data for their own purposes.
In this article I didn’t dive too deep in any one technical area, but instead gave some general information about how I designed my data set and how I collected the data. Let me know if you’d like me to dive into more detail regarding my SQL queries, Python code or relational database design!
If you’ve enjoyed reading this I’d really appreciate a follow!





