
State of The AI Art March 2023
The Secret Code: How Watermarking Can Make Large Language Models Safe
Protecting Our Digital World: Watermarking chatGPT

In a world where large language models (LLMs) like ChatGPT can write documents, create code, and answer questions, there’s a growing concern about the potential harm they can cause. The risks are real, from social engineering and election manipulation campaigns to the creation of fake news and web content. But what if there was a way to mitigate these risks?
State of The AI Art March 2023
Enter the “watermarking framework” proposed by a group of researchers. This involves embedding signals into generated text that are invisible to humans but algorithmically detectable. The watermark selects a randomized set of “green” tokens before a word is generated and softly promotes using those tokens during sampling.
Battling the Dark Side of Language Models: A Watermarking Revolution
The best part? The watermark can be detected without knowledge of the model parameters or access to the language model API. This allows for open-source detection algorithms, which are cheap and fast because the LLM doesn’t need to be loaded or run.
But how effective is this watermarking framework, really?
The researchers tested it using a multi-billion parameter model from the Open Pretrained Transformer family, and the results were promising. The watermark is computationally simple to verify, false positive detections are statistically improbable, and the watermark degrades gracefully under attack.
Of course, some open questions remain about the best way to implement and tune the watermarking framework against generative attacks, but the potential benefits are clear. This framework could be a crucial step toward reducing the harm caused by large language models by enabling the detection and auditing of machine-generated text.
Protecting the Future: A Watermark for Large Language Models
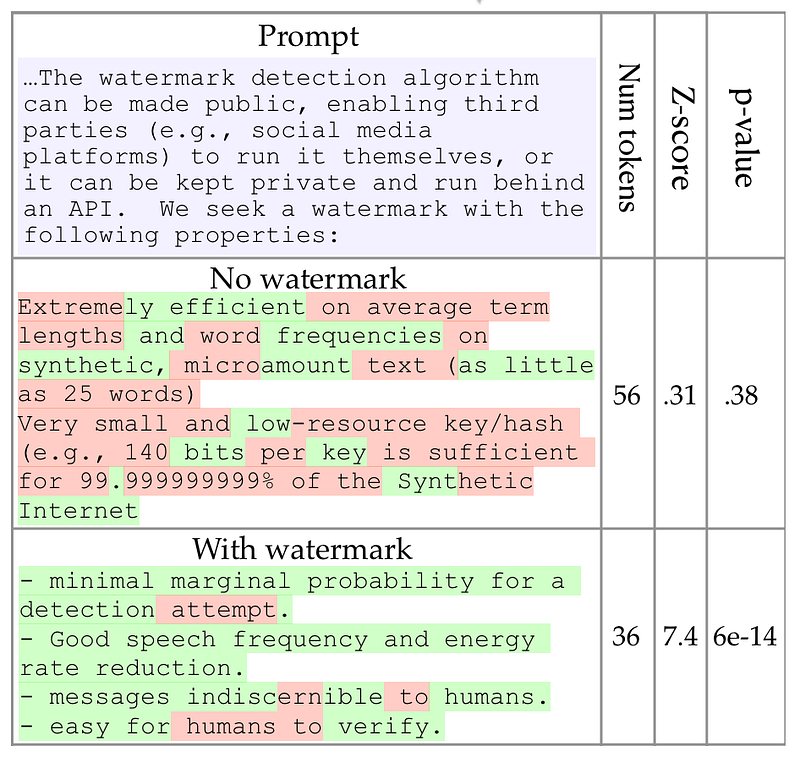
Language model outputs, both with and without the use of a watermark. The watermarked text should have 9 “green” tokens if authored by a person, yet it has 28. The odds of this happening by chance is 6 1014, making us almost likely that this text was created by a computer. Words are distinguished by their color. The model is OPT-6.7B, and it employs multinomial sampling. The watermark parameters are, = (0.25, 2). The prompt is the entire text in blue below.

And there’s one more thing that makes this watermarking framework particularly exciting: its flexibility. It can be retrofitted to any existing model that generates text via sampling from the next token distribution without retraining. And different context-specific δ choices or green list enforcement rules can be used for different kinds of text or models, all while using the same downstream watermark detector.
The Key to Responsible AI: A Watermarking System for Large Language Models
In short, the watermarking framework proposed by these researchers could be a game-changer in mitigating the potential harm caused by large language models. While some questions remain to be answered, the potential benefits are clear. Furthermore, with careful implementation and tuning, this framework could be crucial for ensuring that machine-generated text is used responsibly and ethically.
Best AI Detector Tools: Unraveling the ChatGPT Text Scandal — The Essential Guide to AI Content Detectors
Prompt Engineering: The Career of Future
AI is everywhere, But the question is, how much do you love it?
I invite you to explore the concept of Machine Learning Art by reading and learning from the many articles found on 🔵 MLearning.ai 🟠
Check out my instagram with new material every week
- If you enjoyed this, follow me on Medium for more
- Want to collaborate? Let’s connect on LinkedIn
- https://linktr.ee/datasculptor
- 3D Machine Learning generated model on sketchfab
Keywords: computer vision, Artificial Intelligence, Machine Learning, AI art, art, wombo dream, digital art, Dalle 2, Imagen, wombo ai, Parti, 3D point cloud, diffusion models, generative art, wombo art, photographic quality, img by AI system, AI art generator, text to art generator, 3D, midjourney, dalle2, stablediffusion, Dalle 3, vision-language model, AI artists

Project Page:
https://arxiv.org/pdf/2301.10226.pdf
A Watermark for Large Language Models
John Kirchenbauer Jonas Geiping Yuxin Wen Jonathan Katz Ian Miers Tom Goldstein




