
The Project I Did to Land My First Data Scientist Job

Introduction
Embarking on a career as a data scientist can be a daunting journey, filled with countless applications, interviews, and rejections. However, among all the challenges I faced, there was one significant turning point that paved the way to my first data scientist job — a machine learning test that not only showcased my technical skills but also demonstrated my ability to solve real-world problems using data-driven insights. In this post(my first medium post), I will share how I approached the test and the specific steps I took for the model training.
First of all, let me share my background before digging into the details of the test.
My Background
TLDR: 1. I had done machine learning projects when I was still a data analyst 2. I learned the machine learning techniques through Kaggle and a book
Before landing my first data scientist job, I had been working as a senior data analyst, where I had already dipped my toes into the world of machine learning. Even though my responsibilities primarily revolved around data extraction, visualization, and reporting, I eagerly sought opportunities to incorporate machine learning techniques into my projects. This allowed me to gain practical experience in handling and analyzing datasets, implementing algorithms, and deriving meaningful insights to inform business decisions.
Open books open minds; never stop seeking truth
Equipped with a Bachelor’s degree in Statistics and a Master’s degree, I had a solid foundation in quantitative analysis. However, my formal education alone wasn’t enough to transition seamlessly into the field of data science. Like many aspiring data scientists, I turned to online platforms such as Kaggle to expand my skill set. Kaggle provided an incredible learning resource, enabling me to participate in competitions, collaborate with like-minded individuals, and explore diverse datasets. You can learn so much by simply going through the work of others. I was also reading the book — “Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems by Aurélien Géro”, this is the best book for a beginner! Of course, there are numerous excellent books available. You may select any book of your choice. The key is to commence reading and concentrate on one book at a time.
During this time, my dedication and continuous learning efforts paid off when I received my first data scientist job interview opportunity.
The company that ended my loop

As someone who has recently gone through the process of applying for jobs, I can certainly appreciate companies that are willing to give candidates without extensive experience a chance at an interview. I was fortunate enough to encounter a company (AM) that saw beyond the conventional barriers. This remarkable company stands out as a beacon of opportunity and inclusivity, recognizing the value of potential, passion, and dedication over a rigid checklist of past positions held. AM has not only offered me a chance to prove myself but has also instilled in me a sense of hope and optimism that the right opportunities are out there for those willing to learn and excel.
It’s important to recognize that not all DS jobs are directly related to data science and machine learning. There are various roles that involve only data analysis or business intelligence. One way to distinguish data science-focused positions is by looking for companies that include a test as part of their interview process which is what AM did. These tests indicate that the company places a strong emphasis on evaluating candidates’ technical skills, problem-solving abilities, and ability to apply data-driven approaches. By identifying these companies, aspiring data scientists can align their job search with roles that provide a suitable environment for their skills and goals.
Before we continue, please consider clapping, subscribing to stay updated, and leaving your valuable comments. It would be a great motivation for me to continue writing more articles. Thanks!
The take-home project

As part of the interview process, I was assigned a 3-day take-home project accompanied by a presentation of my findings to the hiring team. They gave me a data set that is related to crabs but long after I realized it is the same data as the famous Abalone Data Set. Let's assume it is still the crab data set as I will show you the whole project the same as what I did during that time.
Tasks
AM asked for 4 main tasks for this dataset:
- Build a model that can predict the age of crabs
- write a prediction program to do batch predictions by command and output the prediction results
- write an evaluation program that can be executed by command and output a text file with necessary statistics/ metrics
- present the results (with actionable insight)
It was a great test covering nearly all aspects of data science: not only the ability to build models but also the ability to write production-level code and business acumen.
Instead of showing you the code step-by-step, I will talk about my thought process on each step. If you are interested in knowing more, you can check my code on GitHub. I will also go through some mistakes I made when doing the test.
Model Training
To be honest, it wasn’t difficult to build the model. After all, it was just an abalone dataset. The main goal for this task was to showcase your understanding of the ML model development process. The steps I did:
- Exploratory Data Analysis (EDA) I analyzed and visualized data to uncover patterns, identify outliers, and gain insights into the underlying structure of the dataset.
- Data Cleaning I used the findings from EDA to clean the data, such as removing the outliers identified.
- Feature Engineering In this phase, creativity and data comprehension are essential. The dataset comprises physical measurements of crabs, including height, weight, and diameter. To enhance predictive power, I engineered features such as “size” (calculated as length * diameter * height) and “density” (whole weight/size). These engineered features emerged as strong predictors, further illustrating the value of feature engineering in extracting meaningful insights from the data.
- Model Training In this test, I focused on comparing two standard tree-based models: Random Forest and XGBoost. The objective, again, was not to build the best-performing model but to demonstrate a solid understanding of the process. Additionally, I deliberately chose these models to encourage interviewers to inquire about the differences between them, which they did! I conducted a grid search with cross-validation for hyperparameter tuning. While I had the flexibility to choose from a range of models and methods, it was crucial to keep in mind that I might be asked about the underlying concepts.
- Model Evaluation In this context, I focused on using regression-related metrics, such as MAE (Mean Absolute Error) and RMSE (Root Mean Square Error). I deliberately opted for these metrics to maintain simplicity and ensure my ability to explain them effectively.
Building the script
It is quite common for machine learning projects to stagnate during the model evaluation phase, often leading individuals to believe that their work ends there. However, one critical aspect of successful data science lies in bridging the gap between experimentation and real-world deployment. I encountered this challenge during the test as well. Converting my code from a Jupyter Notebook format to a .py file and making it executable through commands became the initial hurdle.
cat ../data/test_data.csv | python prediction_model.py | python evaluation.py > stats.logLooking back, there were some crucial aspects of code productionization that I overlooked. If I were to approach it again, I would make sure to address the following points:
- Make a better directory structure instead of putting all components in one folder
- Include the requirements.txt for reproducing the same working environment
- Implement logging and error handling to capture relevant information and errors during code execution
Business Use Case
Undoubtedly, this is a pivotal aspect that holds significant importance in most projects. You built a model to predict the age of crabs and so what?
The original motivation behind the abalone data project was to leverage physical measurements to predict the age of abalone, eliminating the need for tedious tasks like manually counting the number of rings under a microscope. This approach had a significant business impact as it saved valuable time and resources.
But how does knowing the age of crabs prove useful? Putting myself in the shoes of a crab fisherman, I would inquire:
- How can I maximize that profit for every fishing?
- How can I ensure that I can continue fishing in the same location in the future?
To address these challenges, it is crucial to implement strategies to prevent overfishing. This entails allowing sufficient time for crabs to grow and reach maturity before being caught. By practicing responsible fishing, we can ensure a sustainable crab population and maintain the viability of fishing in the same location over the long term.
But what age is considered mature enough? By examining a simple plot, we can observe that crabs typically stop growing around the age of 11. This suggests that the optimal fishing time might be when the majority of crabs reach the age of 11. We can gain insights into this by analyzing the distribution of crab ages, which would provide valuable information for determining the best fishing practices and ensuring the sustainability of the crab population.
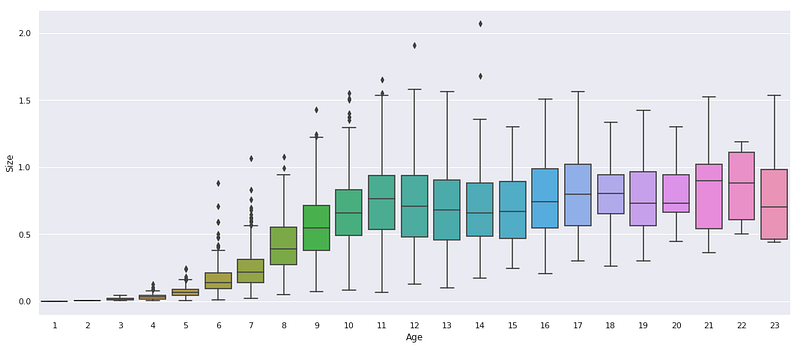
But how can we determine the distribution? One approach is to leverage the model to approximate the distribution by following these steps:
- Randomly sample crabs from a specific area.
- Utilize the model to predict the age of the sampled crabs.
- Approximate the distribution by analyzing the predicted age values.
By employing this method, we can gain insights into the age distribution of the crab population, which aids in understanding the optimal fishing time and implementing sustainable fishing practices.
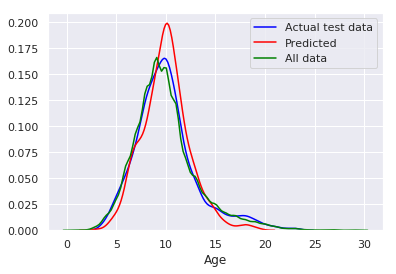
The remarkable similarity in the distributions of predicted age, actual age from the test group, and age from the entire dataset demonstrate the model’s accuracy in estimating the age of crabs. This consistency reinforces our confidence in the model’s reliability and its potential to inform sustainable fishing practices.
Another approach is to estimate the mean age and calculate the confidence interval of the actual mean. This method leverages the law of large numbers and the central limit theorem (CLT), the fundamental principles in A/B testing, to ensure reliable results.
However, I omitted further discussion on the monetary impact, including the potential for increased earnings by harvesting mature crabs and the prevention of economic losses from overfishing. Ensuring that crabs reach maturity before harvesting can lead to higher profitability and sustainable fishing practices, safeguarding long-term financial stability in the industry.
I wrote 2 more articles about making personal projects! !Feel free to take a look:
Breaking into Data Science: The Importance of Personal Projects in Landing Your Dream Job
5 Tips on Making Personal Data Science Projects
Conclusion
Although my initial answers may not have been perfect, the comprehensive test helped me grow and learn. It refined my skills, expanded my knowledge, and led to my first data scientist job.
In the field of data science, many companies offer opportunities to enthusiastic learners. Aspiring data scientists should showcase themselves through projects that go beyond building machine learning models. These projects should demonstrate technical and business skills to solve real-world problems.
Remember that your journey extends beyond the model building. Companies value individuals with technical skills, critical thinking, and business understanding. Presenting a project that showcases these qualities positions you as a valuable candidate.
If you found this article insightful, don’t forget to clap and leave a comment to let me know your thoughts. Stay connected by following me for future articles on various topics in Data Science. Thank you for your support!
My Articles
Analyzing Threads as A Product Data Scientist | by Leo Leung | Jul, 2023 | Medium
In Plain English
Thank you for being a part of our community! Before you go:
- Be sure to clap and follow the writer! 👏
- You can find even more content at PlainEnglish.io 🚀
- Sign up for our free weekly newsletter. 🗞️
- Follow us on Twitter(X), LinkedIn, YouTube, and Discord.





