
The Modern Cloud Data Platform war — Hadoop Data Platform (Part 2)
The On-Premise Hadoop and Lift-and-Shift.
This article is a part of a multi-part series Modern Cloud Data Platform War (parent article). Previous part — Modern Cloud Data Platform War — Hadoop (Part 1).
Current: On-Premise Hadoop:
Get phase — Discovery, the As-Is — current technology, people, and process.
As-Is Phase: Understand the current On-prem Hadoop set up:
- What is the current version of Hadoop in place?
- What is the Big Data architecture that is being used (Lambda or Kappa or any other variant?)
- What is the cost of running the Hadoop clusters for one year?
- What are the non-frequent data sets that need not be accessed normally?
- What are the frequent data sets that need to be part of the critical path and accessed normally and have 24x7 needs?
- How many nodes are in place?
- What are the Data ingestion components?
- What are the Data access interfaces?
- What are the Data processing Engines?
- What is the Resource management framework?
- What is the Data Input / Output format?
- What is the serialization/compression technique used?
- What is the security protocol?
- What is the Data storage medium used?
- DevOps / DataOps / DevSecOps / DataSecOps for the overall Big Data ecosystem.
- How Ingress (ingesting) /Egress (reading) and processing of data happens?
- What are the current set of Data tools in place?
- What is the Data Management protocol?
- What is the Data Governance process in place?
As-Is Phase: Understand the current users:
- What are the different sets of users?
- What are the different sets of applications users are using including Business Intelligence Reports, Accessing Canned reports, Access to on-demand reports, access to intelligent data, etc.
- How is the dimension modeling done and distributed to the users?
As-Is Phase: Understand the current process for procuring resources:
- Current process to obtain the technologies for the big data ecosystem
- How to procure hardware for DataNodes
- Process to upgrade and downtime
- SLA for Business for each of the Critical and Non-Critical data sets.
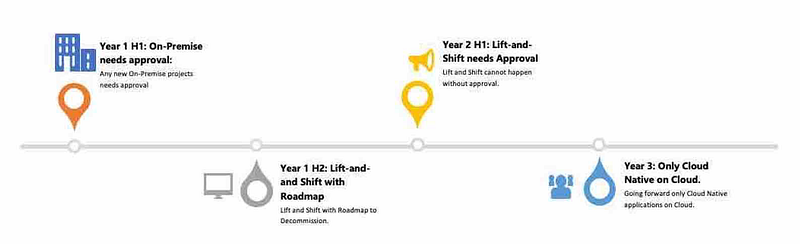
Option 1: Lift-and-Shift
Hadoop On-premise to Hadoop Cloud — a simple Lift-and-Shift for day 1 if the solution is not effective and not cloud-native supported, with the roadmap to refactor and decommission the Lifted-and-Shifted Tactical fix.
There will be a natural proclivity towards Lift and Shift due to the very underlying principle of “Do not fix something that is not broken” by both Business and Technology teams at a general level. Also, the cost of human resources, technology, and processes to build modern data platforms and spending Business time to UAT the same may not be justified as according to business “It is working fine”. While this approach and principle are good for “Automation” related projects, Digital Transformation projects must be approached differently. From sourcing, pipelining, storing, sharing you may end up having multiple copies across the firm due to the different types of restrictions in place for internal and external users. Cloud Transformation is an opportunity to de-clutter, re-think the architecture and do a much more effective Distributed processing with the latest technology stack.
Do not fix something that is not broken: Again, this is 100% true. But if the functionality is working fine and the business gets the reports delivered on time without breaking SLA’s and no fines, does it mean the system is not broken underneath and there are absolutely no leaks? Is it a cost-effective solution? How often we are working on upgrades and how big is the support team — is it maintenance optimized? How many duplicates of data exist? Is your Data Lake really a Data Lake or it’s taking the shape of the swamp? Is your solution agile — what is the turnaround time for any enhancements that you are done? Is the solution Highly available, resilient, fault-tolerant? Is DevOps, DataOps, and DataSecOps integrated? Are you stuck in the gen1 hardware or moved to gen2? If your business and technology team’s answer is YES to all these questions, then we are already using modern data technology and there is no need for advancement.
If your answer is no to the above questions, and only due to the organization’s mandate you are moving to Cloud and for now you are doing “Lift-and-Shift”, which is still ok. This is the essential first step without immediately using the opportunity, but the Cloud Committee should make sure that such “Lift-and-Shift” are only considered Tactical, and it comes with a Decommission date with a clear roadmap for Strategic shift to the Modern cloud-native data and entire ecosystem architecture.
Lift and Shift: To Cloudera CDP. Will discuss more on this in the next section.
Advantages of On-Premise Hadoop:
1. Better control
2. For Hadoop 3 (if upgraded) a new feature called “Erasure coding” helps to mitigate the cost access non-frequent datasets with low I/O activities that are not accessed in the critical path or in the normal course of activities
3. Hadoop 3’s dependency on Linux ephemeral port range for default ports are moved out, which means failure starting the services can be reduced.
4. HDFS Diskbalancer with Hadoop 3 to make sure that when replacing disk managed by DataNodes, skewed distribution does not happen and balanced distribution take place.
Disadvantages on On-premise Hadoop:
1. On-premise Hadoop was Gen1 and we are in Gen3 now.
2. Complexity of upgrading the cluster.
3. Multiple parties are using the hardware and a big-bang upgrade will impact every tenant.
4. Storage and the Compute layer are mostly co-located and is not separate.
5. While Hadoop comes with a replication factor of 3, for not so frequently accessed data sets overhead cost is around 200% or more as they consume the same amount of resources as other main resources. Overheads due to replication factor if the upgrade to version 3 has not taken place.
6. If not updated to Hadoop 3, then the ephemeral port range issue and problem starting services persist.
7. Skewed distribution in case of Disk replacement managed by DataNodes if not upgraded to Hadoop 3.
Lift and shift with Roadmap track:
If the current On-Premise Hadoop does not comply with the Cloud-native aspects and if due to the organization’s mandate you have to move to the cloud, approve for Lift-And-Shift with a proper roadmap to build cloud-native and decommission the tactical solution. For Company X, Lift and Shift should be with a roadmap to decommission as the current Lambda architecture’s Batch Layer uses Map Reduce, it can be changed to use Spark processing.
Massive Data Input:
Millions of data inputs are sourced from several upstream systems for few hours and less load for more than 75% of the time.
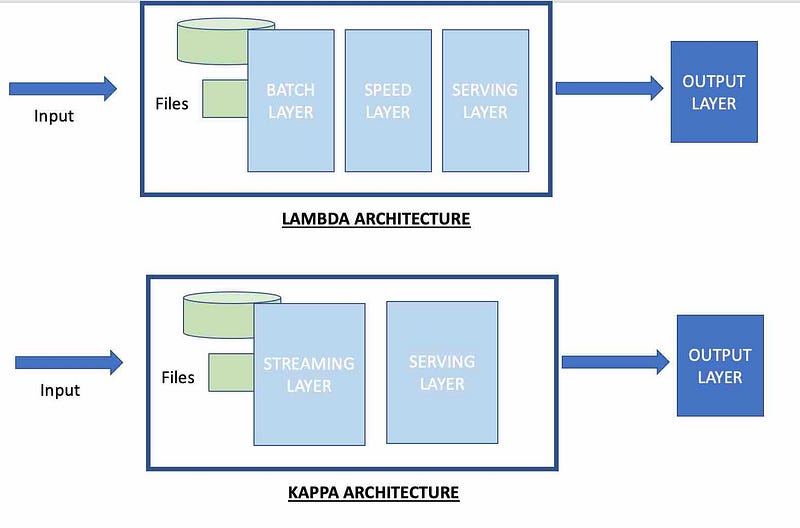
Solution 1: Lambda architecture:
Currently, Organization X processes the Batch layer using Map Reduce and the streaming part (speed layer), which was built later processes using Spark. Current Lambda architecture is certainly alright, however, Delta Lake the Lakehouse Architecture is a better solution.
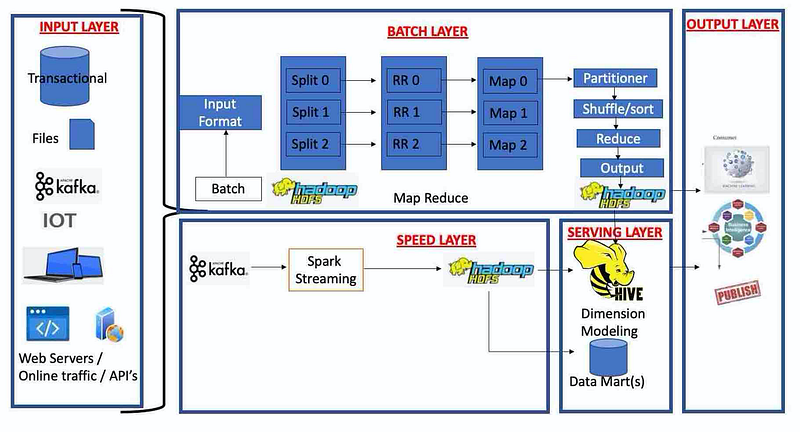
Batch Layer: This is the cold path where we read and process data from batch files, pass it to Spark for data processing and
Speed Layer: This is the hot path where the organization uses Kafka streams for Data Pipeline.
Proposed solution using Lambda Architecture:
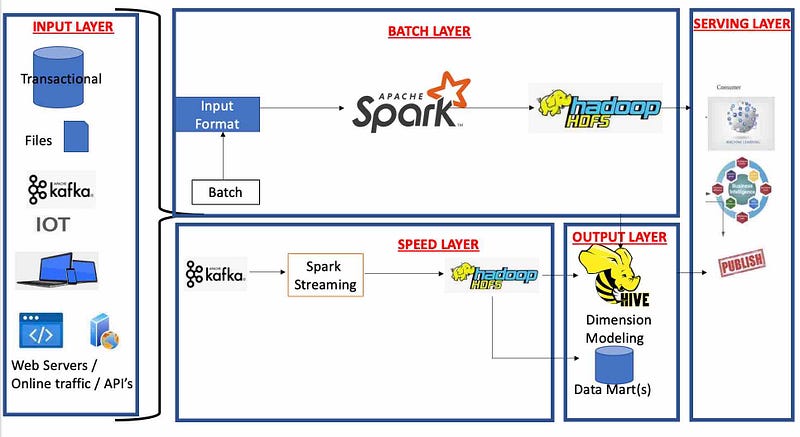
Alternative architectures:
Kappa Architecture:
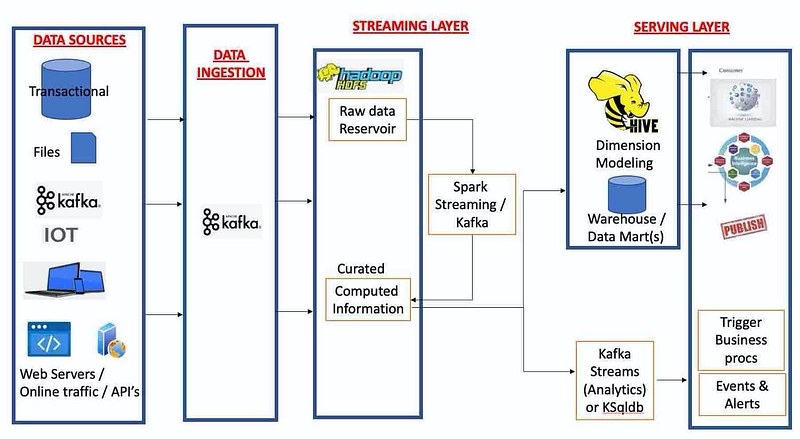
Kappa architecture is not very suitable for Organization X as it needs both batch and stream processing layers.
The core difference between Lambda and Kappa:
Kappa does not have Batch layer and if a firm receives batch files then Kappa is not suitable.
Lakehouse Architecture:
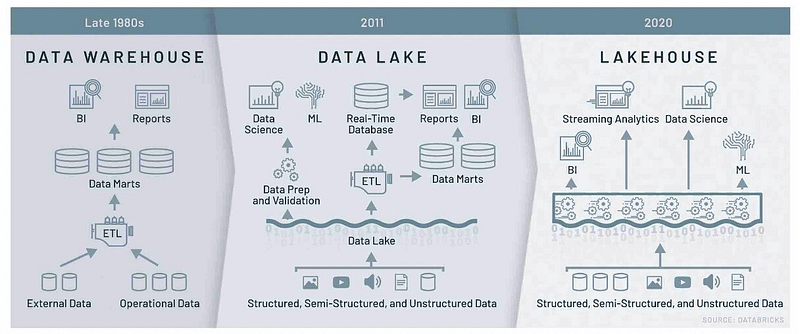
Refer: Modern Cloud Data Platform — DataBricks Lakehouse architecture to solve the issue of Massive Data inputs.
Lakehouse is a better architecture pattern for organization X with lift-and-shift with a roadmap to decommission and move to cloud-native.
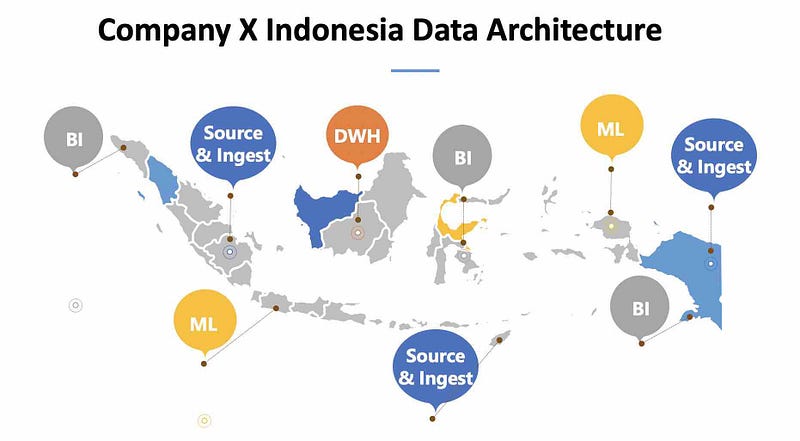
Data Fluctuations
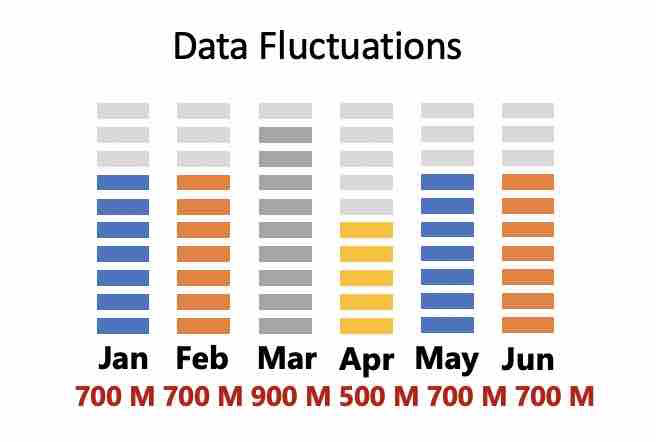
Imagine that there is a flux of data at a different point in time. Between Jan to Jun this year, the data fluctuations was between 500 M to 900 M. With Indonesia Data Architecture relying heavily on the on-premise Data platform, such fluctuations demand scalability (on-premise = vertical scalability, mostly) warrants provisioning for a minimum of 1200 M records and should be able to readily scale anytime. We are to architect using cloud lets us explore and research different options from Sourcing to consumption overarching Data Governance and Security and build reference architectures with different combinations.
Solution 1:
Hadoop 3 supports a new feature called “Erasure coding” which helps to mitigate the cost of access non-frequent datasets with low I/O activities that are not accessed in the critical path or in the normal course of activities.
Massive Loads of Data Sharing:
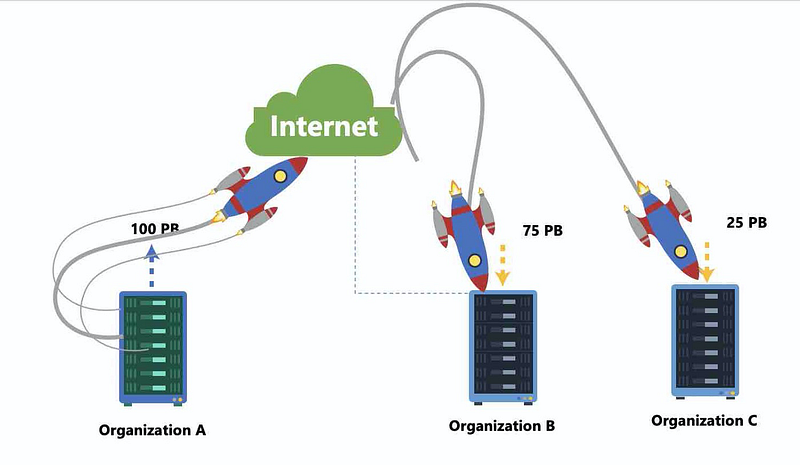
Organization X has to share loads of data with other organizations — say every month-end they transfer 100 PB of data over.
Copying massive amounts of data either internally or externally is not a good idea as it results in data duplicates. This includes slicing and dicing of data and creating different buckets to share data with the users — this will result in Data Swamps even if your intention for organization X is to build a good data lake.
Solution 1:
With advanced solutions such as Hive / Presto etc., do ELT rather than ETL ie., you can do petabytes of transformations at the query layer itself instead of having to Transform then Load, do the transformation at the query layer.
Machine Learning and Analytics:
Different types of Machine Learning algorithms run on these massive data sets from Recommendation engines to fraud detection etc.
Solution 1:
Spark ML provides many built-in Machine Learning algorithms and the ability to works well with the RDD to gain intelligence out of data.
Search:

Solution 1:
To search several GB’s of data, Several GB’s of data is searched per hour. There are also fluctuations in search.
Summary:
Before opting for Lift-and-Shift for Organization X, try and get a few of the processing fine-tuned or have a very clear roadmap to Lift-and-Shift first, have a roadmap to decommission, and build the cloud-native application.





