
The Hands-On LLMs Series
The LLMs kit: Build a production-ready real-time financial advisor system using streaming pipelines, RAG, and LLMOps
Lesson 1: LLM architecture system design using the 3-pipeline pattern

→ the 1st out of 8 lessons of the Hands-On LLMs free course
By finishing the Hands-On LLMs free course, you will learn how to use the 3-pipeline architecture & LLMOps good practices to design, build, and deploy a real-time financial advisor powered by LLMs & vector DBs.
We will primarily focus on the engineering & MLOps aspects. Thus, by the end of this series, you will know how to build & deploy a real ML system, not some isolated code in Notebooks (we haven’t used any Notebooks at all).
More precisely, these are the 3 components you will learn to build:
- a real-time streaming pipeline (deployed on AWS) that listens to financial news, cleans & embeds the documents, and loads them to a vector DB
- a fine-tuning pipeline (deployed as a serverless continuous training) that fine-tunes an LLM on financial data using QLoRA, monitors the experiments using an experiment tracker and saves the best model to a model registry
- an inference pipeline built in LangChain (deployed as a serverless RESTful API) that loads the fine-tuned LLM from the model registry and answers financial questions using RAG (leveraging the vector DB populated with financial news in real-time)
We will also show you how to integrate various serverless tools, such as:
Curios? Check the video below to understand better what you will learn ↓
Who is this for?
The series targets MLE, DE, DS, or SWE who want to learn to engineer LLM systems using LLMOps good principles.
This is an intermediate course. Thus, we expect you already have some knowledge about Python, ML, and cloud.
But don’t worry, you don’t have to be a PRO to understand this course. That is our goal: “to help you become a PRO” 👀
How will you learn?
The series contains 4 hands-on lessons in video & written format and the open-source code you can access on GitHub. To get the most out of this course, we encourage you to clone and run the repository while you cover the lessons.
Contributors
Pau Labarta Bajo | Senior ML & MLOps Engineer Main teacher. The guy from the video lessons.
Paul Iusztin | Senior ML & MLOps Engineer Main chef. The guys who randomly pop in the video lessons.
Alexandru Razvant | Senior ML Engineer Second chef. The engineer behind the scenes.
Ready?
Let’s get started 🔥
Lessons
- Lesson 1 | System Design: The LLMs Kit: Build a Production-Ready Real-Time Financial Advisor System Using Streaming Pipelines, RAG, and LLMOps
- Lesson 2 | Feature pipeline: Why you must choose streaming over batch pipelines when doing RAG in LLM applications
- Lesson 3 | Feature pipeline: This is how you can implement and deploy a streaming pipeline to populate a vector DB for real-time RAG
- Lesson 4 | Training pipeline: 5 concepts that must be in your LLM fine-tuning kit
- Lesson 5 | Training pipeline: A hands-on guide on how to fine-tune any LLM using QLoRA
- Lesson 6 | Training pipeline: From development to a continuous training pipeline using LLMOps
- Lesson 7 | Inference pipeline: How to design a RAG LangChain application leveraging the 3-pipeline architecture
- Lesson 8 | Inference pipeline: Prepare your RAG LangChain application for production
🔗 Check out the code on GitHub and support us with a ⭐️
Lesson 1
In this lesson, I will present you with how to design an ML system using the 3-pipeline architecture (also known as the FTI architecture). After, I will show you an overview of how to apply it to build a real-time financial advisor using streaming flows, LLMs & vector DBs.
In the following lessons, we will drill down on each component of the 3-pipeline architecture. For each component, we will start by presenting the essential theory concepts. Afterward, we will focus on the system design, the code, and how to build a CI/CD pipeline to deploy it to AWS or Beam.
Table of Contents
- General presentation of building an ML system using the 3-pipeline architecture
- How to build a real-time financial advisor using the 3-pipeline architecture
- Tech stack
- The feature pipeline
- The training pipeline
- The inference pipeline
🔗 Check out the code on GitHub and support us with a ⭐️
#1. General presentation of building an ML system using the 3-pipeline architecture
We all know how 𝗺𝗲𝘀𝘀𝘆 𝗠𝗟 𝘀𝘆𝘀𝘁𝗲𝗺𝘀 can get. That is where the 𝟯-𝗽𝗶𝗽𝗲𝗹𝗶𝗻𝗲 𝗮𝗿𝗰𝗵𝗶𝘁𝗲𝗰𝘁𝘂𝗿𝗲 𝗸𝗶𝗰𝗸𝘀 𝗶𝗻.
The 3-pipeline design is a way to bring structure & modularity to your ML system and improve your MLOps processes.
=== 𝗣𝗿𝗼𝗯𝗹𝗲𝗺 ===
Despite advances in MLOps tooling, transitioning from prototype to production remains challenging.
In 2022, only 54% of the models get into production. Auch.
So what happens?
Sometimes the model is not mature enough. Sometimes there are some security risks, but most of the time…
…the architecture of the ML system is built with research in mind, or the ML system becomes a massive monolith that is extremely hard to refactor from offline to online.
So, good SWE processes and a well-defined architecture are as crucial as using suitable tools and models with high accuracy.
=== 𝗦𝗼𝗹𝘂𝘁𝗶𝗼𝗻 ===
𝘛𝘩𝘦 3-𝘱𝘪𝘱𝘦𝘭𝘪𝘯𝘦 𝘢𝘳𝘤𝘩𝘪𝘵𝘦𝘤𝘵𝘶𝘳𝘦.
First, let’s understand what the 3-pipeline design is.
It is a mental map that helps you simplify the development process and split your monolithic ML pipeline into 3 components: 1. the feature pipeline 2. the training pipeline 3. the inference pipeline
…also known as the Feature/Training/Inference (FTI) architecture.
.
#𝟭. The feature pipeline transforms your data into features & labels, which are stored and versioned in a feature store. The feature store will act as the central repository of your features. That means that features can be accessed and shared only through the feature store.
#𝟮. The training pipeline ingests a specific version of the features & labels from the feature store and outputs the trained model weights, which are stored and versioned inside a model registry. The models will be accessed and shared only through the model registry.
#𝟯. The inference pipeline uses a given version of the features from the feature store and downloads a specific version of the model from the model registry. Its final goal is to output the predictions to a client.
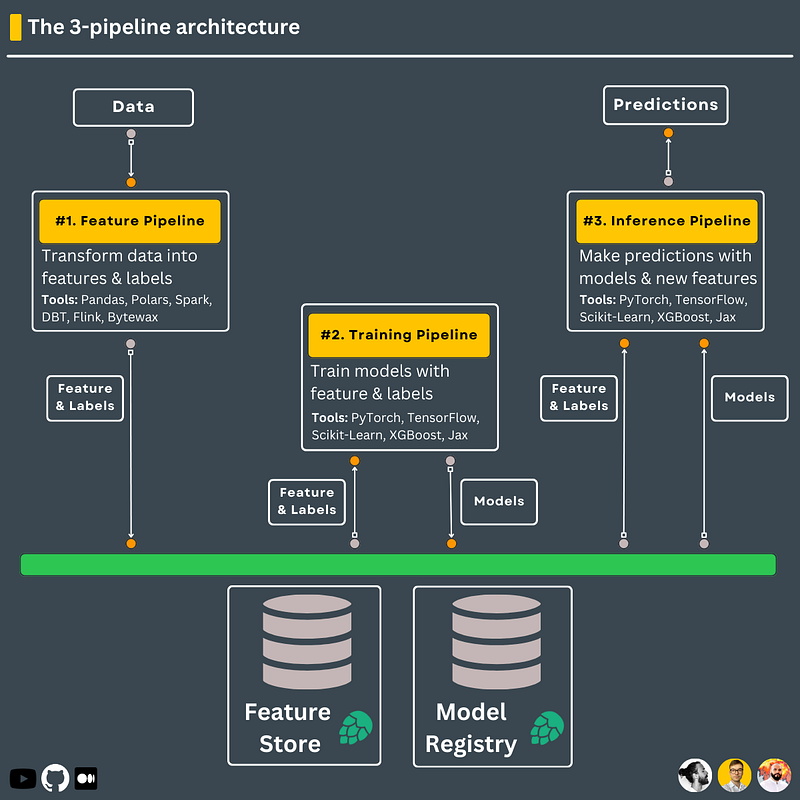
This is why the 3-pipeline design is so beautiful:
- it is intuitive - it brings structure, as on a higher level, all ML systems can be reduced to these 3 components - it defines a transparent interface between the 3 components, making it easier for multiple teams to collaborate - the ML system has been built with modularity in mind since the beginning - the 3 components can easily be divided between multiple teams (if necessary) - every component can use the best stack of technologies available for the job - every component can be deployed, scaled, and monitored independently - the feature pipeline can easily be either batch, streaming or both
But the most important benefit is that…
…by following this pattern, you know 100% that your ML model will move out of your Notebooks into production.
↳ If you want to learn more about the 3-pipeline design, I recommend this excellent article [1] written by Jim Dowling, one of the creators of the FTI architecture.
#2. How to build a real-time financial advisor using the 3-pipeline architecture
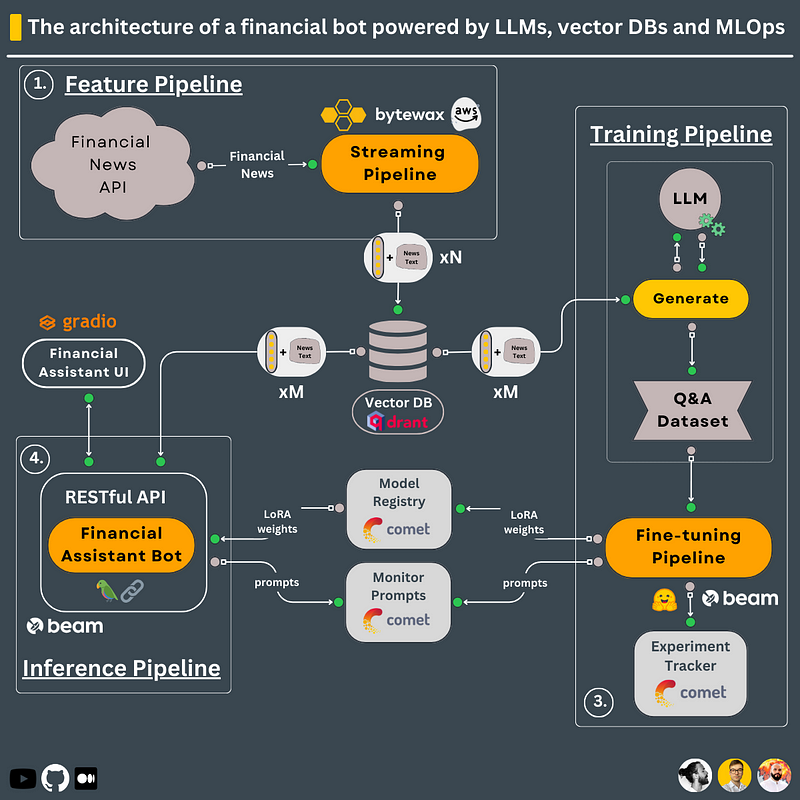
Let’s see a high-level overview of a concrete example of how to implement the FTI pipelines ↓
#𝟭. 𝗙𝗲𝗮𝘁𝘂𝗿𝗲 𝗽𝗶𝗽𝗲𝗹𝗶𝗻𝗲
The feature pipeline is designed as a streaming pipeline that extracts real-time financial news from Alpaca and:
- cleans and chunks the news documents - embeds the chunks using an encoder-only LM - loads the embeddings + their metadata in a vector DB - deploys it to AWS
In this architecture, the vector DB acts as the feature store.
The vector DB will stay in sync with the latest news to attach real-time context to the LLM when using RAG.
#𝟮. 𝗧𝗿𝗮𝗶𝗻𝗶𝗻𝗴 𝗣𝗶𝗽𝗲𝗹𝗶𝗻𝗲
The training pipeline is split into 2 main steps:
↳ 𝗤&𝗔 𝗱𝗮𝘁𝗮𝘀𝗲𝘁 𝘀𝗲𝗺𝗶-𝗮𝘂𝘁𝗼𝗺𝗮𝘁𝗲𝗱 𝗴𝗲𝗻𝗲𝗿𝗮𝘁𝗶𝗼𝗻 𝘀𝘁𝗲𝗽
It takes the vector DB (feature store) and ~5 financial predefined questions (manually written) as input.
After, you:
- use a large & powerful model, such as GPT-4, to generate more financial questions (up to 100)
- use RAG to inject the context along the predefined questions
- use a large & powerful model, such as GPT-4, to generate the answers
- save the generated dataset under a new version (it is important to version the dataset in case you repeat this process)
→ The process of generating data using a large & powerful model (e.g., GPT-4) to fine-tune a smaller model (e.g., Falcon 7B) is known as “fine-tuning with distillation.”
↳ 𝗙𝗶𝗻𝗲-𝘁𝘂𝗻𝗶𝗻𝗴 𝘀𝘁𝗲𝗽
- download a pre-trained LLM from Huggingface - load the LLM using QLoRA - preprocesses the generated Q&A dataset into a format expected by the LLM - fine-tune the LLM - push the best QLoRA weights (model) to a model registry - deploy it using a serverless solution as a continuous training pipeline
#𝟯. 𝗜𝗻𝗳𝗲𝗿𝗲𝗻𝗰𝗲 𝗣𝗶𝗽𝗲𝗹𝗶𝗻𝗲
The inference pipeline is the financial assistant that the clients actively use.
It uses the vector DB (feature store) and QLoRA weights (model) from the model registry in the following way:
- download the pre-trained LLM from Huggingface - load the LLM using the pretrained QLoRA weights - connect the LLM and vector DB into a chain - use RAG to add relevant financial news from the vector DB - deploy it using a serverless solution under a RESTful API
Here are the main benefits of using the FTI architecture: - it defines a transparent interface between the 3 modules - every component can use different technologies to implement and deploy the pipeline (see the “#3. Tech stack” section below) - the 3 pipelines are loosely coupled through the feature store & model registry - every component can be scaled independently
🔗 Check out the code on GitHub and support us with a ⭐️
#3. Tech stack
The tools are divided based on the 𝟯-𝗽𝗶𝗽𝗲𝗹𝗶𝗻𝗲 (aka 𝗙𝗧𝗜) 𝗮𝗿𝗰𝗵𝗶𝘁𝗲𝗰𝘁𝘂𝗿𝗲:
=== 𝗙𝗲𝗮𝘁𝘂𝗿𝗲 𝗣𝗶𝗽𝗲𝗹𝗶𝗻𝗲 ===
What do you need to build a streaming pipeline?
→ streaming processing framework: Bytewax (brings the speed of Rust into our beloved Python ecosystem)
→ parse, clean, and chunk documents: unstructured
→ validate document structure: pydantic
→ encoder-only language model: HuggingFace sentence-transformers, PyTorch
→ vector DB: Qdrant
→ deploy: Docker, AWS
→ CI/CD: GitHub Actions
=== 𝗧𝗿𝗮𝗶𝗻𝗶𝗻𝗴 𝗣𝗶𝗽𝗲𝗹𝗶𝗻𝗲 ===
What do you need to build a fine-tuning pipeline?
→ pretrained LLM: HuggingFace Hub (e.g., Falcon 7B)
→ parameter efficient tuning method: peft (= LoRA)
→ quantization: bitsandbytes (= QLoRA)
→ training: HuggingFace transformers, PyTorch, trl
→ distributed training: accelerate
→ experiment tracking: Comet ML
→ model registry: Comet ML
→ prompt monitoring: Comet ML
→ continuous training serverless deployment: Beam
=== 𝗜𝗻𝗳𝗲𝗿𝗲𝗻𝗰𝗲 𝗣𝗶𝗽𝗲𝗹𝗶𝗻𝗲 ===
What do you need to build a financial assistant?
→ framework for developing apps powered by language models: LangChain
→ model registry: Comet ML
→ inference: HuggingFace transformers, PyTorch, peft (to load the LoRA weights)
→ quantization: bitsandbytes
→ distributed inference: accelerate
→ encoder-only language model: HuggingFace sentence-transformers
→ vector DB: Qdrant
→ prompt monitoring: Comet ML
→ RESTful API serverless service: Beam
.
As you can see, some tools overlap between the FTI pipelines, but not all.
This is the beauty of the 3-pipeline design, as every component represents a different entity for which you can pick the best stack to build, deploy, and monitor.
You can go wild and use Tensorflow in one of the components if you want your colleges to hate you 😂
Now, let’s better understand each pipeline independently ↓
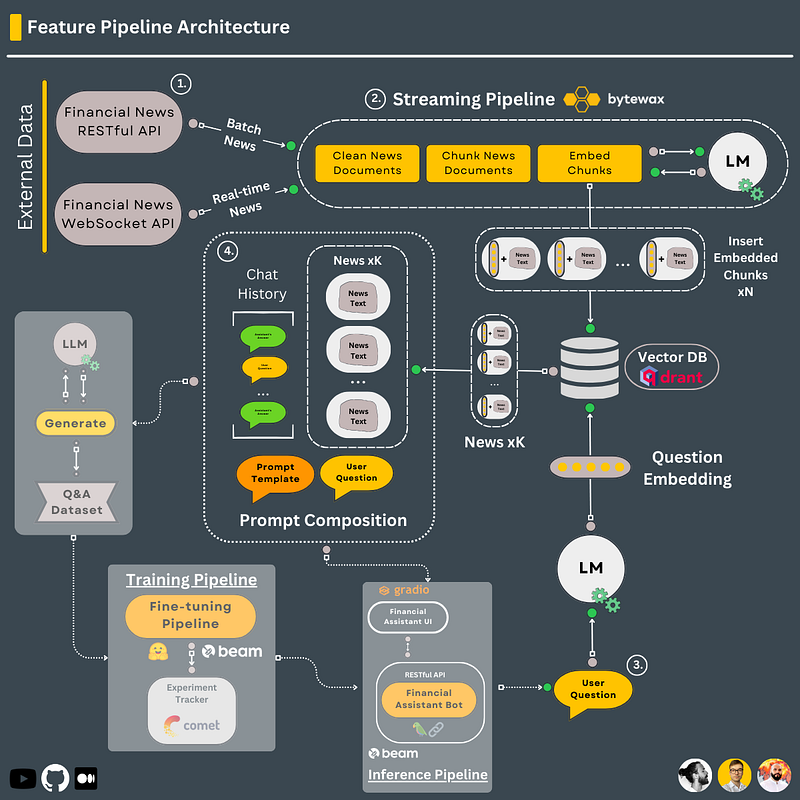
#4. Feature pipeline
We want to build a streaming pipeline that listens to real-time financial news, embeds the news, and loads everything in a vector DB. The goal is to add up-to-date news to the user’s questions using RAG to avoid retraining.
- We listen 24/7 to financial news from Alpaca through a WebSocket wrapped over a Bytewax connector.
- Once any financial news is received, these are passed to the Bytewax flow that: - extracts & cleans the necessary information from the news HTML document - chunks the text based on the LLM’s max context window - embeds all the chunks using the “all-MiniLM-L6-v2” encoder-only model from sentence-transformers - inserts all the embeddings along their metadata to Qdrant
- The streaming pipeline is deployed to an AWS EC2 machine that runs multiple Bytewax processes. It can be deployed to AWS EKS (their K8s service) into a multi-node setup to scale up the solution.
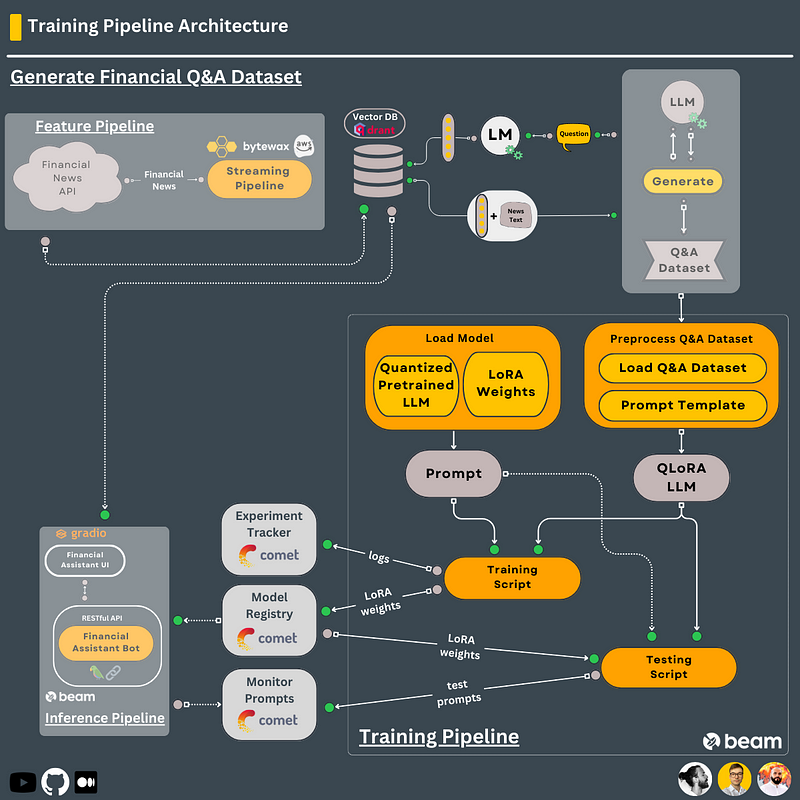
#5. Training pipeline
We want to fine-tune a pretrained LLM to specialize the model to answer financial-based questions.
- Manually fill ~5 financial questions.
- Use a powerful model such as GPT-4 to generate up to 100 similar financial questions (or hire an expert if you have more time and resources).
- Use RAG to enrich the questions using the financial news from the Qdrant vector DB.
- Use a powerful model such as GPT-4 to answer them (or hire an expert if you have more time and resources).
- Load Falcon-7B from HuggingFace using QLoRA to fit on a single GPU.
- Preprocess the financial Q&A dataset into prompts.
- Fine-tune the LLM and log all the artifacts to Comet’s experiment tracker (loss, model weights, etc.)
- For every epoch, run the LLM on your test set to log the prompts to Comet’s prompt logging feature and compute the metrics logged into Comet’s experiment tracker.
- Send the best LoRA weights to Comet’s model registry as the next production candidate.
- Deploy steps 4–8 to Beam to run the training on an A10G or A100 Nvidia GPU.
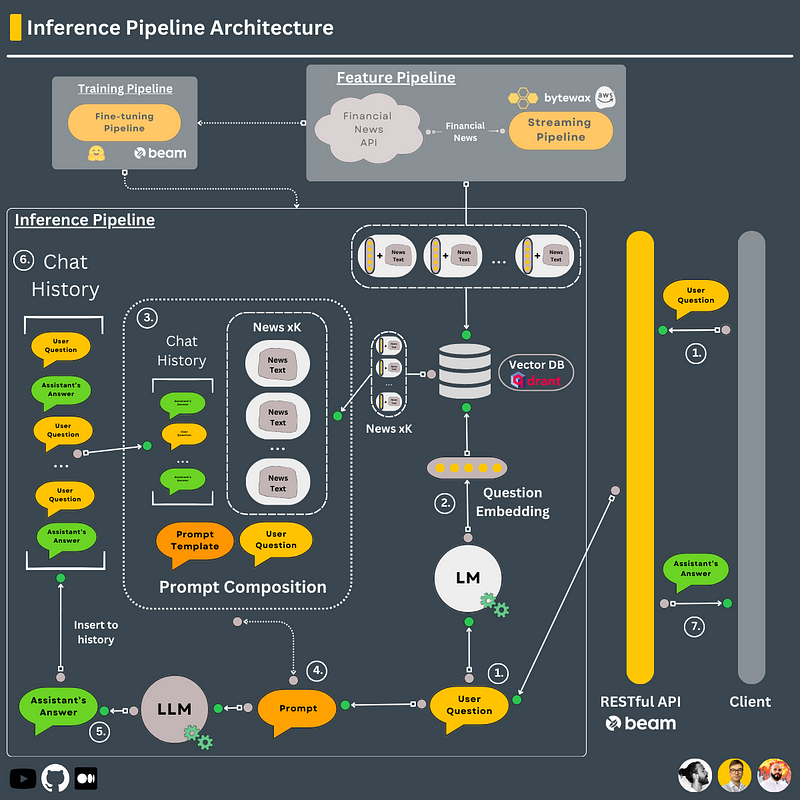
#6. Inference pipeline
We want to do RAG using the financial news stored in the Qdrant Vector DB and the Falcon-7B fine-tuned model. The solution will be deployed under a RESTful API to serve various clients.
Steps 1–7 are all chained together using LangChain.
- Use the “all-MiniLM-L6-v2” encoder-only model to embed the user’s question.
- Using the question embedding, query the Qdrant vector DB to find the top 3 related financial news.
- Attach the text (stored as metadata along the embeddings) of the news to the prompt (aka RAG).
- Download Falcon’s pretrained weights from HF & LoRA’s fine-tuned weights from Comet’s model registry.
- Load the LLM in memory.
- Pass the prompt (= the user’s question, financial news, history) to the LLM.
- Store the conversation in LangChain’s memory to inject it into future prompts.
- Deploy steps 1–7 under a RESTful API using Beam.
🔗 Check out the code on GitHub and support us with a ⭐️
Conclusion
Congratulations! Now you know how to design a real-time financial advisor.
In this lesson, you learned about the 3-pipeline architecture (aka the FTI pipelines). You also understood how to apply it to design a real-time financial advisor powered by streaming flows, LLMs, and vector DBs.
We highlighted the benefits of using the 3-pipeline architecture and the tech stack you will use during this course.
In this lesson, we presented a very high-level overview of each component. In the following lessons, we will zoom in on each pipeline design and explain the code step-by-step.
Thanks for reading. I hope you are enjoying the Hands-on LLMs series. ✌️
→ Check out Lesson 2 (released soon) to understand how to build a real-time feature pipeline using Bytewax (stream processing engine), unstructured (text preprocessing tool), an encoder-only LM, and Qdrant (vector DB).
🔗 Hands-on LLMs Course GitHub Repository [2]
If you are also interested in learning the fundamentals of MLOps and designing, building, deploying and monitoring an end-to-end ML batch system, check out my “The Full Stack 7-Steps MLOps Framework” FREE course ~ source code + 2.5 hours of reading & video materials
👀 I want to thank Pau Labarta Bajo and Alexandru Razvant again for contributing to this course and making it happen.
🔥 If you enjoy reading articles like this and wish to support my writing, consider becoming a Medium member. By using my referral link, you can support me without any extra cost while enjoying limitless access to Medium’s rich collection of stories.
Thanks ✌️
References
[1] Jim Dowling, From MLOps to ML Systems with Feature/Training/Inference Pipelines (2023), Hopsworks
[2] Hands-on LLMs Course GitHub Repository (2023), GitHub





