
The Inadequacy of Shannon’s Information in Understanding Cognition

What is information? Aaron Sloman has been exploring this question for quite a while. Sloman argues that we cannot adequately understand cognition if we continue to exclusively use a shallow definition of information. Shannon’s Information Theory explored information from a perspective of information transfer. Which makes sense since he worked as Bell labs (i.e. a telecommunication firm).
There is however more to information than the quantity of bits that is stored, transmitted and compared. Shannon’s Information Theory is exclusively about the syntax of information and does not cover the semantics of information (more specifically, the quantity of the syntax). The semantics of information concerns the ‘aboutness’ of information. Brian Cantwell Smith has also much to say about the distinction between the semantics and the quantification of information (He argues though that viewing computation from the lens of information processing is too narrow a perspective). I believe though that its important enough to understand the stuff that computational systems juggle around.
The semantics of information is about the interpretation of information. All information processing can be reduced to computation, memory, and signaling. This definition is opaque to the semantics that exists in information. That is, how is information interpreted by an agent.
Sloman points out that the novelist Jane Austen (Early 19th century) had a keen awareness of human information. Sloman writes that information must have “usefulness”:
Being of use is a more fundamental feature of information than being physically manipulable, since there would not be any point in storing, manipulating or transmitting information, or even creating information items to be stored or transmitted, if the information could not be used.
He further specified that the most fundamental use of information is for control.
If we take the abstraction that the semantics of information expresses the constraints of what the information is about (what it refers to) then it is different from the notion of control. Control implies that when information is conveyed, the agent reacts in a way determined by the control information. This is too restrictive a requirement. A less restrictive definition would be that information convey constraints. An agent may react in a way that reflects its own internal processing of these constraints.
Mark Burgess’ Promise Theory has an analogous interpretation of this:
Obligation theories in computer science often view an obligation as a deterministic command that causes its proposed outcome. In Promise Theory an agent may only make promises about its own behaviour. For autonomous agents it is meaningless to make promises about another’s behaviour.
In Burgess’ Promise Theory, information is treated as promises that are less restrictive than obligations (i.e. control). Burgess’ has written a series of papers on “Semantic Spacetime” where he also explores his notion of promises with respect to artificial intelligence. This is definitely worth a read.
I am going to use the term Constraint instead of the term Promise to describe the usefulness or aboutness of information. I’m not familiar enough with Promise Theory to begin comfortably using it. I expect though that I will use a different term in the future because the term “Constraint” does not encompass all the usefulness that information can convey. I will discuss this in a follow-up article.
I’m going to apply this definition now to something I’ve been calling the “Loosely Coupled Principle”. This principle revolves around the information coupling of modules with other modules. The general guideline is that scalable and complex systems are more likely to use lower information coupling. The word ‘loose’ is a bit awkward, but its a useful description in one can visualize the difference between the coupling between a tight string as compared to a loose string. I don’t want to use the word high or low since this might convey a quantity and thus be misinterpreted as Shannon information. Loosely coupling is not a scalar but rather it is the kind of structural configuration that couples together modules. Perhaps a quantified distribution may serve as a proxy, however I doubt that one can quantify semantics.
Loose coupling originates from the study of the architecture of modular systems.
One way to explain this is to provide examples of loose coupling:
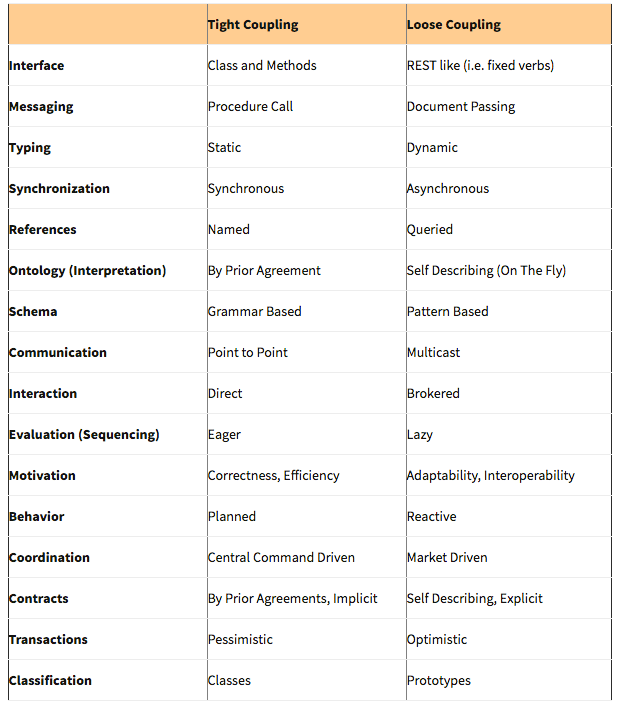
Permit me to lay out some design principles that lead to loose coupling.
(1) All constraints (or information) should be available locally and not through a global information source. ( Interface, Messaging, Self-Describing, Contracts, Classification)
(2) There should be minimal constraints on the sequence of information exchange between modules. (Messaging, Evaluation, Reactive, Coordination)
(3) Additional necessary constraints should be discoverable through an explicit mechanism. (Typing, Reference, Interaction, Communication)
(4) Information exchange should not require synchronous participation between modules. (Synchronization, Coordination, Transaction)
(5) Coupling should be robust to incomplete information. (Pattern-based, Classification)
The above loose coupling examples fit within 3 categories:
(1) Mediation — Intermediate modules that translate the constraints in one form into the constraints in another.
(2) Decomposition- Break up modules that handle fewer complex constraints.
(3) Late Binding- Employ constraint satisfaction using reflective structures.
Typical design of neural networks is trained by introducing regularizations that minimize or maximize an attribute of the network. For example, L1 regularization maximizes sparsity and L2 regularization favors smooth solutions.
The approach introduced here employs structural components that are designed to reduce coupling between modules. It is important to accept that cognitive machinery consists of a massive collection of coupled modules. Modules can be equivalent to universal Turing machines. To ensure scalability and to minimize module coordination costs, the coupling between modules should be as loose as needed. Specifically, these methods use mediation, decomposition and late binding components that can is configured through training.
The motivation for introducing these modularity inspired principles is to accelerate learning. If information conveys constraints, then reducing constraints reduces learning costs. The conjecture that I wrote about on a previous article is that modularity drives accelerated learning. It does not matter how modular our architecture is if it does not lead to accelerated learning.
Carliss Baldwin and Kim Clark wrote in 2000 a book “Design Rules” which explored in explore the power of modularity in fields requiring human design. In their book, the authors write that “modularity creates design options”. Furthermore, they contrast design evolution ( Modular Operators: Splitting, Substituting, Augmenting, Excluding, Inverting, Porting) with Holland’s Genetic operators ( Crossing, Mutation, Dominance, Segregation, Translocation, Duplication).
So I have actually come full circle. In the early 2000s, as a Software Architect, I was aware of the Design Rules book. This book motivated me to seek Loosely Coupled architectures (I also was writing a book about this, but it was never completed). As I explored Deep Learning for the past several years, I began to notice the lack of a guiding principle in their design. Perhaps Loose Coupling provides this missing principle. These principles turn out to be inspired not just by human design thinking but rather more fundamental evolutionary principles. Just as Sloman was inspired by 18th century Jane Austen’s musing about information, I’m inspired by the 21st-century explorations in design evolution. Our understanding of information is so much richer today and we would be remiss not to leverage this understanding to something fundamental like the origins of cognition.
Alexander Alemi and Ian Fischer released an Arxiv paper about the “Thermodynamics of Machine Learning”. It’s a nice paper that makes the correspondence of machine learning and the mathematical formulation of Thermodynamics. Thermodynamics is one of those theories in physics that isn’t formulated from first principles. Rather, the relationship between temperature, pressure, and volume are derived through empirical evidence. It was only later that Statistical Mechanics showed that you can begin with first principles (i.e. atoms colliding) to arrive at the equations of Thermodynamics. Thermodynamics is extremely useful in that you can formulate the design of engines like the Carnot and Stirling engines. These are technologies essential for both the first and second industrial revolution and as a consequence also responsible for global warming (note: The 3rd industrial revolution is electric).
If however, we were to argue that Thermodynamics and Machine Learning are analogous ( i.e. bulk measurements of entropy are important) then it would be like attempting to create cognition from cycles generated by a thermodynamic engine. To emphasize the absurdity of the approach, it’s like using the heat dissipated by a modern GPU and using it to drive intelligence. There comes a point when bulk collective measurements lead to only marginal information of what it actually happening. Even in Thermodynamics, where the subject matter is inanimate objects, there are extreme limitations. Life and systems with cognition are composed of universal Turing machines. We should be cognizant of the natural limitations of approaches like Thermodynamics, Shannon’s entropy, and thus traditional machine learning methods. We need to go beyond scalar measures of information and begin to explore how cognition makes information useful.
In an abstract sense, we are exploring complex ways in which information is made useful. It is very profound, that the semantics of information, its usefulness, and its aboutness, is important due to the emergence of life. James Gibson, the ecological psychologist would refer to this as “Affordances”. Daniel Dennet describes this is more general terms as “A difference that makes a difference”. Semantics has no use for an inanimate system (in physics and chemistry). However, when the capability of autonomous life comes into play (that is machines with intentionality), then information as control or information as an obligation is superseded by information as constraints or information as promises.
Further Readings






