
The Fundamental Knowledge of System Design (10) — Consistent Hashing
It is a distributed hashing scheme that operates independently of the number of servers or objects in a distributed hash table by assigning them a position on an abstract circle, or hash ring. For example, when a hash table is resized, only n/m keys need to be remapped on average where n is the number of keys and m is the number of slots.
It is the tenth series of the fundamentals knowledge of system design. You can read my previous articles.
Recently, distributed systems have gained popularity with the emergence of concepts such as cloud computing and big data. One such system that provides distributed caching for many high-traffic dynamic websites and web applications utilizes a consistent hashing algorithm. In the cloud network scenarios, in order to support tens of millions of routes and millions of Virtual Private Cloud (VPC)s, the idea of consistent hashing is also used for reference in the system design of many high-performing distributed gateways.
The paper “Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web” was published by MIT in 1997. The idea of consistent hashing can effectively solve the problems caused by dynamically adding and deleting nodes in a distributed system. Consistent hashing algorithms are used in Memcached, Key-value store, Kademlia-based distributed hash table (Bittorrent DHT), and Linux Virtual Server (LVS).
A consistent hash algorithm proposes 5 definitions for determining if a hash algorithm is good or bad in a dynamically changing number of nodes:
- Balance — The hash result can be distributed to all buffers as much as possible so that all buffer space can be utilized
- Monotonicity — Ensure each hash result is mapped to each corresponding buffer and a new buffer is added to the system
- Spread — When the terminal wants to map the content to the buffer through the hashing process, the buffer range seen by different terminals may be different, resulting in inconsistent hash results. A good hash algorithm should be able to avoid inconsistencies as much as possible, that is, to reduce the dispersion as much as possible.
- Load — Since different terminals may map the same content to different buffers, a particular buffer may also be mapped to different content by different users. A good hashing algorithm should minimize the buffering load.
- Smoothness — The smooth change of the number of cache servers is consistent with the smooth change of cache objects.
What is Hash
A hash is the process of mapping data of arbitrary size to fixed-size values. The function that maps some data to a hash code/hash values/digests/hashes is called a hash function. The values are usually used to index a fixed-size table called a hash table.
SHA-1 (Secure Hash Algorithm 1) — It takes an input and produces a 160-bit (20-byte) hash value called a message digest
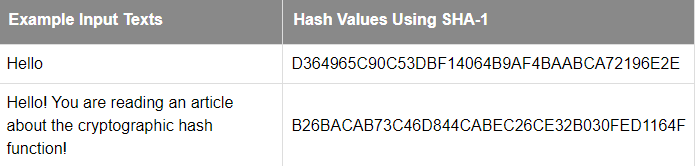
Since there are far more possible inputs than outputs, any given number will have many different strings mapped to it. A good hash function should make the output of different input values as evenly distributed over the output range as possible.
For distributed database system, data of different objects are stored on different servers. We use a hash function to establish a mapping relationship from data to servers.
The consistent hash algorithm is a method to solve mapping problems. It can ensure that when the number of servers increases or decreases, data migration between nodes is limited to 2 nodes, and it will not cause global network problems. There are 2 steps in distributing the incoming traffic.
- Map the incoming data to a numerical value.
- Map the hash value to the server
The Principle
- Use a simple hash function
m = hash(o) mod n
O= object
N= the number of the servers
M=The particular server
Assuming that there are 3 server nodes. The hash values of 10 data objects are 1, 2, 3, 4, 5, 6, 7, 8, 9, and 10 respectively
The hash function used is m = hash(o) mod 3
The data object stored on the server 1 — 3, 6, 9
The data object stored on the server 2 — 1, 4, 7, 10
The data object stored on the server 3 — 2, 5, 8
When a new server node is added, the n=4 , the data stored on each server are:
The data object stored on the server 1–4, 8
The data object stored on the server 2 — 1, 5, 9
The data object stored on the server 3 — 2, 6, 10
The data object stored on the server 4 — 3, 7
So when the amount of data objects in the cluster is large, using a general hash function will cause a large amount of data object migration when the number of nodes changes dynamically, resulting in a sharp decrease in network communication performance. It may lead to downtime in the database.
2. Ring Hash Space
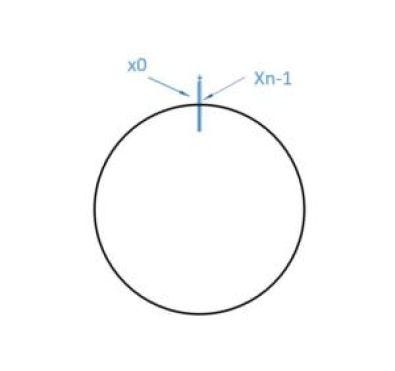
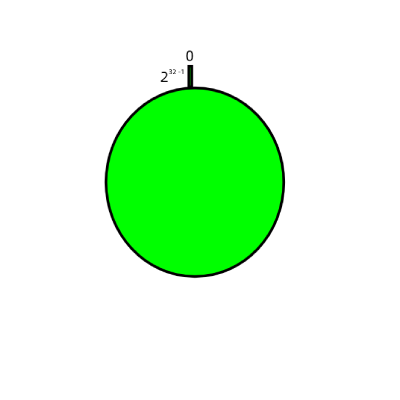
Consistent hashing organizes the entire hash value space clockwise into a virtual ring. According to the commonly used hash algorithm, the corresponding key is hashed into a space with 2³² buckets (that is, the IPv4 addresses are composed of 32-bit binary numbers, so this can ensure that each IP address will have a unique mapping). 0 and 2³²-1 coincide in the direction of zero. As shown below,
The incoming data will be hashed. The next step is to use hash functions to perform hashing on each server. Specifically, the IP or hostname of the server can be selected as the key for hashing, so that each server can determine its position on the hash ring. Then the hashed data is mapped to the ring.
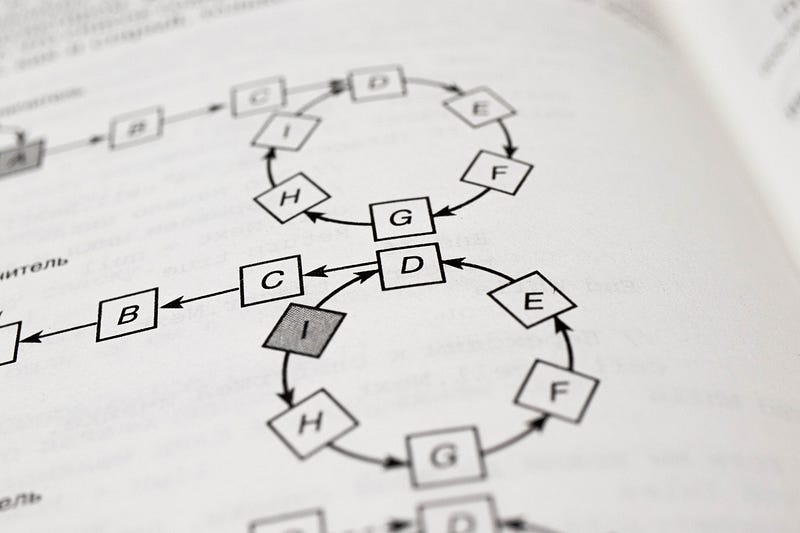
3. Map the data to the Ring Hash Space through the hash algorithm
We can calculate the corresponding key value of the 4 objects through a specific hash function, and then map them to the hash ring.
Hash (object 1) = Key 1;
Hash (object 2) = key 2;
Hash (object 3) = key 3;
Hash (object 4) = key 4
For example, the 4 data objects (Object 1, object 2, object 3, and object 4) are hashed. The positions on the ring space are as follows:
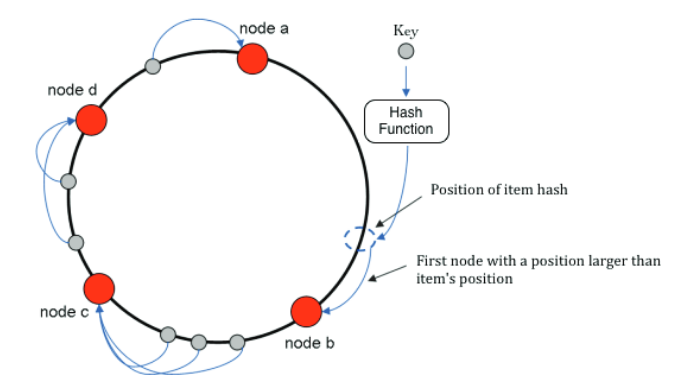
According to the consistent hashing algorithm, object 1 is assigned to Node A, object 2 is assigned to Node B, object 3 is assigned to Node C, and object 4 is assigned to Node D.
Assuming that Node C is unfortunately down, you can see that object 1, object 2, and object 4 will not be affected at this moment. Object 3 is relocated to Node D.
Assuming that a server Node X is added to the system. The object close to the server Node X is relocated to Node X.
4. Map the server to the ring through the hash algorithm
We can calculate the corresponding key value of the 4 servers node in a clockwise direction through a specific hash function, and then map them to the hash ring. The server IP or the hostname of the server is used as input.
Hash (Node A) = Key 1;
Hash (Node B) = key 2;
Hash (Node C) = key 3;
Hash (Node D) = key 4
5. Store the data on the server
So, the data object and the server are in the same hash space.
6. Add and Delete the servers
- Delete a server from the cluster
Assuming that Node C is unfortunately down, you can see that object 1, object 2, and object 4 will not be affected at this moment. Object 3 is relocated to Node D.
- Add a new server to the cluster
Assuming that a server Node X is added to the system. The object close to the server Node X is relocated to Node X. Data object on the other server is not affected.
However, when the number of servers in the cluster is dynamically added or deleted, it leads to a global data migration problem.
Existing Problems
- Avalanche Effect
When there are few nodes/nodes are concentrated in the cluster, the problem of an unbalanced distribution of nodes in the hash space may occur. The load of the server is unbalanced. If one of the nodes fails, all data stored on that node should be transferred to the closest nodes. A large number of data migrations may lead to the paralysis of the entire cluster.
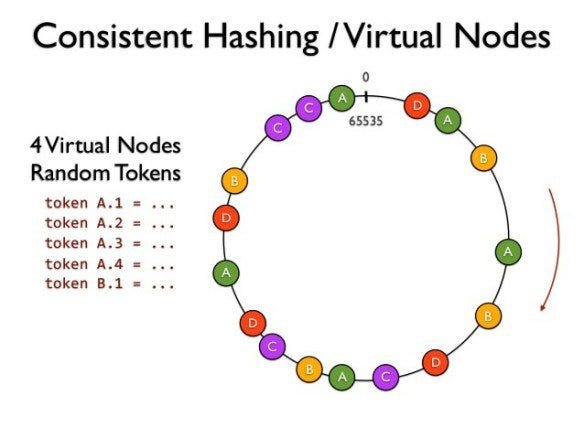
2. Workaround — Virtual Node
In order to have each node evenly distributed in the hash space, it requires as many nodes in the cluster as possible. In real cases, the number of the servers is generally fixed, add virtual nodes in the cluster.
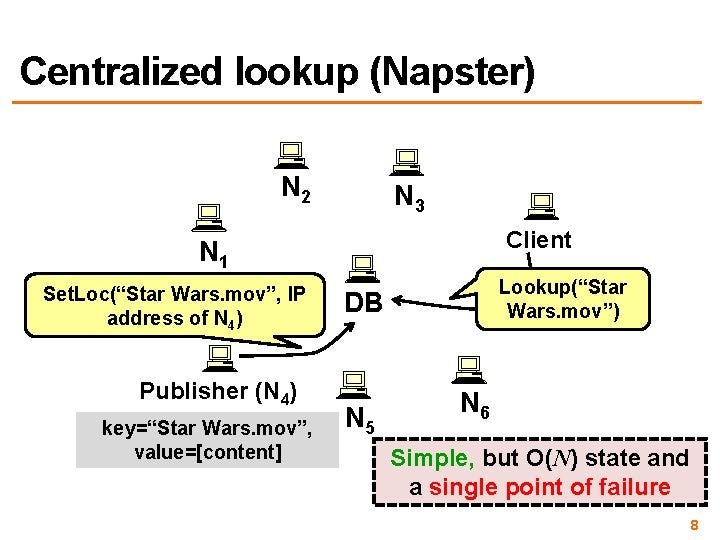
In a distributed cluster, there are 3 methods to find a physical node for specifying data storage.
- Napster — A central server receives all queries, and returns node location information for data storage. The single-point failure of the central server leads to the paralysis of the entire network. No security is required.
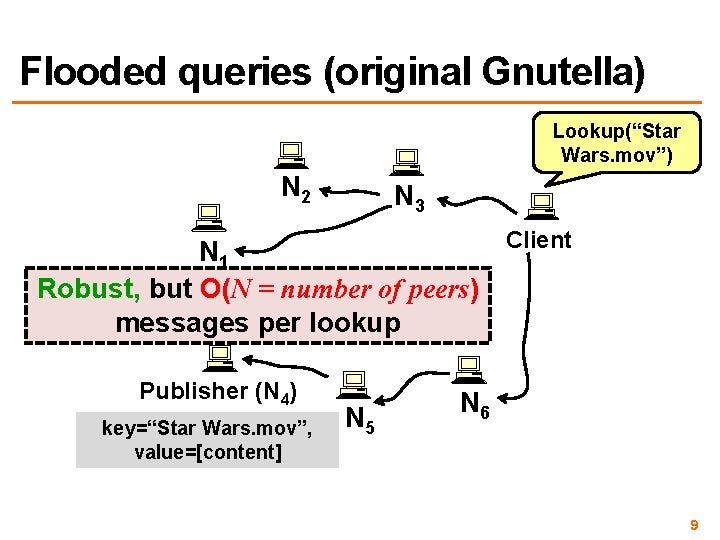
2. Gnutella — Message flooding is used to locate data objects. A message is sent to every node in the system until the right data object is found. The time-to-live (TTL)/hop limit is used to limit the number of forwarded messages within the network. The number of messages is linearly proportional to the number of nodes.
3. Super node (SN) type — It stores the index information of the nodes in the network. It is similar to Napster but there are multiple SNs in the network which propagate the index information. The probability of the entire system crashing is much lower.
Chord, Pastry, content-addressable network (CAN), and Tapestry are often used to build structured P2P distributed hash table (DHT) systems.
The main function of DHT
Each file index is represented as a (K, V) pair, whereas K is a keyword (hash value of the file name or other descriptive information of the file) and V is the actual storage. As long as the K value of the target file is input, all node addresses that store the file can be found through the hash table. The hash table is divided into many local small blocks. The small blocks are distributed to all participating nodes in the system according to specific rules. In this way, when a node queries a file, it only routes the query message to the corresponding nodes.
A chord is an algorithm that can quickly locate resources in a P2P Distributed Hash Table (DHT).
Basic elements in Chord
- Node ID/ Node identifier (NID) —it represents a physical server
- Resource ID/Key identifier (KID) — It represents a resource and the key is hashed with a resource value.
- Constant hash function — SHA-1, SHA-2, other hash calculation
- Chord Ring — Node distribution and resource positioning
- Chord Resource Location — The core function of the Chord protocol. Each node only stores its successor node information. When initiating a query, the node first searches locally. If not, it asks its successor node. If the hash value of resource K is between the current node and the next node, it means that the resource is stored on its successor node. If not, the next node issues the same query to its successor node until found hash (N) > hash (K).
- The number of queries is linear with the number of nodes, and the time complexity is O(N). For a P2P network with millions of nodes, the nodes frequently join and exit, and the time complexity is unbearable. So, the nonlinear search algorithm is used.
6. Routing Tables — A routing table with at most m items (m is the number of bits of the hash result) is maintained on each node N to locate resources.
- Chord Routing table — Each node only contains the information of a small block of the hash table in the whole network
Further Study
A Fast, Minimal Memory, Consistent Hash Algorithm
References
If you’ve found any of my articles helpful or useful then please consider throwing a coffee my way to help support my work or give me patronage😊, by using
Last but not least, if you are not a Medium Member yet and plan to become one, I kindly ask you to do so using the following link. I will receive a portion of your membership fee at no additional cost to you.
It is my first affiliate program, if you like to further enhance your system knowledge, you can click the links and buy the course. Honestly speaking, I will receive 20% of your course fees at no additional cost to you. You will have unlimited access to our courses. There is no time expiry and you will have access to all future updates free of cost.





