
When personal data isn’t.
Should we use Twitter data?
We can use social media data for research, that doesn’t mean we should
Introduction
This post delves into the following concerns:
- Informed consent — Organisations use Twitter data, without informing users.
- Anonymity — User’s content has a high risk of reidentification.
- Right to withdraw — Users have no ability to revoke scraped data.
Twitter can solve these problems. Academia could help set a precedent with the addition of an ethical review process. Academia could encourage the treatment of Twitter data as personal data.

Working with Twitter data
In March 2021 I began exploring Twitter as a data source for research. Throughout this process, I found tweets that were evidence of hate crime, contained nudity and beyond. Most presenters would not be enthusiastic about using these tweets in front of an unsuspecting audience. The likelihood of plucking a problematic or shocking Tweet mid-talk was so high that I had to add a warning slide.
As part of the recent Research Methods e-Festival I revised this talk with a focus on the ethics of using Twitter data. I asked attendees a variety of questions about the use of Twitter data in various scenarios. This post will introduce the questions I asked the attendees. Further, I will explore the answers given by 42 attendees. Finally, I offer my interpretation of these results and suggest future work. A full recording of this talk is available here.
These results carry a heavy bias. All attendees represent some level of academia. All academics are well-informed on the ethical use of data and understand data privacy. A similar group of data practitioners replicated these results.
All data used in this blog post is available on the UK Data Services Github.
Is it okay to use Twitter data?
Scenario 1 — “The University of Manchester is doing a study on how hate speech relates to veganism and plant-based diets. Your tweets about food and veganism have been scraped.”
In this scenario, a researcher has scraped your Twitter data. Using Twitter’s new academic API tier researchers can collect 10 million tweets, per month. Consider the following questions before my reflections:
- Is it okay for Twitter data to be scraped by academics in this way?
- If you were given the option, would you consent to your data being scraped and used for this study?
- How would you feel if the University of Manchester contacted you to thank, inform or compensate you that your public data had been used for this study?
Question 1 — Is it okay for Twitter data to be used in this way?
This scenario presents a “good” justification for the research. Most attendees aren’t tweeting hateful content towards vegans. Society incentivises individuals to “donate” their data in scenarios that look good. Many would offer this data when asked, even if it was private. Refusing to share your data here may suggest that you have something to hide. Do you have something to hide? Would you change your answer if you did, or didn’t?
We can see below that many users consider this an acceptable use of public data. Some are unsure, and few reject this idea.
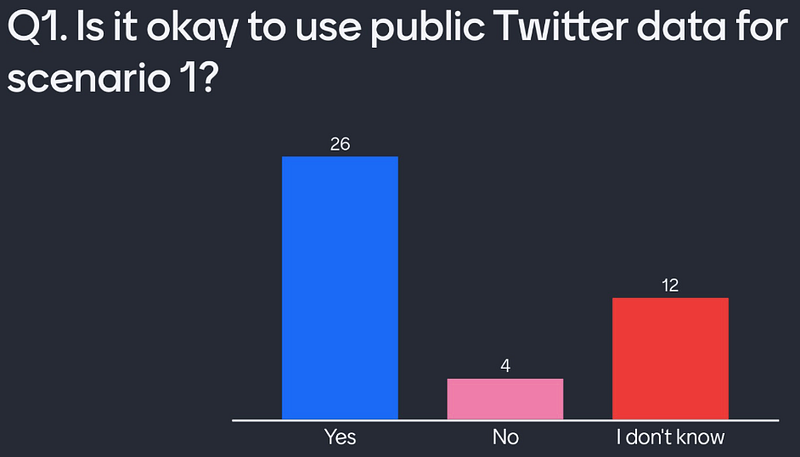
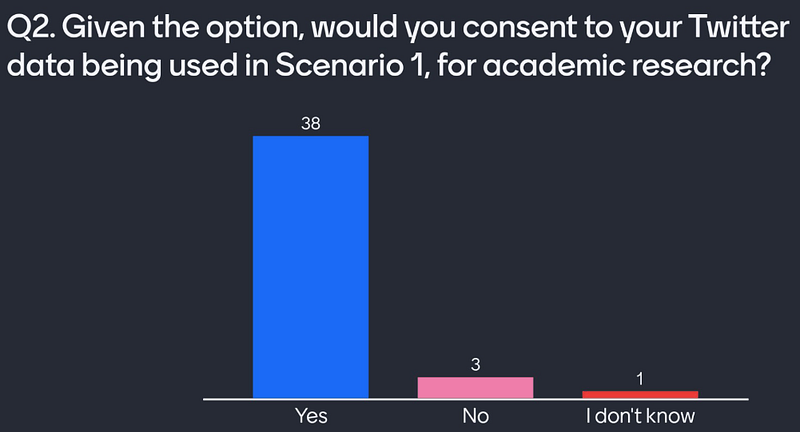
Question 2 — Given the option, would you consent to your Twitter data being used in Scenario 1?
Here I offer attendees the option of informed consent for our research. This is not an option that users currently have. It appears here that anybody unsure about the ethics has changed to the approval of the donation of their data. Despite this, some would still reject this “donation”. If this were any other personal data source, we would not take the data of these users without this consent.
Question 3 — How would you feel if an academic body reached out to you to thank, inform, or compensate you for your public data in Scenario 1?
Here we observe a phenomenon. We grant an illusion to Twitter users that their content is only observed in the way they intended. With silent scraping, we assume informed consent. When we contact a user to inform them, they become uncomfortable. Some users are well-informed on the use of their data but “would not want to be contacted”. Most responses feel some sort of confusion from this contact.
One user calls out that it would depend “if I’ve been saying anything controversial”. This brings up a fantastic point. At the time of tweeting, we all think we are saying the right thing. We may also be well-supported by a community. An academic study, or business product, was not the end goal of a tweet. In my talk, I highlight a tweet as being the most negative perception of veganism on Twitter. I doubt the user wanted that, but they don’t get a choice. I am confident worse is happening.

Are we so bold, to say we will forever be on the correct side of all issues as time moves forward?
Scenario 2 — A large tech company has scraped Twitter data on the locations you visit, how long you spend there and how often you visit. They are using this data to profile you and target you with effective location-based adverts.
In this scenario, your data has been scraped by industry, for profit. Consider the following questions before my reflections:
- Is it okay for Twitter data to be used in this way?
- If you were given the option, would you consent to your data being used for this study?
- How would you feel if a business reached out to you to thank, inform or compensate you for your public data in scenario 2?
Here I hoped to present an opposite use of Twitter data. This is a huge misuse of public data, pursued by industry. The methods which enabled scenario 1, also enable scenario 2. The contents of a tweet affect a user’s consent. The intentions of the organisation doing the scraping also affect the consent given.
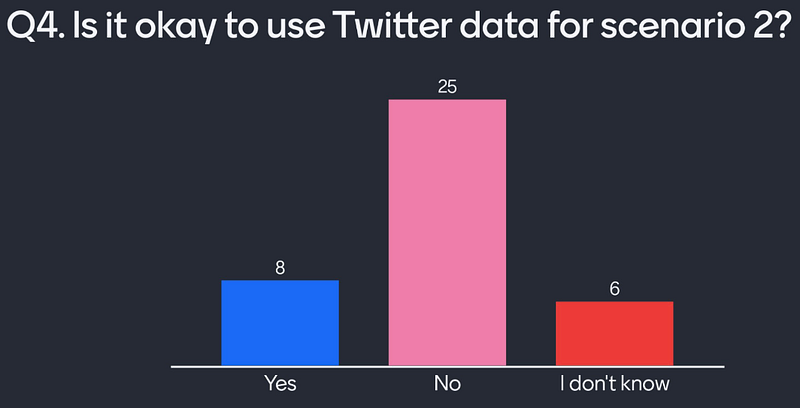
Question 4 — Is it okay for Twitter data to be used in this way?
Given a new, nefarious example, we ask again if this is an acceptable case for the use of public Twitter data. Some users stay confident that this data is public, and hence anyone can use it. Most users do not like this use of Twitter data, despite this being the way all major social media makes its money.
Q5. Given the option, would you consent to your Twitter data being used in Scenario 2?
Again, I offer an imaginary scenario where we can control our data. Without the pressure to “donate” our data, this becomes akin to theft. Organisations monetize public Twitter data, without compensating users. Users don’t like this, and the end-product seeks to manipulate users. The average attendee would not consent to this use of Twitter data.
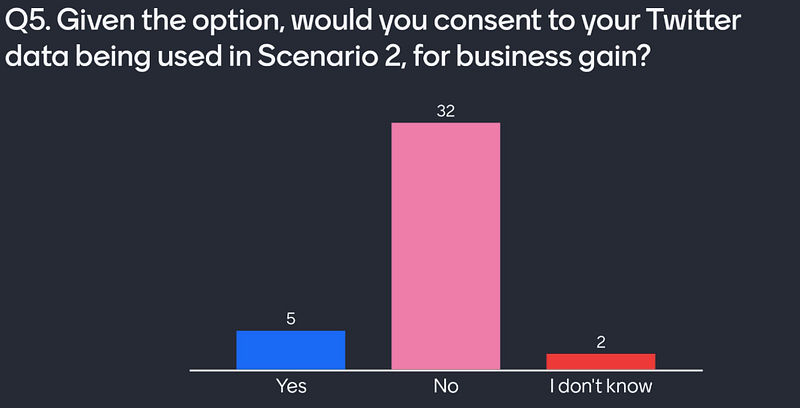
We must remember that the users are the product in these social media. The service is free to use. A follow-up question I would love to ask here is “Would you pay to use Twitter?”. These contradictions become uncomfortable when focused on. Is this a symptom of a lack of informed consent?
Q6. How would you feel if a business reached out to you to thank, inform or compensate you for your public data in Scenario 2?
Attendees hated this question. Most users report feeling “Irritated”, “Angry”, “Spied on” and similar. GDPR now protects users in this scenario. The industry will scrape user data to predict stock prices, political outcomes and beyond. They simply do it silently.

Ethics and Responsibility
That ends our focus on scenarios. I will now dig deeper into why Twitter data is personal data, why that is concerning and what we can do about it.
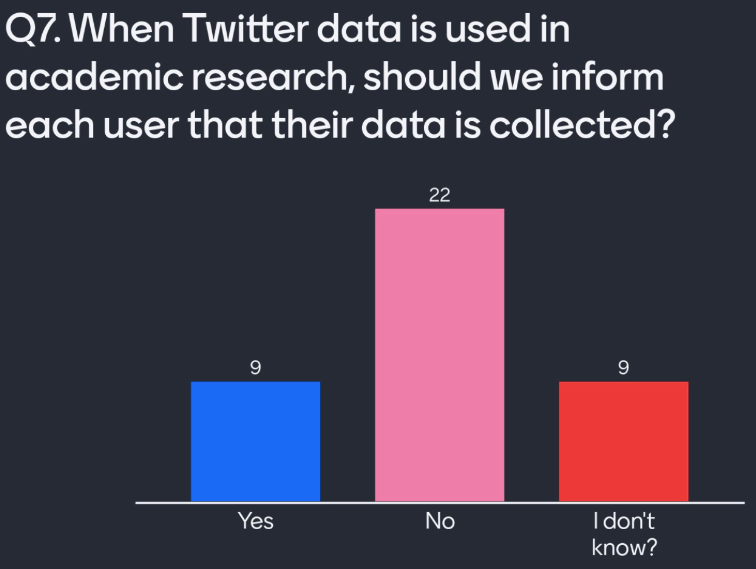
Question 7 — When Twitter data is used in academic research, should we inform each user that their data is collected?
In a traditional study involving personal data, we know to seek informed consent from participants. We also give these users the right to revoke their data at any time. In Twitter data, it seems that the large volume of tweets provides a baseline of anonymity.
Without contacting these users, we cannot offer informed consent. When we do contact users to give this option, we make them uncomfortable. We also bias our research in our observation and only accept data from users who consent. Most attendees know that informing Twitter users, in this case, is a breach of GDPR.
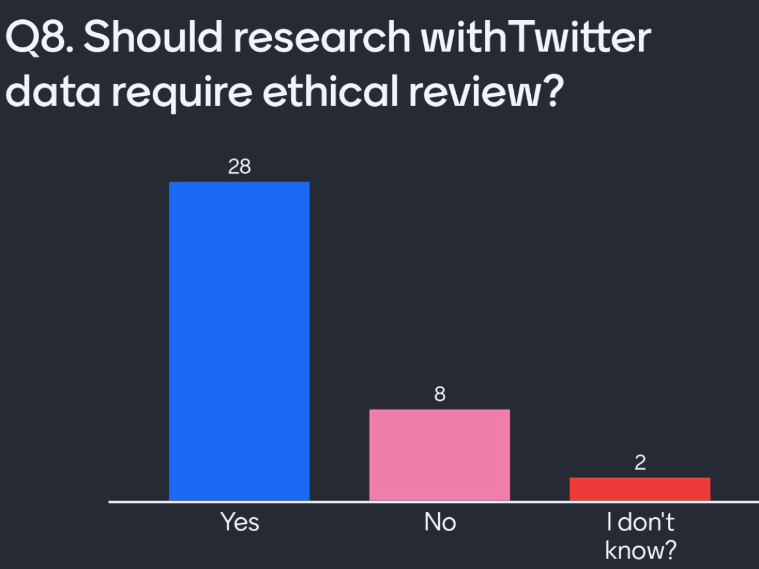
Q8. Should research with Twitter data require ethical review?
All UK Universities require that an ethical review approves studies using personal data. Some universities have stated that Twitter data needs an ethical review. This is the first step for academia. In this question I seek to check the attendee’s response to this, not knowing the process.
Most attendees believe that social media data should require an ethical review.
Q9. All Universities require that personal data and related studies go under ethical review. Is the text from tweets personal data?
With this question, I make it clear that personal data goes under ethical review. I introduce the paradox of a tweet being both public and protected personal data. Googling most tweets will return you to the live tweet. This means text, alone, is enough to reidentify a user.
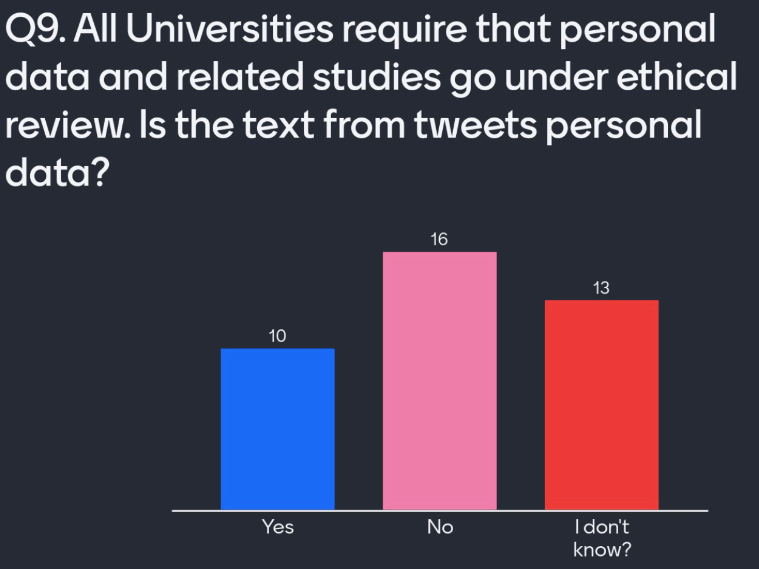
Attendees recognise the nuances of this edge case in our definition of personal data. The risk of reidentification is high, but the data is public. The correct answer here depends on the Tweet. It also depends on who is collecting the data, and why they want it.
Who is responsible for solving this problem?
Q10. How responsible are each of the following groups in making sure Twitter users and their data is safe?
A common retort to some of these arguments is that parents and schools are responsible for raising children. Digital hygiene is now part of the curriculum at many schools. Another is that the government should intervene and manage businesses making unethical use of data. The government can introduce data protection legislation. I wanted to find out how responsible my attendees thought each group was for the safety of Twitter data:
- Parents
- Schools
- The User
- The Government
- Academic Institutions
- Industry
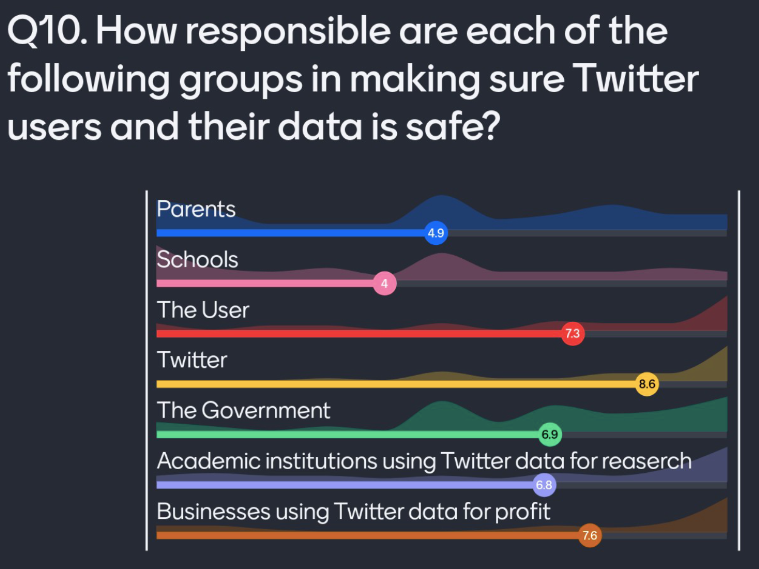
What I found every time I ran this survey was that the bulk of responsibility lies on Twitter itself. They are the only ones in the position to trace the collection of their data. They are best equipped to provide informed consent, and the right to be forgotten to academia.
Attendees felt parents and schools had the least responsibility. Many felt they had zero responsibility. The average Twitter user is 25 or above, and unlikely to be a child. We can hope these groups are equipped to prepare the next generation of social media users. We cannot understand the risks the generation will face online.
Attendees place a lot of emphasis on the user being responsible for their own use of data. I call this the “you should know better” argument. We require a user to understand how their data will be misused, which they don’t. This may appear simple. Don’t tweet things that are insensitive. We can’t predict the next insensitive trend. So how can we expect perfection from the future? Users generally don’t read the terms of each platform. The methods Twitter uses to educate users do not work.
Attendees have a wide range of opinions on the responsibility of the government. The government is able to enforce and legislate to protect Twitter users. The data protection we need is usually a few years away. We also need some consequences of unprotected data to arise to press urgency. This all comes too late but must come.
Businesses making use of Twitter data can fund Twitters development for better data use. There is a conflict of interest here though, a business will generally want the most data it can get, for the cheapest price. While there may be some progressive businesses questioning the ethics of this data, generally this is not the case.
Academia can encourage better use of social media data. A quick win here would be the requirement of an ethical review for social media data. This begins the process of protecting users in collected social media data. Twitter needs to update their offering to academics to solve the remaining issues. The academic tier shows they are considering academia, but more needs to be done. I fear Twitter sees this as a social good “donation” of data to offset misuse in other fields.
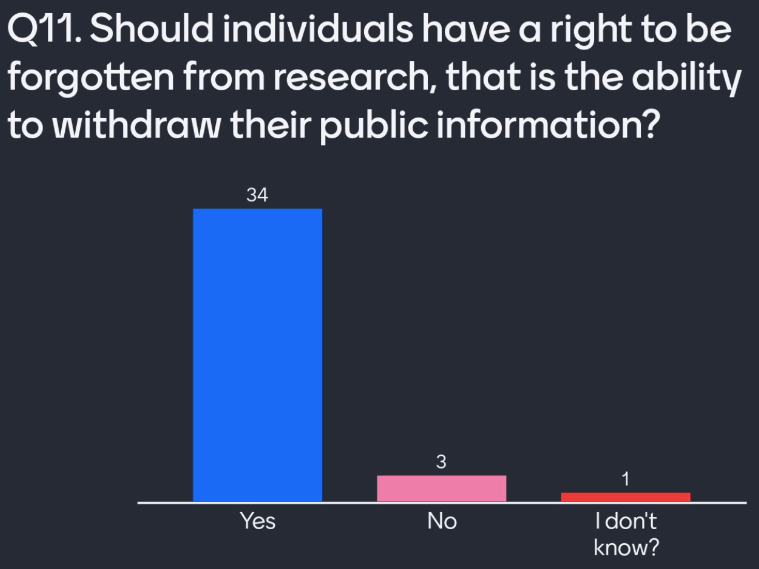
Q11. Should individuals have a right to be forgotten?
Academics know that individuals should have a right to revoke their data. GDPR has added some power for individuals to have the right to have their public information withdrawn from datasets.
Twitter doesn’t inform a user when an organisation scrapes their content. Without accountability here, there is no method for the user to revoke their consent. A user can delete or hide their account, but this does nothing to protect them retroactively.
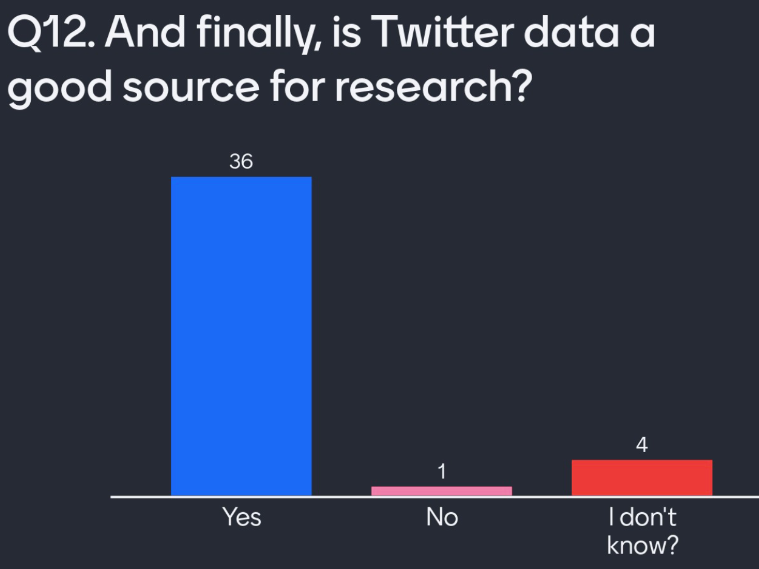
Q12. Is Twitter a good source for research?
Finally, attendees agreed that Twitter is a good source of data for research. Missing from this question was a disclaimer about the bias of Twitter data. Each social media platform presents its own bias in the users that choose to use it. Twitter users don’t represent individuals who don’t have access to the internet. Twitter users are on average American, 25–34-year-old males. If we inform policy based on this, we need to make this bias clear. We can also take steps to reduce this bias in our sampling of tweets.
Should we be able to use Twitter data in Research?
We should be able to use Twitter data.
A primary argument is that this data is already public, so protection is redundant. The intention of many social media platforms is to surface your content to as many people as possible. That is the point. To say a user didn’t understand that may seem ridiculous.
We also feel that users who post compromising content should know better. If you don’t want to get in trouble as a user for posting something racist, sexist, or homophobic don’t post it.
This dataset is valuable. Any user can gauge the public perception of themselves, a political party, a share price and beyond. Why ignore such a powerful dataset over a small privacy concern?
Finally, as this is public data, we no longer must deal with GDPR or future data legislation.
We shouldn’t be able to use Twitter data.
With some intervention, I think we could ethically use this data.
Social media is designed to share content. Despite this, not all Twitter users hope for their content to be observed by all. Consent to data misuse is not the default. Consider the following:
- Do children understand how their data will be used?
- Do adults understand how their data will be used?
- Did all users anticipate that Machine Learning would enable insights from their data?
- Did all users anticipate this could lead to targeted advertisements and political manipulation?
- Are all users confident that we won’t find more powerful ways to misuse this data?
- Do all users feel their historic tweets, do not contain dated views?
In an academic study, and under GDPR we must collect consent to use Twitter data. Many users expect their followers to see their content. Some users may hope that nobody outside this circle sees their content. This is an underused option, and it is available. If we reach out to users to inform them of the use of their data, many are upset. The context of a tweet, the organisation, and the purpose of scraping affect this upset.
As original Twitter content is usually unique, it also identifies the individual. In any study, we work hard to minimise the risk of the reidentification of our participants. The justification here may be that the data is public. is it possible that public and observed mean different things?
And finally, in a traditional study, we would give all users the ability to revoke their data at any point. We don’t offer this option when the data source is social media. If we did, even informing the users that we have their data makes them uncomfortable. An academic can scrape up to 10 million tweets a month. Removing thousands of revoked data points every few days is not trivial work. How can we give users the right to withdraw? Who is responsible here?
Conclusion
At this point, the University of Manchester has released “over 500 published works” which make use of Twitter. Are we already too late to change this?
The University of Warwick has decided that ethical review is needed. In some cases, projects making use of social media requires ethical review.
“the exemption applied to publicly available data did not automatically apply to social media data”.
In regards to Twitter data, we need a solution to the following:
- Informed consent — users have no idea how often their content is scraped, or to what ends it is used. Trying to inform users leads to disgust. Twitter is in the position to solve this.
- Anonymity — Any user can scrape names, locations and other protected features. A user can reidentify a tweet by googling the content of that tweet. We could shortly provide statistical disclosure control of text data to protect anonymity.
- Right to withdraw — As users aren’t informed, they have no idea they need to withdraw from anything. If they could withdraw, how would researchers manage this after scraping millions of users? Twitter is in position to solve this.
- Ethical review — Universities should step up and accept that social media data requires some form of protection. Making ethical reviews of social media data is the first step in this process.
Thank you, and if you have any questions feel free to contact me at [email protected] or @JosephAllen1234.