Machine Learning
The Disadvantage of MSE Loss and How to Remove Them
How to improve the results obtained using Mean Squared Error Loss

Mean Squared Error is one of the most used and most straightforward regression-based loss function in Machine Learning and Data Science. It’s is used in a range of tasks such as Linear Regression on tabular data to specific use-cases in computer vision, NLP, Reinforcement Learning, etc. In addition to MSE, MAE is also widely used and is highly similar to MSE Loss.
Despite being highly used in Machine Learning, it has its share of flaws, which I would like to highlight in this article. There are specific ways to minimize its weaknesses to get better results, which are discussed at the end. The discussion and use-cases are kept relevant to computer vision for simplicity and better understanding.
Disadvantage:
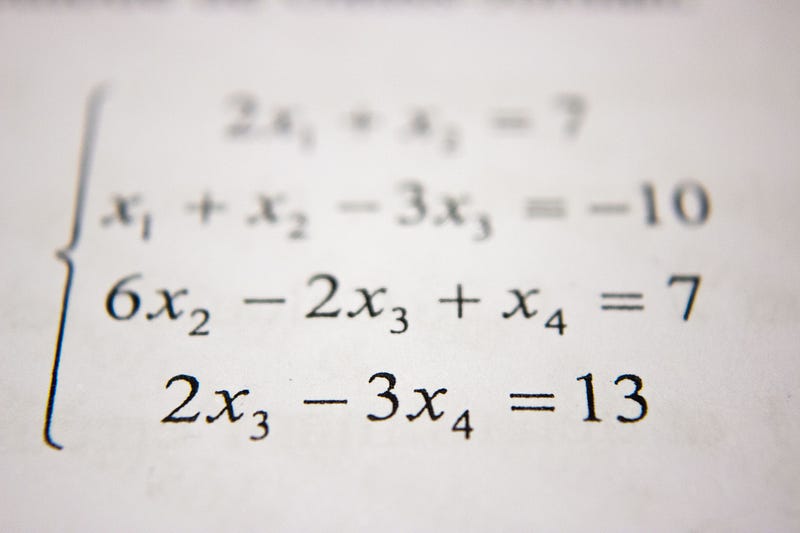
Loss functions such as MSE, MAE usually suffer from the uncertainty present in the dataset. While training the model, it can be the case where there can be various equally probable outcomes for the same input. In all such cases, the MSE Loss function aims to accommodate the uncertainty in predictions by blurring the predictions or, in simple words, taking the average of the possible outputs. This is because the average of all possible outcomes would lead to global minima in parameter space during training. Similarly, MAE loss predicts the median of all such results. This blurring of results by L-norm based loss functions leads to artifacts such as low-quality results, blurring, etc.
These artifacts are common in image-to-image and video-to-video tasks such as Super Resolution, Video Prediction, Structured Prediction, Camera Pose Regression, etc.
Statistical Explanation:
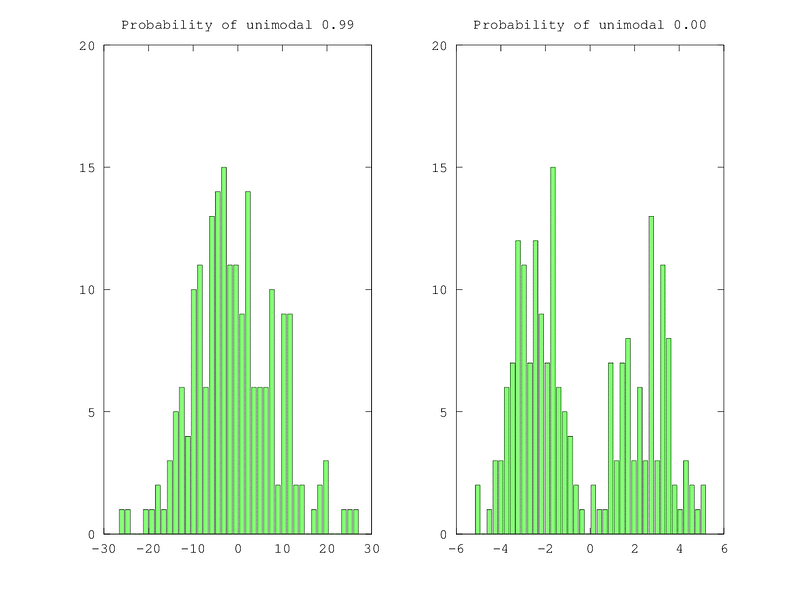
The loss function assumes that the data samples in the dataset follow Gaussian distribution, which is hardly the case for any real dataset. This assumption also leads to the constraint that the dataset distribution should be unimodal in nature, which implies that there should be the only most probable outcome. This assumption fails severely in most cases since real-life datasets.
If the dataset distribution is not unimodal, and MSE Loss is used for training the network. It will then try to fit the multimodal distribution as a Gaussian distribution, which usually means that the peaks are averaged in the case of MSE Loss or the median is merged in the case of MAE Loss.
Using MSE Loss, the prediction which is the average of all possible outcomes from the network would try to minimize the error as the prediction obtained would be the global optimum, thus avoids finer details such as facial features and subtle inter-frame movements as they are considered as noise by the network.
How to improve the results?

To improve the results, machine learning researchers have tried many different approaches to solve the problem of averaging the possible predictions. It should also be taken care of that most of the network is deterministic, i.e., since they return the same result for the same input. Most of the neural networks are designed in a way to produce the most probable outcome rather than returning many possible outcomes.
Many different approaches were given to solve the above-discussed problems in the MSE Loss function, the two most commonly used approaches are as follows
- Adversarial Training
- Perceptual Loss
Adversarial Training:
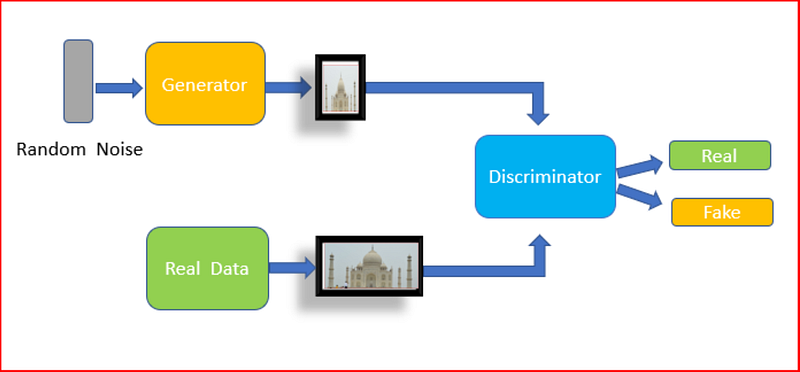
Since the advent of GANs in 2014, research has exploded and improved the results to generate output by modeling a data distribution using a minimax game. In adversarial training, a discriminator is used to train the model by competing for the network prediction with the samples from the dataset. Using a discriminator help, the network produces subtle textures and remove the blurring effect.
However, it should be noted that the textures introduced by using adversarial training are superficial and do not correspond with the ground truth.
Perceptual Loss:
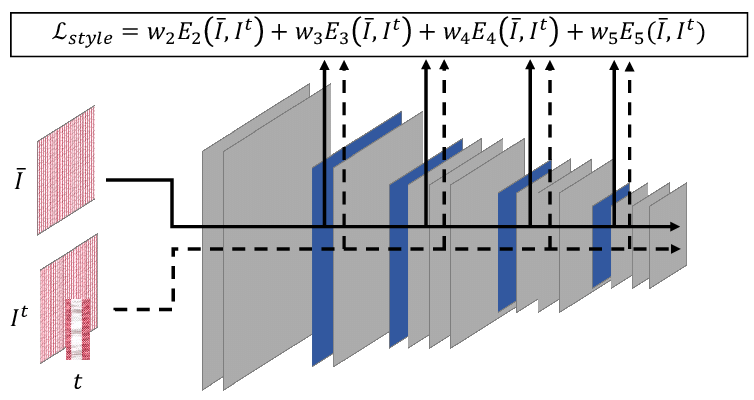
In the perceptual loss, the ground truth and prediction are passed through a pre-trained neural network, and the MSE of intermediate layers is calculated as the loss. The most common network used in this process is VGG19 trained on ImageNet Dataset. The first five layers of VGG19 is used for this process.
The argument for using perceptual loss is that it extracts features and representations of the output image/video and tries to minimize the difference between them. So, it is argued that by using the perceptual loss function, the network is trying to learn about the subtle features of the dataset distribution.
This loss is used in conjunction with the MSE Loss and usually has a <1% coefficient during training because many images can have similar textures. It is the similarity between the images that we are trying to learn rather than the textures. So, most of the time, it is usually used as a regularization.
Conclusions:
Using all these methods to reduce the effects of averaging has been proven to be of some help and give some better results. But still, most of the approaches rely on pixel-wise distance-based loss functions. Therefore, regression to the mean problem is still an active research area.