
The Computational Cost of Writing Clean Code
Performing tests on the computational cost of repeated variable assignment

Why do people sometimes write code like this?
var = float(str(alist[::-1][0]).split()[1:4])/3+float(alist[4:])The answer: to save computational time. When the code could be instead expanded with only three lines more…
var = alist[::-1][0]
var = str(var).split()[1:4]
var = float(var)/3
var += float(alist[4:]…the computational cost budgeteers shake their head and opt for the former.
Repeated variable assignment takes up computational space, they say, so much that with the number of iterations in their code it makes a significant difference.
In this article, I’ll explore what the true computational cost is of writing code cleanly with multiple variable assignment with multiple tests.
First — The Benefits of Multiple Variable Assignment
Especially in a language like Python, where there are at least ten ways to write anything, developers will often cram several operations into one line.
Multiple variable assignment allows the reader to take in the functions applied in smaller batches. Additionally, it makes it easier to pick through the layers of parenthesis present when more than three Python functions are applied:
list(str(int(x)+1)+'1') #the scope is incredible difficult to read.More so, it is difficult to track the state of the variable when it is all crammed into one line. It’s like teaching maths — the teacher starts with arithmetic first, then calculus later, instead of teaching both simultaneously.
Multiple variable assignment means the reader can track what happens to the variable and what status the variable is in, much more easily in four lines than one line.
In many cases, multi-variable assignment saves computational time. Take, for example:
a = (b+5)*5 + (b+5)/4which could alternatively be written as
c = b+5
a = c*5 + c/4By assigning (b+5)to one variable, it is calculated only once instead of multiple times.
Testing on Python Lists and Built-In Functions
Here’s one test for computation time that uses several common built-in Python functions like str(), list indexing, and mathematical operations:
float(int(str(alist[::-1][0]).split()[::-1][0])/int(alist[:4][0]))/3Which was alternatively written cleanly as:
var = str(alist[::-1][0]).split()
var = int(var[::-1][0])
var /= int(alist[:4][0])
var = float(var)/3“alist” is generated as:
alist = [random.randint(1,10) for j in range(100)]The time used to generate the list was not included in the timing. The only operation that was timed was the line(s) of code that ran the test operations.
This operation was run 5,000,000 times with a differently generated alist for each run.
The average was taken every 100,000 times and plotted, where “cleaned” denotes the four-line version of the target code and “shortened” denotes the one-line version of the target code:
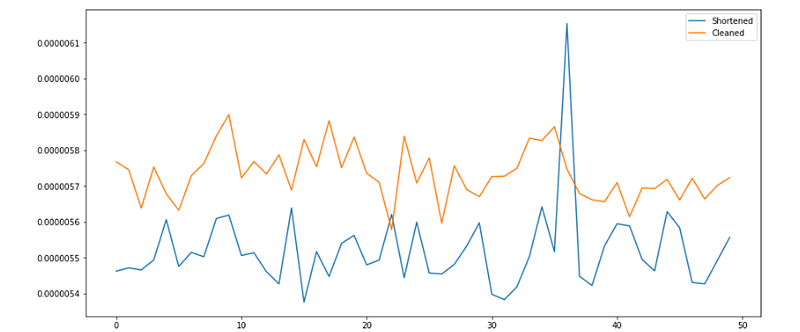
The shortened version clearly performs almost universally in a faster time, but on such a small scale, it wouldn’t be very beneficial at all.
The average shortened version time to run was 0.000005521, and the average clean version time to run was 0.000005733. The difference is 0.000005521.
That means that in order to see a one-minute difference in operation time, the process would need to be iterated at least 10,867,596 times. To see an hour difference in operation time, the process would need to be iterated at least 652,055,786 times.
Testing on Pandas DataFrames
A secondary test would be to perform operations not only on Python lists, but Python Pandas DataFrames. These are the essential data type of machine learning and data science in Python and resemble an Excel spreadsheet.
The test operation is:
df.loc[1:100][df.loc[1:100] > 5][‘b’].dropna().std() — df.loc[1:100][df.loc[1:100] < 5][‘a’].dropna().mean()Where df is the DataFrame. Some documentation:
data.loc[x:y]selects the rows of data whose indices are between x and y, inclusive.data[data[‘column’] > 5]selects the rows of data whose column, in this case namedcolumn, is larger than five (or some other condition) and returnsnanfor rows that do not meet the criteria.data.dropna()drops any row that has annanvalue.column.std()takes the standard deviation of a column/series of numbers.column.mean()takes the mean of the column/series of numbers.
The test operation can be split into six lines with three variables:
result0 = df.loc[1:100]
result = result0[result0 > 5][‘b’]
result = result.dropna().std()
result2 = result0[result0 < 5][‘a’]
result2 = result2.dropna().mean()
result = result — result2The test operation was performed on a randomly generated DataFrame with two columns, a and b, and 200 rows. All the values were randomly selected from 1 to 10, inclusive.
The test operation, in both the cleaned and shortened versions, was run 50,000 times, with an average taken every 1,000 times. Every repetition was performed on a new, randomly generated DataFrame.
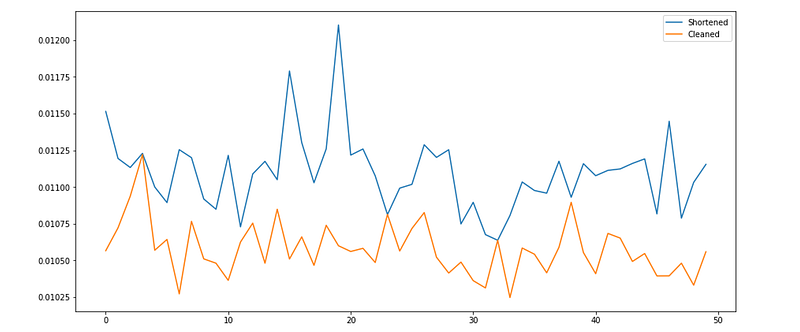
Interesting! The cleaned (expanded) code performs, on average, better than the shortened code.
The average shortened was 0.0111 per iteration, and the average cleaned run was 0.0106. The 0.0005 difference means that by writing clean code when dealing with DataFrame operations, 120,000 iterations could save one minute of computing time. 7,200,000 iterations will save one hour of computing time.
Conclusion
The lesson to learn — write cleanly! Don’t be afraid of increased computational time because of multiple variable assignment. Not only does using it increase clarity of code, it can, in some cases, (as demonstrated by the Pandas DataFrame experiment) improve computational performance.
If you want to replicate these experiments, the source code and outputs are available on Kaggle here:
Thanks for reading!