
The Cloud Native Architecture and the Cloud Native DATA Architecture

Evolution of Servers
Bare-Metal Servers
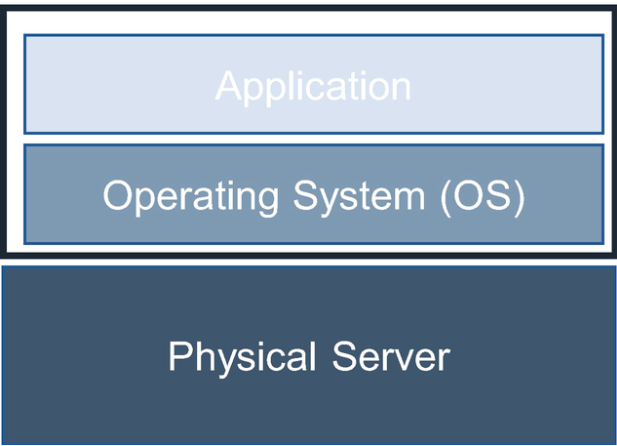
Each server offered for rental is a distinct physical piece of hardware that is a functional server on its own; in other words, each physical box hosts one piece of hardware.
Virtual Machine (VM)
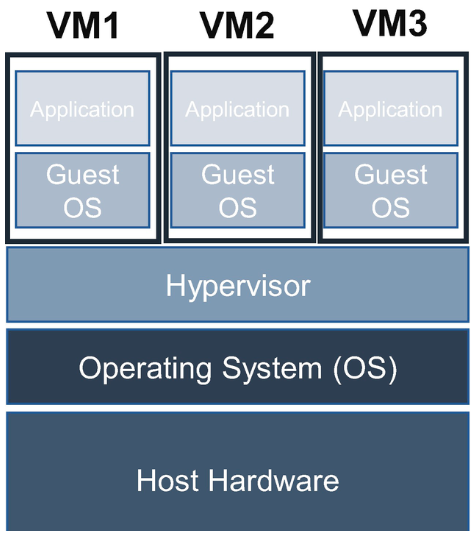
Virtualization uses the same physical hardware, but rather than installing a single OS and running a single workload on that physical box, install a hypervisor OS and set it up to support multiple virtual machines or virtualized servers that can run many different business applications simultaneously on one physical server.
The VMs are hosted with their CPU, memory, network interface, and storage on physical hardware. The hypervisor separates the single physical server resources from the hardware and provisions them appropriately so the VM can use them. The VMs using physical server resources are guest machines, computers, and OSs. The hypervisor treats compute resources such as CPU, memory, and storage as a pool of resources.
Container
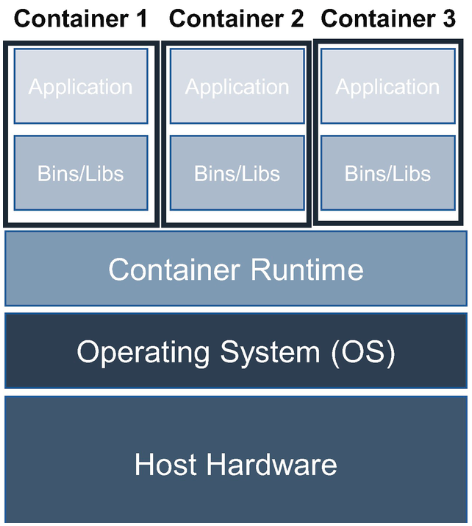
A container is a standard unit of software that packages the application code and all its dependencies so the application runs quickly and reliably and is abstracted from the environment in which it runs. It is a lightweight, standalone, executable package of software that includes everything needed to run an application. This decoupling allows container-based applications to be deployed easily and consistently, regardless of whether the target environment is a private data center, the public cloud, or even a PC. The container uses the same physical hardware and OS but in an isolated, lightweight silo for running an application on the host OS. Each container can host a single service or multiple services, depending on the nature of the services.
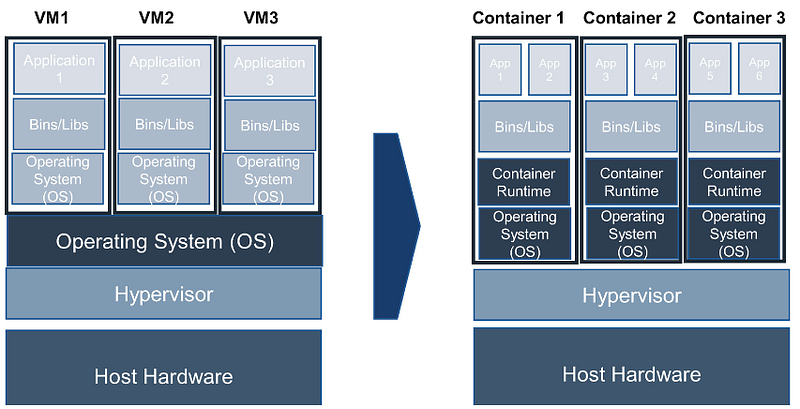
High-level comparison between VM and Container
The various Cloud services
SaaS (Software as a Service):
Office 365 (Microsoft), Google Workspace (GCP), Salesforce (AWS), Oracle Cloud Applications (OCI)
IaaS (Infrastructure as a Service):
Amazon EC2 (AWS), Azure Virtual Machines (Azure), Google Compute Engine (GCP), Oracle Compute Cloud Service (OCI)
DaaS (Data as a Service):
Amazon Redshift (AWS), Azure SQL Database (Azure), Google BigQuery (GCP), Oracle Autonomous Data Warehouse (OCI)
CaaS (Containers as a Service):
Amazon Elastic Kubernetes Service (EKS) (AWS), Azure Kubernetes Service (AKS) (Azure), Google Kubernetes Engine (GKE) (GCP), Oracle Container Engine for Kubernetes (OKE) (OCI)
PaaS (Platform as a Service):
AWS Elastic Beanstalk (AWS), Azure App Service (Azure), Google App Engine (GCP), Oracle Cloud Platform (OCI) offering various services like Oracle Application Container Cloud Service
FaaS (Function as a Service):
AWS Lambda (AWS), Azure Functions (Azure), Google Cloud Functions (GCP), Oracle Functions (OCI)
Other Services:
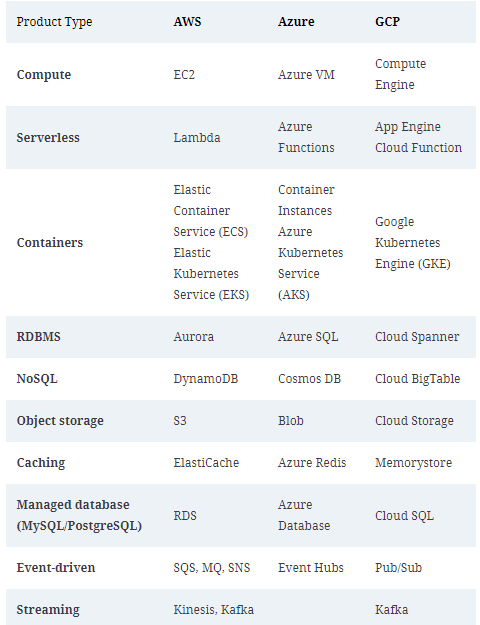
AWS: Amazon S3 (Object Storage), Amazon RDS (Relational Database Service), Amazon DynamoDB (NoSQL Database), Amazon SQS (Message Queue), Amazon Kinesis (Streaming Data), Amazon ECS (Elastic Container Service)
Azure: Azure Blob Storage, Azure SQL Database, Azure Cosmos DB (NoSQL Database), Azure Service Bus (Message Queue), Azure Event Hubs (Streaming Data), Azure Container Instances (ACI)
GCP: Cloud Storage, Cloud SQL (Managed MySQL and PostgreSQL), Firestore (NoSQL Database), Cloud Pub/Sub (Message Queue), Cloud Dataflow (Stream and Batch Processing), Cloud Run (Container Instances)
OCI: Object Storage, Autonomous Database (Managed Oracle Database), Streaming (Streaming Data), Oracle Messaging Service (Message Queue), Oracle Data Flow (Stream and Batch Processing), Oracle Container Engine for Kubernetes (OKE).
Microservices Architecture and Design
A microservices architecture is an approach to developing one business application as a suite of domain services, with each domain service running on its container and communicating with a lightweight mechanism synchronously or asynchronouslyby using HTTP, GRPC, or messaging. These domain services are developed around business capabilities using independently deployable but fully automated deployment tools. Each domain service is decentralized and developed with the polylithic and polyglot principles in mind.
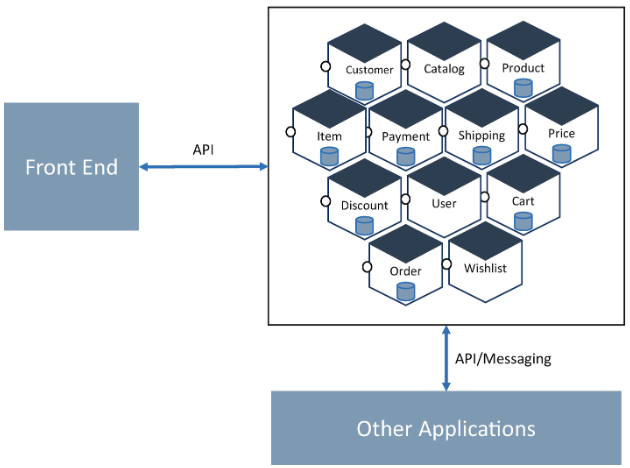
Characteristics of Microservices
Organized Around Business Capabilities
Autonomous
Microservices are self-contained units of functionality with loosely coupled dependencies across other services. They are separate entities deployed in an isolated container environment. All communication between microservices is through network callsusing HTTP, GRPC, and messaging protocols to enforce separation between the services.
Smart Endpoints and Dumb Pipes
The first approach is to create custom code in the microservices logic as smart endpoints and use HTTP or message queues as dumb pipes. The drawback of this implementation is that you need to manage the code, implementation, and collaboration across various decentralized teams.
The second approach is to create smart pipes like ESB. This is an anti-pattern. Microservices solve this anti-pattern. We do not suggest that you implement this approach.
The third approach is to externalize a communication mechanism to the sidecar proxy. In this case, the microservices concentrate only on the business implementation, letting the sidecar proxy manage communication at the network level. The drawback of this approach is you need to write custom configurations to manage communication across services by using sidecars.
The fourth approach is an extension of the third approach. A service mesh and event mesh can be usedto communicate across services by using a sidecar proxy.
The fifth approach uses orchestration logic or software to simplify communication between microservices. Tools like Netflix Conductor, Uber, Zeebe, etc., provide an implementation of the orchestration mechanism. The drawback of these implementations is the single point of failure, and orchestration becomes too complex as microservices grow in an organization. This type of implementation is good for use cases like long-running services that could be better suited for choreography.
Sidecar
The sidecar pattern segregates the technical configuration from the functional implementation of a microservice and deploys it in a container alongside the functional microservices container.
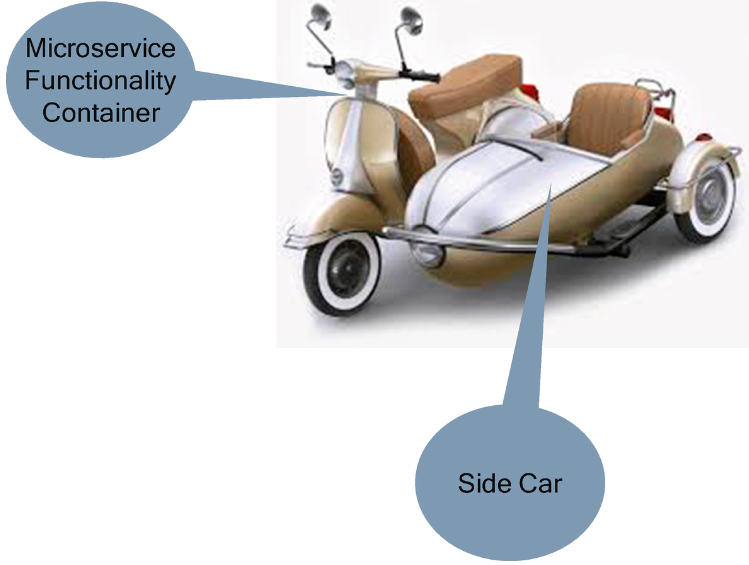
This pattern allows you to add several configuration details from the third party without modifying the microservice. It is a single-node pattern made up of two containers. One container for the application container contains the core business logic, and another container is for the technical configuration details.
The objective of the sidecar container is to supplement and improve the application container without the knowledge of the application container. The sidecar container is co-scheduled onto the same machine through the container group, and it goes wherever the main container goes.
What Is a Service Mesh?
Service meshes provide intent-based networking for microservices and describe the desired behavior of the network topology. The service mesh pattern is used for microservices deployments and uses a sidecar proxy to enable secure, fast, and reliable service-to-service communications.
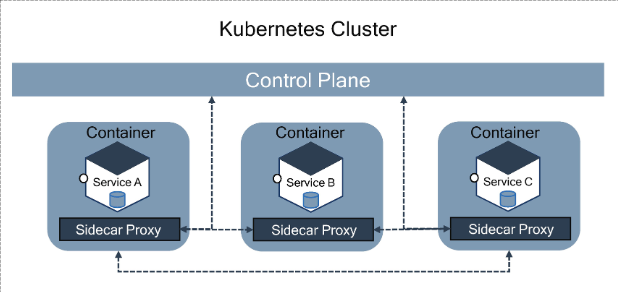
You can configure communication policies such as a circuit breaker, load balancing, service discovery, and security at the control plane level and abstract the governance considerations behind microservices from the service code.
What Is an Event Mesh?
An event mesh handles the asynchronous event-driven routing of information between microservices. It intelligently routes events between the event brokers allowing the cluster or brokers to appear as a single virtual event broker.
How to Build Resilient Microservices?
Circuit Breaker Pattern
The idea of the circuit breaker is to wrap a protected function call in a circuit breaker object, which monitors failure. Once the failure reaches a certain threshold, the circuit breaker trips, and all calls to it return with an error. Thismeans the circuit breaker acts as a proxy for operations that could potentially fail.
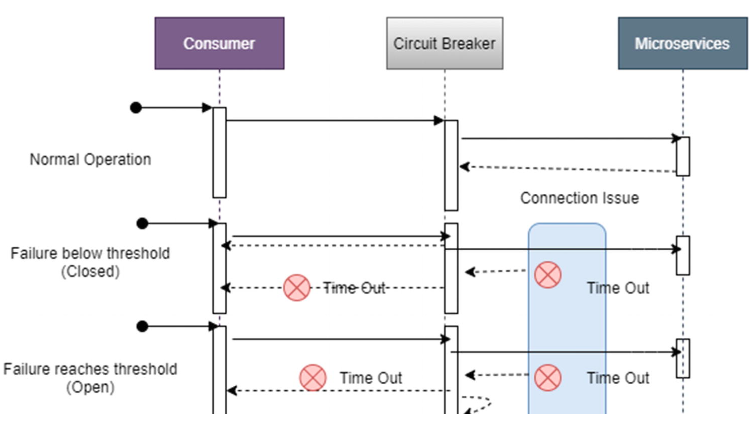
Closed: The operation executes normally. The circuit breaker maintains a count of the recent failures. The proxy is placed into the open state if the number of recent failures exceeds a threshold within a given period. At this point, the proxy starts a timeout timer, and when this timer expires, the proxy is placed into the half-open state.
Open: The request from the application fails immediately, and an exception is returned to the application.
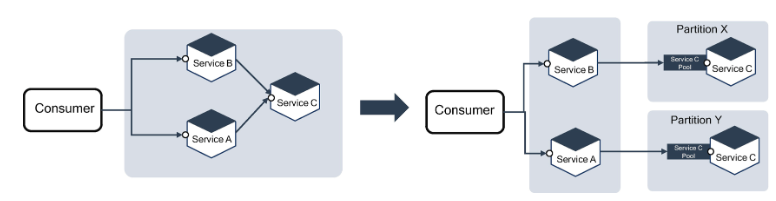
Bulkhead Pattern
The bulkhead pattern gets its name from the cargo ship design. A ship’sbulkhead is a dividing wall or barrier between other compartments. This means that if a portion of a ship hits a rock or iceberg, that portion fills with water, and the rest of the portion is unaffected. This prevents damage caused to the entire cargo ship and avoids sinking. If there are no partitions in the ship, the entire ship will sink. The bulkhead enforces a principle of damage containment.
For example, service A and service B use service C because both services depend on common functionality that resides in service C. Suddenly, service A becomes overloaded by multiple requests from the consumer; this will impact Service C as Service A needs dependent functionality from Service C. In this case, service A is bombarded with requests to service C. In the meantime, the user sends a request to service B, so service B needs to call service C to fulfill a request to their consumers. However, service B is unable to get a response, or the response is very slow from service C, which will impact their consumer. This is all caused by both service A and B depending on service C and service C being unable to pool equally for both the services.
To minimize this impact on service B, you need to adopt a bulkhead approach to partition service C into an equal pool of requests to serve its consumers. You don’t need a separate database for service C; both instances of service C in each partition can share a database.
Stateless Services
Use stateless services for designing resilient microservices. Stateless services depend on inputs and don’t hold data; any copy of this service serves a similar activity as the original services. These services spin-off instantly depending on the condition of services such as CPU, load, etc. The load balancer can distribute load across microservice instances to improve resiliency and availability, and it can route based on the availability of instances.
Retry
Use the Retry option in your services; sometimes failures are short-lived for a few milliseconds, so retrying a few times may help in getting a response from the services
Fail Fast
Slow failure responses are the worst; it is better to have no response than a slow response. Implement self-restart by using the monitoring data. Use the container restart principle to autorestart your services.
Timeout
Use this pattern to design resilient microservices. When a consumer requests your services, there could be many reasons that your services might not respond or slow response. If there are too many requests during this period of slowness, this can cause a cascading impact, bringing the entire system down. Configuring connections and read timeouts at the client helps to release resources to the pool in case the microservices or database is taking more time than usual.
Throttling
Use this pattern for resilient microservices. The throttling or rate-limiting technique limits the number of incoming requests to be processed within a given time window. This approach helps to control the throughput meeting the SLAs and conserves the resource utilization by accepting only as many requests as it can handle.
Containerization
A container is a standard unit of software that packages up code and all its dependencies so the application runs quickly and reliably from one computing environment to another. It is a lightweight, stand-alone, executable package of software that includes everything needed to run microservices. Containers are built once and can be run on any infrastructure, meaning on-premises or with any cloud provider.
Design for Failure
Whatever system you use and however you design a system, you cannot avoid failure. Systems are bound to fail due to various reasons like network failure, server failure, catastrophic failure, natural disaster, a sudden spike in load, etc. An application needs to be designed so that it can tolerate the failure of services. If microservices fail, then you need to respond gracefully to the consumer.
Since microservices fail at any point in time, you need to design microservices to be able to detect the failure quickly and self-heal the failure. Microservices put a lot of emphasis on integrated real-time monitoring of application, infrastructure, and security and semantic monitoring. They need an early warning system so that you can use predictive analysis to heal the microservices.
Event-Driven Architecture
High-speed, asynchronous, machine-to-machine, or program-to-program communication is made possible by event-driven technology, which also ensures consistent, dependable event delivery. Programs or machines can exchange data with one another. The routes that link the sender and the recipient are known as queues or channels. A machine or program that writes data to queues to communicate events is called a sender or producer. A receiver or consumer receives the messages and responds with an acknowledgment to verify that the message was received. Between the sender and the recipient, data can be exchanged as an object, JSON, XML, or byte. There exist two methods for exchanging information: publish and subscribe and point to point. The primary features of message queues are storage, asynchronous messaging, and routing. The message queues store messages or some type of buffer until they have been either read by a consumer or expire or explicitly removed from the queues. The main advantage of a messaging system is loose coupling. The receiving application may not be available for a few seconds to receive messages, or the network is not available, but the receiving application can receive messages once it is available. The message broker keeps retrying to send messages to the receiving applications. This allows for asynchronous nonblocking communication that provides a higher tolerance level against failure. Enterprise messaging technologies such as IBM MQ, Active MQ, Rabbit MQ, Zero MQ, etc., can be used to decouple your applications for the reliable and guaranteed delivery of messages.
Serverless Architecture
Serverless computing is a method of providing back-end services on an as-used basis, and it allows you to write and deploy programs without worrying about infrastructure management.
No server management: There is no operating system to install or patch.
Flexible scaling: Scale is managed for you or is done in a way that’s defined in terms of the actual capacity of the application as opposed to having to consider things such as CPUs and memory and other kinds of server-based concepts.
Automated high availability: All the serverless components of the overall platform have built-in high availability. You don’t need to design for HA. Serverless gets HA out of the box.
Evolution of Serverless
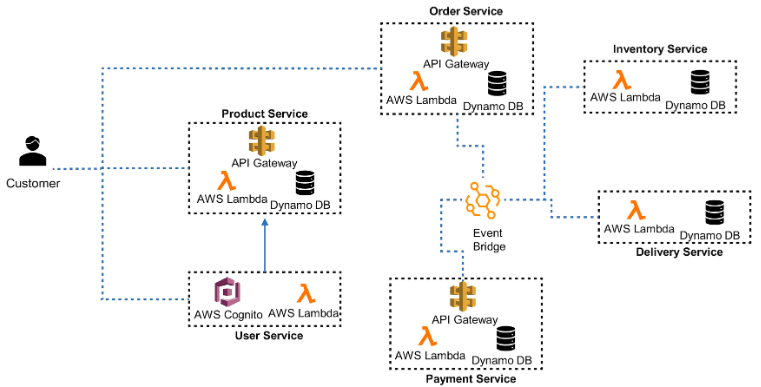
API gateway: For service-to-service synchronous communication and access from mobile and web applications, you can use any API gateways like Layer 7, Apigee, etc.
Event bridge: For service-to-service asynchronous communication, you can use any event broker like Kafka, etc.
AWS Cognito: For managing and authenticating users, this provides the JSON web tokens used by web services.
AWS Lambda: The service implementation communicates with APIs and events.
AWS DynamoDB: For storage service, you can use any service like MongoDB, Couchbase, Cassandra, etc.
To summarize, serverless computing still has the virtualized, containerized services underneath it, but people don’t interact with those servers anymore. All those infrastructure tasks, such as provisioning, scaling, and cleaning up, are done by machines in a completely automated lifecycle.
Serverless approaches are designed to handle idle servers that affect enterprises’ balance sheets without offering value; they also remove the cost of building and operating a fleet of servers.
Various cloud vendors offer serverless solutions for long-standing problems by eliminating the servers, containers, disks, and other infrastructure. Serverless is the easiest and fastest way to architecture a reactive, event-based system with a cloud native architecture.
Cloud Native Data Architecture
Objects, Files, and Blocks
Objects, files, and blocks are storage formats that hold, organize, and present data in different ways. Object storage manages data as an object and stores data with metadata and a key that is used as a reference for the object. File storage organizes and represents data as a hierarchy of files in folders. Block storage chunks data into arbitrarily organized, evenly sized volumes.
The major cloud providers such as AWS, Azure, and Google provide inexpensive object storage, and the data can be accessed through APIs. Each object is stored in a key-value pair with metadata linked into it, and it is stored with versions and globally available. The object storage tools are AWS’s S3, Azure’s blob storage, and Google Cloud storage.
Every document in a file is arranged in some type of local hierarchy. Network-attached storage (NAS) is a file-level storage architecture. Use it when using a library or service that requires shared access to files. Various NAS providers are available in cloud environments including natively from cloud vendors. A few major NAS vendors are NetApp, Dell EMC, HPE, Hitachi Vantara, IBM, Cloudian, Qumulo, and WekaIO.
Block storage breaks data into smaller blocks and stores the blocks separately. Each block of data is given a unique identifier, which allows a storage system to place the smaller pieces of data wherever is most convenient. Use block storage for applications for persistent local storage. For this kind of data, use any database to store it.
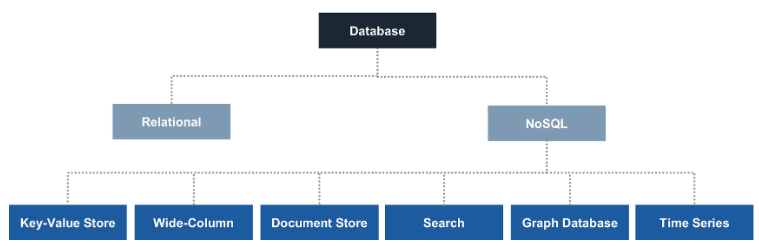
Relational Database
A relational database is a collection of data items with a predetermined relationship between them. This data is organized into a set of tables, columns, and rows. A relational database provides access to data points that are related to one another. Each column in a table holds a certain kind of data and fields to store the actual values of an attribute. Each row in a table can be marked with a unique identifier called the primary key, and the rows in multiple tables can be made related using foreign keys. This data can be managed with CRUD (Create, Read, Update, delete) operations.
The relational databases support atomicity, consistency, isolation, and durability (ACID) properties with strong consistency.
Key-Value
A key-value data store is a type of nonrelational database that uses a simple key value to store data. In key-value pairs, a key serves as a unique identifier. Both keys and values can be anything, ranging from simple objects to complex compound objects, and they can store dictionary/map/array objects.
Key-value databases use compact, efficient index structures to be able to locate a value quickly and reliably by its key, making them ideal for systems that need to find and retrieve data in real time. Key-value databases allow programs to retrieve data via keys, which are essential names, or identifiers, that point to some stored values.
The following are key-value stores: AWS Dynamo DB, Redis, Riak, Couchbase, Berkeley DB, Cassandra, etc.
Document Database
A document-oriented database is a way to store data in JSON format rather than simple rows and columns. A document store does assume a certain document structure that can be specified with a schema. A document store is the most natural way of storing data among NoSQL-type databases, which are designed to store the document as is.
The following are a few major players in the area of document databases: MongoDB, CouchDB, Couchbase Server, Cosmos DB, Document DB, MarkLogic, Oracle NoSQL, etc.
Wide-Column Database
A column database organizes data into rows and columns and can initially appear very similar to a relational database. It stores data in tables, rows, and dynamic columns. A columnar database stores each column in a separate file. One file stores only the key column, and the other stores the remaining fields. Wide-column stores provide a lot of flexibility over relational databases because each row is not required to have the same columns.
The major databases are Cassandra and HBase.
Time-Series Database
Time-series data is a sequence of data points collected over time intervals, giving you the ability to track changes over time. Time-series data can track changes over milliseconds, days, or even years. This could be server metrics, application performance monitoring, network data, sensor data, trades in the market, etc.
The major databases are Apache Druid, Riak-TS, and AWS Dynamo DB.
Graph Database
A graph database is a special kind of database storing complex data structures and most notably used for social networks, interconnected data, fraud detection, knowledge graphs, etc.
It stores data in nodes and edges. Nodes typically store information about people, places, and things, while edges store information about the relationship between the nodes. You can think of a node as an entity, and edges define the relationship between the nodes. An edge will often define the direction of the nature of a relationship.
The graph database shards data across many servers or clusters and locations. It distributes and parallelizes queries and aggregations over multiple databases.
The major graph databases are Neo4J, Orient DB, Arango DB, AWS Neptune, DataStax, IBM Graph, and Apache Graph.
Event Store Database
In event-driven architecture , streams and queues are required to store events and messages. In an event stream, the data is stored as an immutable stream of events. All the events in the event store are new records and do not allow updates; also, you cannot remove or delete an event.
The data in an event store is used to validate an aggregate sequence numbers of events, event snapshots, event sourcing details, etc.
There is various event store data store available such as IBM DB2 Event Store, Event Store DB, and NeventStore.
Search Engine Database
The search engine database is a type of nonrelational database that is used to search for information held in other databases and services. Search engine databases use indexes to categorize similar characteristics among data and facilitate search capability. A search engine index database can index large volumes of data with near-real-time access to the index.
The search engine databases are optimized for dealing with data that may be long, semistructured, or unstructured, and they provide specialized methods for search such as full-text search, complex search expression, and ranking of search results.
The search engine databases can handle full-text search faster than relational databases with indexes.
The major databases are Elasticsearch, Splunk, ArangoDB, Solr, AWS Cloud Search, Alibaba Cloud Log Service, and MarkLogic.





