
The Bible under the NLP eye (Part 1)
The first part of a fun data science project, to learn more about text processing, NLP techniques, and extracting meaningful information from text corpus.

Since Easter is approaching I thought of a nice and fun data science project, applying NLP techniques to the Bible. The Bible can be freely downloaded in text format from the Gutenberg project https://www.gutenberg.org/cache/epub/1581/pg1581.txt (Gutenberg License)
The Douay-Rheims Bible is the translation from the Latin Vulgate to English, and counts a total of 74 books. The first part of the Bible is the Old Testament, made of 46 books, which tells the history of the Israelites (Pentateuch), the division between bad and good (Wisdom books), and the books of prophets. The second part is the New Testament, 28 books, that tell the history of Christ and his disciples and the future of Earth till the Apocalypse. The main books in this part are the 4 gospels by Mark, Matthew, Luke, and John and the Apocalypse (or Revelation).
This project wants to be a gentle introduction to the NLP world, taking the reader through each step, from cleaning raw input data to getting and understanding books’ salient features. In this first part we’ll tackle: data cleaning, data extraction from corpus, and Zipf’s law.
Before starting
These are all the packages that will be using through the two articles:
import re
import nltk
nltk.download('stopwords')
from nltk.corpus import stopwords
import glob
import string
import gensim
from gensim.corpora import Dictionary
from gensim.utils import simple_preprocess
from gensim.models import CoherenceModel, Phrases, LdaModel
from gensim.models.ldamulticore import LdaMulticore
import pandas as pd
from num2words import num2words
import numpy as np
from wordcloud import WordCloud
from sklearn.feature_extraction.text import CountVectorizer
import seaborn as sbn
from matplotlib.pyplot as plt
from scipy.stats import hmean
from scipy.stats import normSo you can install ahead and import just once.
Preprocessing
Preprocessing is the very first thing — we should always keep in our mind! Here the raw input file is cleaned and books are subdivided into single files. I performed a simple manual cleaning, taking out the introduction, the title and the introduction for each book, and the final Gutenberg’s end disclaimers. After this step, each book starts with the pattern Book_name Chapter 1 along with verses numbers and text.
Fig.1 shows how I subdivided all the books into single files. The input file is read as a single string with .readlines(). Old Testament’s books are in old_books and multinames list denotes all those books that have multiple versions (e.g. The First Book of Kings, The First Book of Paralipomenon etc).
For every line that starts with Chapter we extract the book_name . For multinames books we have the pattern 1 Book_Name Chapter 1 at the beginning of each chapter, so we extract the next following word from the lineval.split()[1] . The first occurrence for Book_Name Chapter 1marks the starting index of the book. When current_book_name is different from the stored tmp_book name the ending index is retrieved. Thus, the dictionary books_idx contains the book name, the starting index and ending index (e.g. {"Genesis":[0, 5689], "Exodus":[5689, 10258], ... } ). From the indexes we can then select all the books from the original lines and save them to a txt file
If not stated differently, input text have been cleaned in this way and stored as a string in a data list:
For each book the verses’ numerical pattern NUMBER:NUMBER. text was removed with re and the regex r"\d{1,}\:\d{1,}\. which matches a combination of numbers \d{1,} the semicolumn \: and the final dot \. . Similarly, the pattern Book_name Chapter NUMBER was removed. Finally, all the texts were converted to lowercase, punctuation was removed as well as stopwords.
Get an initial idea: wordcloud
wordcloud is the perfect starting point to have an initial idea of the themes and recurrent words in the Bible’s books. Wordcloud displays in a human-intelligible way the most frequent words occurring in a text. All the Bible’s books can be compressed in a single big_string and a word cloud is generated as WordCloud(width=IMAGE_WIDTH, height=IMAGE_HEIGHT, max_font_size=FONT_SIZE).generate(big_string) :
Fig.4 shows all the books’ WordClouds. Topics can be immediately spotted, as well as keywords such as lord , god , come , son , isreal , king
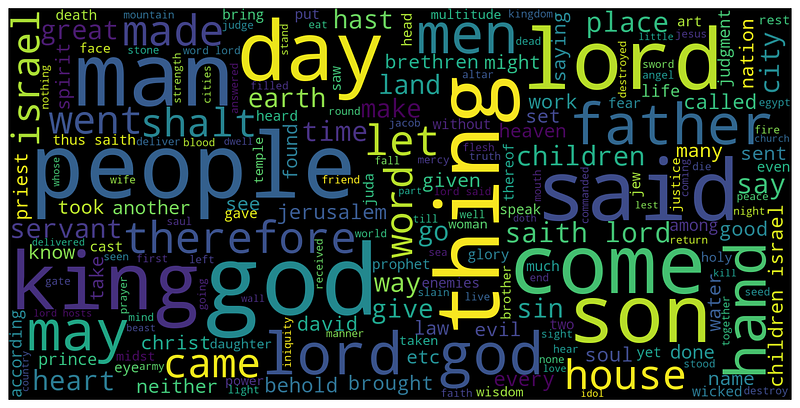
We can do more and extract a wordcloud for each single book. Fig.5 shows a comparison of wordclouds among the first three Old Testament’s books, Genesis, Exodus and Leviticus. We can clearly recognize the principal elements and differences. The Genesis starts with the theme of earth and god which said to Abraham not to eat the from the Tree. From there we can define other descendant from Abrahm, like Joseph , Isaac , Brethren . In the Exodus the main character is Moses as well as Egypt pharao . Finally, in the Leviticus the main theme is the holocaust , so we’ll have words such as sacrifice , blood , victim , flesh and offer

I’ll leave for you to analyse and see the difference in the Gospels’ word clouds and also appreciate the difference in tones between the Gospels, the Genesis and the Apocalypse book (this is the last Bible’s book, that may have been written 100 years after Christ).
Numerical Symbolism
Since the Bible comes from oral tradition there are a lot of recurrent patterns. Moreover, there is a lot of symbolism. Every word has its meaning in a specific context. The same applies to numbers. Numbers are used to express a concept — for example “seven times more” or “seventy-seven times” are often used to say “a lot” — and make up a unique and interesting feature to be uncovered. Additionally, finding numbers in the text is a great way to learn regular expressions and a wee trick to get numbers.
The task is to find plain English numbers in a text. The first naive approach is to convert integers to strings, split the text into spaces to have a split list, and count the literal number of occurrences for each split list. Fig.6 summarizes this approach. Firstly, we transform numbers into strings with num2words and store them in a list. After data have been cleaned (as above) we can count each number occurrence for each book. On a Google Colab notebook, this process takes about 12 seconds for 100k numbers. So far so good, however, we can immediately see that the final dictionary is full of 0 occurrences for most of the numbers. Moreover, the majority of found numbers are between 0 and 20. This is due to how we split the strings and also how some numbers are converted to strings (e.g. we might have twenty-one in the number list but it should be twenty-one as in the text)
We can refine this approach using Python module re and building up a regular expression. I don’t want to teach you how to create a regex, there are tons of sources and it’s often useless to learn by heart how to create a regex. I’ll like to focus our attention on how to tackle this process.
The idea is to create a regular expression that could match all the numbers that we have in a given book. The core part of the regex could be something like \b(numb1|numb2|numb3)\b . Fig.7 shows a test on a string that contains the following numbers one, twenty thousand, three thousand thirty four, three thousand five hundred forty five. Thus we can build up a regex which contains numbers and run it agains the test string as re.findall(regex, test_text) . Super simple, but the result is remarkably wrong, as the found numbers are one, twenty, three, thirty four, three, five, forty five . As you can see how regex just stopped as soon as a match was found. That’s not what we want. We can do something sneakier and reverse the order of our regex, having “rare” numbers at the beginning and small “frequent” numbers at the end. As you can see now the result is correct, returning the numbers that we want.
With this scheme we can look for numbers now in the bible, adding a bit of preprocessing to the numbers converted from num2words , as shown in fig.8. the regex is created in 2 seconds, while it takes 1min 30s to run the matching bit. In this case, the final dictionary match_dict will contain more important and useful information than our previous approach, as the correct numbers will be recorded for each book, avoiding tons of 0s values. However, it is painful to create a regex like this one and not so efficient when we have to run the matching process. Here rexegg https://www.rexegg.com/regex-trick-numbers-in-english.html comes to help
Fig.9 shows that we can create a regex to match plain English numbers, by simply using literal number constructions, e.g. f(?:ive|our) and defining numbers from 0 to trillion of a trillion, without storing anything in memory or additional processes. The regex creation process takes about 300 microseconds, while the matching about 4 seconds!
As you can see the last approach is the winning one. It is more portable, it doesn’t require additional processing of numbers and it is more computationally efficient than our first approach, returning full correct information.
If we analyse the final matching dictionary, we can see that Numbers is — unsurprisingly — the book with the most numbers, 632. The second book is the Genesis , 508, while the Apocalypse has 323 numbers, more than any other book in the new testament, with seven is repeated 76 times and one for 72 times. The highest number in the bible is 800'000, which appears in the Second book of Samuel, 24:9 (Old Testament):
And Joab gave up the sum of the number of the people to the king, and there were found of Israel eight hundred thousand valiant men that drew the sword: and of Juda five hundred thousand fighting men.
From the output dictionary we can compare all the results through a pandas.DataFrame and display them in a histogram (fig.10):
We can compare the main Bible’s books, namely Genesis , Exodus , the first and second book of Samuel ( 1Kings , 2Kings ) , Psalms , Isaias , the gospels:Mark , Matthew , Luke , John and the final book, the Apocalypse
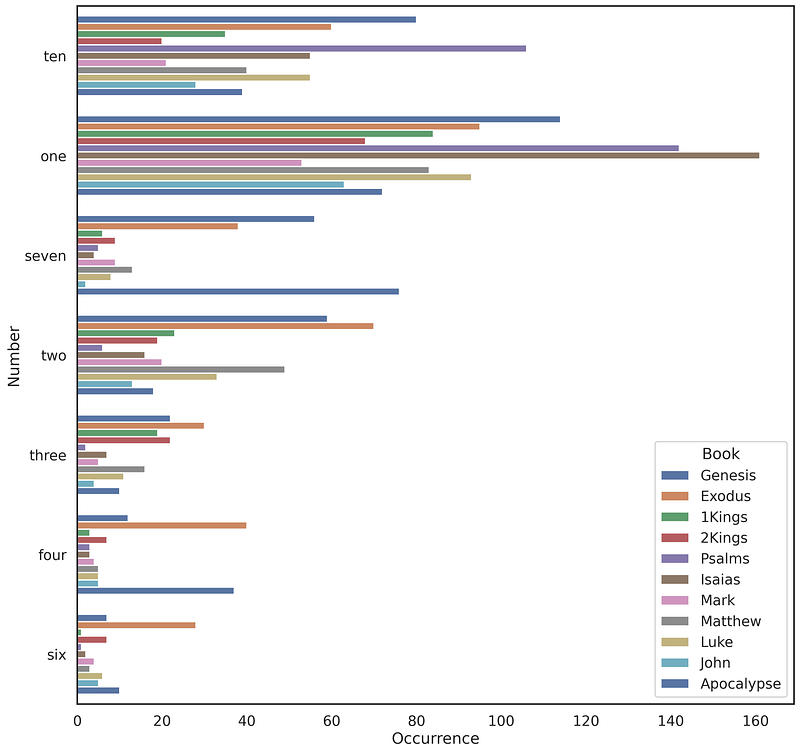
10, 1, 7, 2, 3, 4 and 6 are the numbers commonly used within the main Bible’s books. In particular, it is interesting to note the use of sevenin the Genesis (the first book) and Apocalpyse (the last book)
Zipf’s law
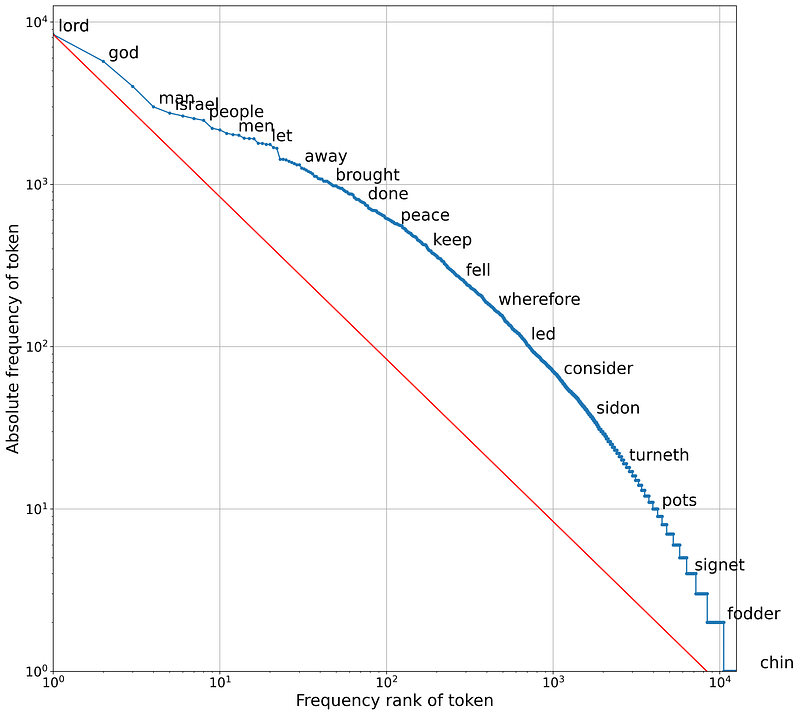
Zipf’s Law, named after American linguist George Kingsley Zipf, relates the frequency of words with their ranks. In particular, in a text corpus, the frequency of any word is inversely proportional to its frequency rank. More or less the most frequent word will occur twice as often as the second most frequent word, three times as often as the third most frequent word, and so on. Translating this law to a log-log domain, the result is a linear plot as a function of the word rank and word frequency. From here let’s see how the Bible corpus appears with respect to Zipf’s law.
Fig.12 shows how to compute the word frequencies and rank from each bible’s book. Firstly, we initiate sklearn.feature_extraction.text.CountVectorizer() to count all the words occurrences for each book. The final matrix count, all_df , can be converted into a pandas.DataFrame , summing up all the word occurrences, tf = np.sum(all_df, axis=0) and retrieving the word from cvev.get_feature_names() . The final dataframe, term_freq_df , will have the words as index and a column, which is the total count of the word in the corpus. From there it is possible to compare the distribution of the words with respect to Zipf’s law on a logarithmic scale.
Fig.13 shows the final plot result. The Bible slightly departs from the Zipf’s linearity. This is not a big surprise. Indeed, in the Bible there are many repeated words which are scarcely used in natural language. It is interesting also to note that the word chin is used only once, in the Second Book of Samuel, 20:9:
And Joab said to Amasa: God save thee, my brother. And he took Amasa by the chin with his right hand to kiss him.
From here we can go deeper into the word usage in the Bible, in order to see differences across the main books. Firstly, the main recurrent words in the whole Bible are:
lordappears 8377 timesgodappears 5720 timesmanappears 2999 times
Interestingly, David is used more times than christ or Jesus , 1162, 992 and 1028 respectively, while the word children is used 1915 times.
Moving on, we can check the differences in words between new and Old Testament. Table 1 shows the percentage of word occurrences in the Old Testament ( Old T% ) and New Testament ( New T% ). We can see how lord , Israel , king , people are mainly used in the Old Testament and their translation/transformation to god , Jesus , christ , father and man in the New one.
We can explore this difference in terms, by working on the words’ occurrences. Fig.14 shows how to relate old/new testaments’ word occurrences to the harmonic mean of the normal cumulative distribution function of the total rate and old/new classes rates. What does it mean? We can immediately find unique words which are mainly characterizing the old testament books and the new ones:
- firstly we compute a word rate, namely the word occurrence,
term_freq_df[0for the total number of occurrencesterm_freq_df['total']→old_rate - similarly we compute a word rate for the specific class, namely subdividing the word’s occurrence with
term_freq_df[0].sum()→old_freq_pct - we compute the class harmonic mean between the
old_rateandold_freq_pct - from here we compute the normal cumulative distribution function for
old_rateandold_freq_pct→old_rate_normcdfandold_freq_pct_normcdf - finally, we compute the harmonic mean between
old_rate_normcdfandold_freq_pct_normcdfto give more weight to unique and specific words for a given class
This approach mainly comes from the amazing articles of RickyKim
If you plot old_normcdf_hmean and new_normcdf_hmean you’ll have fig.15, which highlights in the top left corner all the words which are unique and mainly used in the Old Testament and in the bottom right corner words specifically employed in the New Testament.
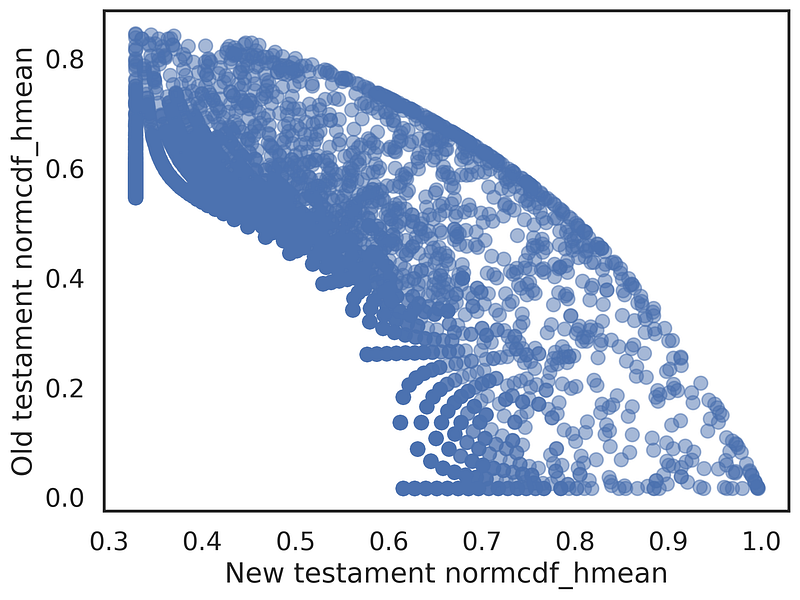
From here we can immediately see the contrast of tones between the Old and New Testament, tab.2. In the former Testament are more prevalent “war” terms such as valiant and convenient , where stories are characterized by a “rural” society. The New Testament emphasises the new believe, highlighting the concept of angels , charity and faith
As a very last thing, the above analysis can be run for all the 4 gospels, highlighting characterising words for each of them. The gospels have been written in different times, the oldest one is Mark, followed by Matt, Luke and John. It follows there will be a different writing style, as well as more specific words used in each of them. John appears to be the most “Catholic” gospel, with terms referring to nowadays church: flesh , glorify , paraclete , truth . We’ll get back to this track in the next article :)
For today it’s everything :)
Conclusion on Part 1
Let’s recap what we’ve done today:
- we learned how to preprocess a raw text input, get it ready for NLP analyses and save it into different files
- to get an initial understanding of our data we run
WordCloudFrom here we were able to identify different topics and themes among Bible books - we saw how to tackle a regular expression problem, find a series of numbers in plain English and how to optimize the final solution
- finally, we tested Zipf’s law against the Bible’s corpus and extended this analysis to define characteristic and unique words for each of the four Gospels
Next time we’ll run topic modelling, word embeddings and text embeddings, and text similarity. Stay tuned :)
Support my writing and projects by joining Medium through my referral link:
Please, feel free to send me an email for questions or comments at: [email protected] or directly here in Medium.