
The Art of Prompting GPT-4: Python CSV Cleaning and Data Visual Code
Simple creation of Python scripts for interactive choropleth maps

With simple modular prompting, GPT-4 is an awesome tool for generating Python code to clean and to visualize your data.
In combination with the right libraries, Pandas and Plotly, you can create interactive charts, and maps.
Let’s work through 3 steps together on how to do this:
- cleaning a dataset
- creating a choropleth map
- creating an animated choropleth map that illustrates data over time
Let’s get to it!
Step 1: Cleaning a CSV Data Set
For this exercise, we will be using a newly updated dataset from the UN Department of Economic and Social Affairs website (HERE).
The file we want to download is the one highlighted below:
This UN dataset models projected population growth for the years 2022 to 2100.
After a quick first look, we can see that some data cleaning is in order. The actual data headers start on Row 17. So we can remove the first 16 rows of data (or just start our data retrieval in this row).
Now if we want to do a choropleth map to show each country over time (by heat map), then we really only want the rows that actually have a value for the 3-letter ISO field. We can see by the observation that if we only use the rows that have a value in this column, I will essentially cover every country on the planet.
Terrific. That’s what we are looking for!
So let’s upload our CSV file (called pp_median.csv) and engineer a prompt to ChatGPT to create a new CSV file based on these criteria:
Prompt to GPT-4: Here is the CSV file (called pp_median.csv). I would like you to write the Python code to parse this CSV file and extract ONLY the rows where the field “ISO3 Alpha-code” has a value. Please then store ALL these rows in a new CSV file called pp_median_country.csv.
Response from GPT-4:
import pandas as pd
# Load the CSV file
df = pd.read_csv('pp_median.csv')
# Filter the DataFrame to only include rows where 'ISO3 Alpha-code' has a value
filtered_df = df[df['ISO3 Alpha-code'].notna()]
# Write the filtered DataFrame to a new CSV file
filtered_df.to_csv('pp_median_country.csv', index=False)This code first uses the pandas library to load a CSV file into a pandas data frame. The pd.read_csv function is used to read the CSV file.
The data frame (df) is then filtered to only include rows where the ‘ISO3 Alpha-code’ field has a value. This is done using the df['ISO3 Alpha-code'].notna() condition, which returns a boolean Series where True represents rows where 'ISO3 Alpha-code' is not null.
Finally, the filtered data frame (df) is written to a new CSV file using the to_csv function. The index=False argument is used to prevent pandas from writing row indices into the CSV file.
The first few rows of our new CSV now look like so:
Great! Now onto the data visualizations.
Step 2: Creating a Choropleth Map for a Single-Year
To start with, for simplicity's sake, let’s just create a choropleth map for a single year.
- ISO3 Alpha-code: The ISO 3166-1 alpha-3 code for the country. This is a three-letter code that represents each country uniquely. This field is used to create the choropleth map.
- Year: the year to which the data pertains.
- Age group columns (
0-14,0-19,0-24,15-24,15-49,15-59,15-64,20-64,20-69,25-64,25-69,60,65,70,80): These columns represent different age groups and contain the percentage of the population that falls into each age group for the given year and location.
Now that we know the fields in our our data set, let’s go ahead and prompt engineer GPT-4 to generate the code for a choropleth map that for each country shows the percentage of the population 65 years and older for the projected year 2024.
Prompt to GPT-4: Using the new CSV file, please write the Python code to create a Plotly choropleth map that displays this data for the Year 2024 and for the Age group “65”
Response from GPT-4:
import pandas as pd
import plotly.express as px
# Load the filtered CSV file
df = pd.read_csv('pp_median_country.csv')
# Filter the DataFrame to only include rows for the year 2024
df_2024 = df[df['Year'] == 2024]
# Create the choropleth map
fig = px.choropleth(df_2024, locations='ISO3 Alpha-code',
color='65', # replace this with the column you want to display
color_continuous_scale=px.colors.sequential.Plasma,
title='Population Percentage for Age Group 65+ in 2024',
labels={'65':'Percentage (%)'}) # replace this with the column you want to display
fig.show()This code first uses the pandas library to load the filtered CSV file into a DataFrame. The DataFrame is then filtered to only include rows for the year 2024 and for all people who are projected to be 65 years of age or older.
The Plotly Express function px.choropleth is used to create a choropleth map. The locations parameter is set to 'ISO3 Alpha-code', which represents the geographical locations (countries in this case). The color parameter is set to '65', which represents the values to be displayed on the map. The color_continuous_scale parameter is set to px.colors.sequential.Plasma, which defines the color scale of the map.
Finally, the fig.show() function is used to display the map.
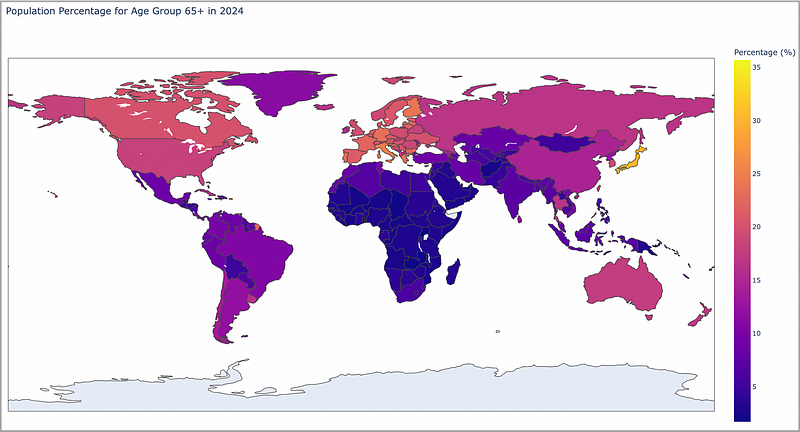
The resulting map shows the projected percentage of the population 65 years or older for the year 2024. We can see that for this example that Japan currently has a very old population relative to the rest of the world.
A more interesting analysis though would be to see how each country ages over a period of time. The CSV file we are using has projections from 2022 up to the year 2100.
So let’s see if we can create an animated map that starts at 2022 and shows us the projected values for each country up until the year 2100.
Step 3: Creating an Animated Choropleth Map for All Years
Now we can take it up a notch and ask for some more functionality — some animation across time, which tells a much deeper story about the projected trends, particularly for aging populations — which is a concern.
Prompt to ChatGPT: Using the same CSV file, use the full date range (2022–2100), and make sure the ‘Year” does NOT display a decimal value. Then, set the color range to a static value — from 0 to 50 and the color_continuous_scale to ‘rainbow’.
Response from ChatGPT:
import pandas as pd
import plotly.express as px
# Load the filtered CSV file
df = pd.read_csv('pp_median_country.csv')
# Convert 'Year' to integer to remove decimal
df['Year'] = df['Year'].astype(int)
# Create the animated choropleth map
fig = px.choropleth(df, locations='ISO3 Alpha-code',
color='65+', # replace this with the column you want to display
animation_frame='Year',
color_continuous_scale='rainbow',
range_color=(0, 50), # set the color range
title='Population Percentage for Age Group 65+',
labels={'65+':'Percentage (%)'}) # replace this with the column you want to display
fig.show()This code first loads the filtered CSV file into a DataFrame. The ‘Year’ column is then converted to an integer to remove the decimal.
The px.choropleth function is used to create an animated choropleth map. The animation_frame parameter is set to 'Year', which creates an animation over the years. The color_continuous_scale parameter is set to 'rainbow', which defines the color scale of the map. The range_color parameter is set to (0, 50), which sets the color range.
Finally, the fig.show() function is used to display the map.
And here is an animated image of our interactive map:
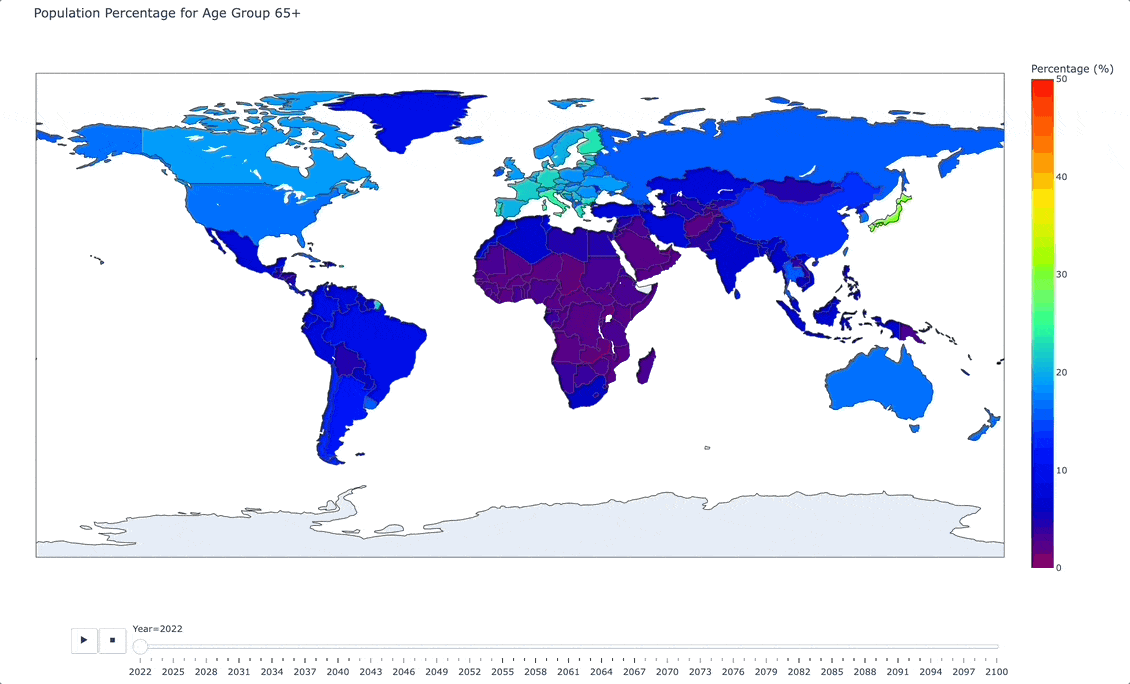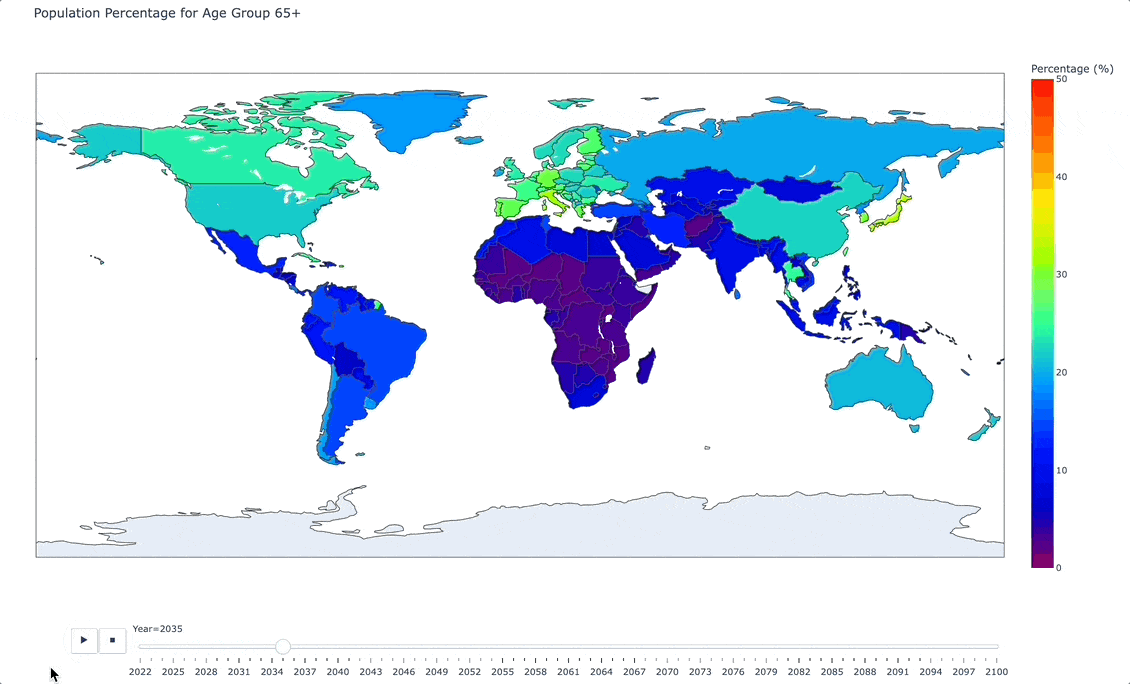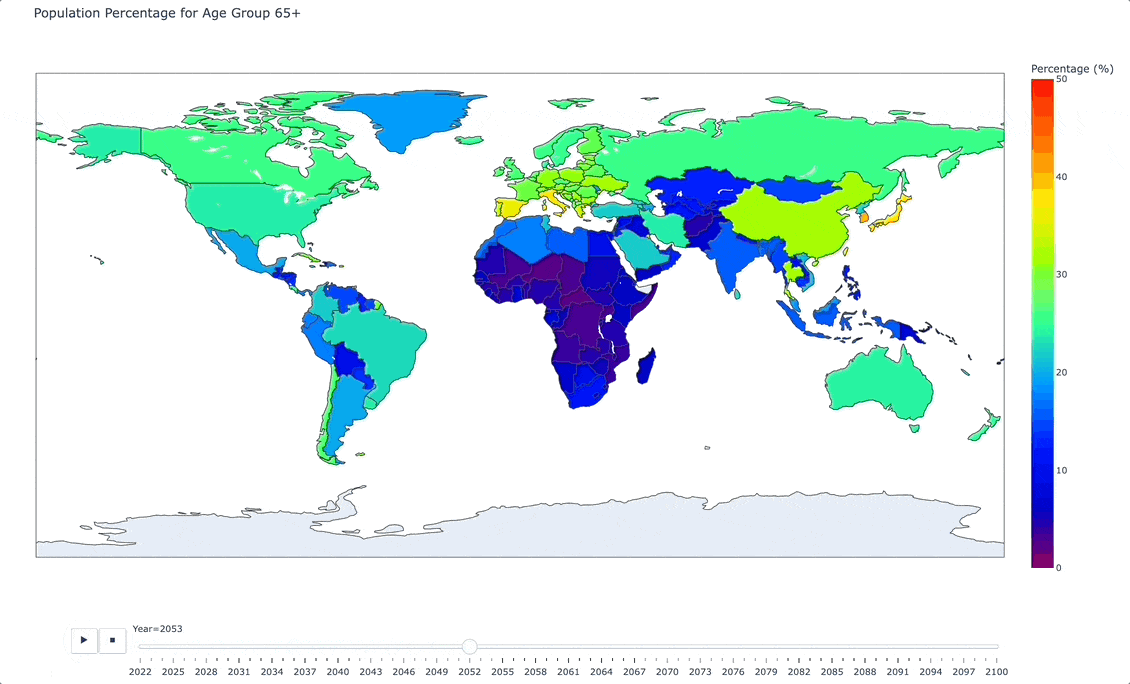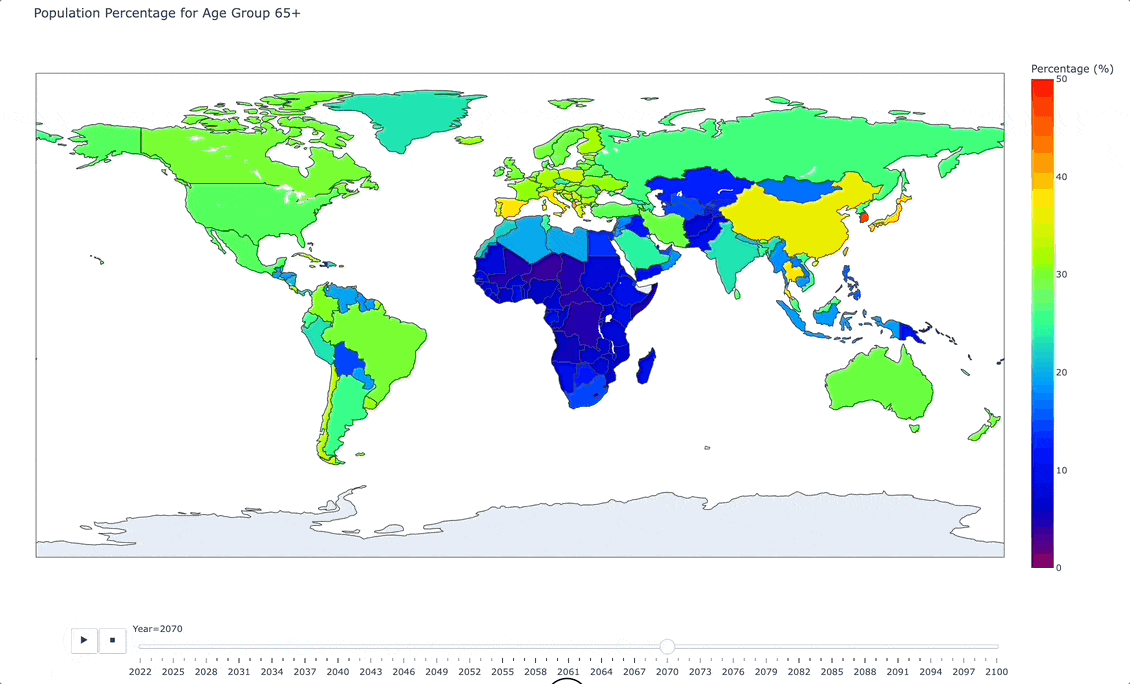
As you can see from the animated image above, as we move forward in time, there are certain areas of the world (Italy, Japan, and South Korea being vivid examples) that are projecting towards a significantly older population.
The story that this is telling is one of a heavier burden on the work force, on medical systems, and on national retirement and pension policies.
Nice work putting this all together.
Thank you for reading!
If this type of story is right up your alley, and you want to support me as a writer, subscribe to my Substack.
On Substack, I publish a newsletter, and articles that you won’t find on the other platforms where I create content.
I would love to hear/read your comments!





