
The Art of Feature Engineering: Techniques for Creating Better Machine Learning Models in Python
Unlock the True Potential of Your Data: Master Feature Engineering Techniques for Python-Powered Machine Learning Models
Feature engineering is a crucial step in the data science process. By extracting meaningful features from raw data, you can improve the performance of your machine learning models and make better predictions. In this article, we’ll explore various techniques for creating insightful features that will help your models shine.
What is Feature Engineering?
Feature engineering involves transforming raw data into useful features that can be fed into machine learning algorithms. This process typically includes cleaning, scaling, and encoding data, as well as generating new features that capture the underlying patterns and relationships in the data.
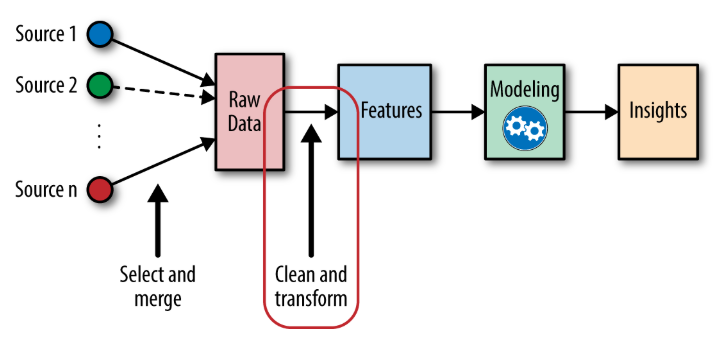
Techniques for Effective Feature Engineering
1. Domain Knowledge-Based Feature Generation
Sometimes, domain-specific knowledge can be used to create new features that are not directly present in the data. For example, in a dataset containing the age and height of individuals, you could create a new feature called ‘Body Mass Index’ (BMI) by using the formula:
BMI = weight / (height^2)This new feature may provide additional insights and improve the performance of your model.
2. Categorical Encoding
Machine learning models typically work better with numerical data. Categorical variables, such as colors or countries, can be converted into numerical representations using different encoding techniques. Here are some popular encoding methods:
- Label Encoding: Assign a unique integer to each category.
- One-Hot Encoding: Create a binary column for each category, with a 1 representing the presence of the category and 0 representing its absence.
For example, let’s encode a list of colors using one-hot encoding:
import pandas as pd
colors = ['red', 'blue', 'green']
data = pd.DataFrame(colors, columns=['color'])
# One-Hot Encoding
encoded_data = pd.get_dummies(data['color'])
print(encoded_data)3. Handling Missing Values
Missing values can negatively impact the performance of machine learning models. Some popular techniques for handling missing values include:
- Imputation: Fill missing values with a specific value or an estimate, such as the mean or median.
- Deletion: Remove instances or features with a high percentage of missing values.
Here’s an example of using mean imputation to fill missing values in a Pandas DataFrame:
import numpy as np
data = pd.DataFrame({'A': [1, 2, np.nan, 4], 'B': [5, np.nan, 7, 8]})
data.fillna(data.mean(), inplace=True)
print(data)4. Feature Scaling
Feature scaling ensures that all features have the same scale, preventing models from being biased towards features with larger scales. Two popular scaling methods are:
- Normalization: Scale features to have values between 0 and 1.
- Standardization: Scale features to have a mean of 0 and a standard deviation of 1.
Here’s an example of standardizing features using Scikit-learn’s StandardScaler:
from sklearn.preprocessing import StandardScaler
data = pd.DataFrame({'A': [1, 2, 3, 4], 'B': [100, 200, 300, 400]})
scaler = StandardScaler()
scaled_data = scaler.fit_transform(data)
print(scaled_data)5. Feature Extraction
Feature extraction involves transforming high-dimensional data into a lower-dimensional space, while retaining the most important information. Some common feature extraction techniques include:
- Principal Component Analysis (PCA): Linearly transform the data to a lower-dimensional space.
- t-Distributed Stochastic Neighbor Embedding (t-SNE): Non-linearly transform the data, preserving local relationships.
Here’s an example of using PCA to reduce the dimensionality of a dataset:
from sklearn.decomposition import PCA
data = pd.DataFrame({'A': [1, 2, 3, 4], 'B': [100, 200, 300, 400], 'C': [5, 6, 7, 8]})
pca = PCA(n_components=2)
reduced_data = pca.fit_transform(data)
print(reduced_data)Feature Selection Techniques
Once you have engineered new features, it’s essential to identify the most important ones for your model. Here are some popular feature selection techniques:
1. Filter Methods
Filter methods evaluate the relevance of features based on their relationship with the target variable. Some common filter methods include:
- Pearson’s Correlation Coefficient: Measures the linear relationship between two continuous variables.
- Mutual Information: Quantifies the dependency between two variables.
For example, you can use the SelectKBest function from Scikit-learn to select the top 2 features based on their mutual information with the target variable:
from sklearn.feature_selection import SelectKBest, mutual_info_classif
data = pd.DataFrame({'A': [1, 2, 3, 4], 'B': [100, 200, 300, 400], 'C': [5, 6, 7, 8]})
target = [0, 1, 1, 0]
selector = SelectKBest(mutual_info_classif, k=2)
selected_data = selector.fit_transform(data, target)
print(selected_data)2. Wrapper Methods
Wrapper methods involve using a machine learning model to evaluate the importance of features. Some common wrapper methods include:
- Recursive Feature Elimination (RFE): Recursively removes the least important features and trains the model on the remaining features.
- Forward Selection: Iteratively adds features to the model and evaluates its performance.
For example, you can use RFE with a logistic regression model to select the top 2 features:
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
data = pd.DataFrame({'A': [1, 2, 3, 4], 'B': [100, 200, 300, 400], 'C': [5, 6, 7, 8]})
target = [0, 1, 1, 0]
model = LogisticRegression()
rfe = RFE(model, n_features_to_select=2)
rfe.fit(data, target)
selected_features = data.columns[rfe.support_]
print(selected_features)By leveraging these feature engineering techniques, you can create more effective machine learning models in Python. Remember that finding the best features requires creativity, domain knowledge, and a good understanding of the underlying data. Happy coding!
If you enjoyed this content, please give it a like! Your support helps us to create more valuable content for you.
You can also subscribe to my new articles, or become a referred Medium member.
✨You can support me financially here, your support helps me continue creating useful content often! Thanks mate :) ☕️
More content at PlainEnglish.io.
Sign up for our free weekly newsletter. Follow us on Twitter, LinkedIn, YouTube, and Discord.
Interested in scaling your software startup? Check out Circuit.