
The Art and Science of Building and Operating Amazon S3
A Deep Dive into the World of Large-Scale Storage Systems
In a recent blog post published on All Things Distributed, Andy Warfield, VP and distinguished engineer at Amazon S3, provides a fascinating and in-depth look into the intricacies of building and operating a large-scale storage system like Amazon S3. The post is a treasure trove of insights, shedding light on the complexities, challenges, and innovative solutions of managing a system of such magnitude.
Warfield’s professional journey has been deeply rooted in computer systems software. His expertise spans operating systems, virtualization, storage, networks, and security. However, his six-year tenure with Amazon Simple Storage Service (S3) has significantly broadened his perspective on systems. He now views systems more holistically, encompassing everything from the mechanics of hard disks, firmware, and the physical properties of storage media to customer-facing performance experience and API expressiveness. His role extends beyond the technical realm, involving interactions with engineering, finance, hardware, and customers to create innovative applications.
The blog post delves into the history of S3, a service that has become an integral part of the internet’s infrastructure since its launch on March 14th, 2006. Warfield expresses his sense of wonder at the storage systems being built today, describing them as “pretty amazing.” He emphasizes the unique nuances of building a system like S3 and shares the lessons learned and surprising observations from his time working on S3.
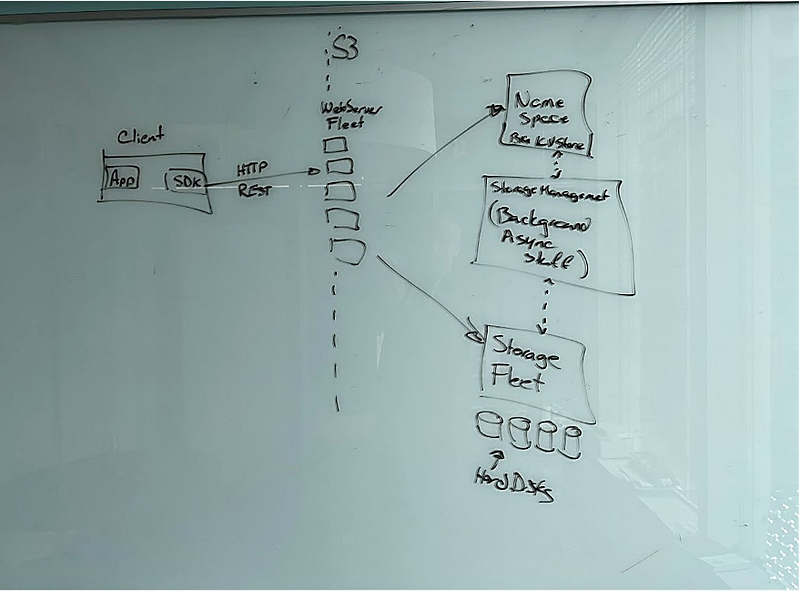
Warfield provides a detailed explanation of how S3 works, breaking down its complex structure for readers. S3 is an object storage service with an HTTP REST API, composed of hundreds of microservices. Each of these components, whether it’s a frontend fleet with a REST API, a namespace service, a storage fleet filled with hard disks, or a fleet that performs background operations, has its team and operates like an independent business. This structure allows for a high level of modularity and flexibility, enabling each component to function optimally while contributing to the system's overall efficiency.
One of the key challenges Warfield discusses in the post is the concept of “heat” in S3. In this context, “heat” refers to the number of requests that hit a given disk at any point in time. Managing this heat is a significant challenge, as it involves balancing I/O demand across a large set of hard drives. The post explains how redundancy schemes, such as replication and erasure coding, are used to manage heat and protect data from hardware failures. These schemes divide data into more pieces than needed for access, providing flexibility to avoid sending requests to overloaded disks.
The post also delves into the human factors involved in operating S3. Amazon encourages its engineers and teams to fail fast and safely, fostering an environment that promotes innovation while maintaining a high standard of service. To ensure this, Amazon uses a process called “durability reviews.” This process encourages engineers to think critically about the risks they should protect against and separate risk from countermeasures. This approach not only helps in identifying potential threats but also in formulating effective strategies to mitigate them.
In conclusion, Warfield’s post provides a comprehensive and detailed overview of the complexities and challenges of building and operating a large-scale storage system like Amazon S3. It underscores the importance of a broad perspective, critical thinking, and the ability to adapt and evolve in managing such a system. The post serves as a testament to the innovative spirit and relentless pursuit of excellence that drives the team at Amazon S3, as they continue to push the boundaries of what’s possible in large-scale storage systems.
Here you go if you are interested in reading the whole story firsthand.
Warfield also presented this at the USENIX FAST 23 conference; here is the video -





