
Texts Gone Wild: Who Wrote it — Human or AI Machine?
An Exploration of OpenAI’s Text Classifier for Text Source Identification

AI-generated content and its use will increase in coming days and with the increasing sophistication of AI-generated text, it will become more difficult for humans to distinguish between human-written and AI-generated content. The other fact that citing such work as AI-generated or Human will be more of an ethical point for people generating it. This presents a challenge for researchers, academics, publishers, content creators, and readers.
To address this challenge, AI text classifiers can be used to distinguish between human-written and AI-generated text. These classifiers use machine learning models to analyse language patterns, context, and other factors to determine the source of a given piece of text.
But why do we need AI text classifiers?
The answer is simple: transparency and accountability. By identifying AI-generated text, readers and other stakeholders can better understand how the information was created and evaluate its credibility and quality. Additionally, accurately identifying the source of the text helps to ensure that credit is given where credit is due, which is important for ethical and legal reasons.
Further, having a classifier can help prevent unintentional plagiarism or misattribution, which can help protect the intellectual property and reputations of content creators.
AI Text Classifier from OpenAI:
OpenAI released a free version of AI text classifier on 31st January 2023. It is aimed to help addressing issues such as running automated misinformation campaigns, using AI tools for academic dishonesty, and positioning an AI chatbot as a human.
The link shows an AI Text classifier where you can input the desired text to be tested and verified and below is the screen showed on the classifier.
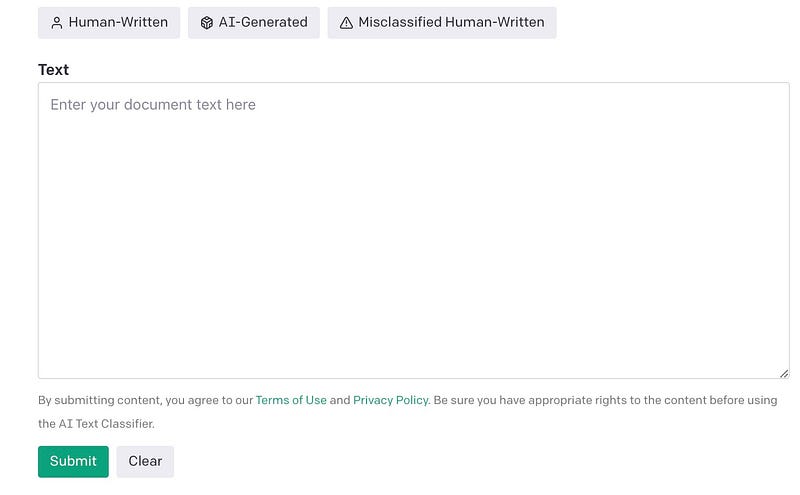
For input, the user interface is simple. It comes with three examples:
- Human written → an example from The opening of J.M. Barrie’s Peter Pan.
- AI-Generated generated → an example from essay written by the January 9th Version of ChatGPT
- Miss-classified Human written → an example from the beginning of the second chapter of Don Quixote by Miguel de Cervantes
Select the type of text you want to identify then copy paste the desired text in the text section. Make sure the text is around 1000 characters. Once you click on submit button you will get response’s like below:
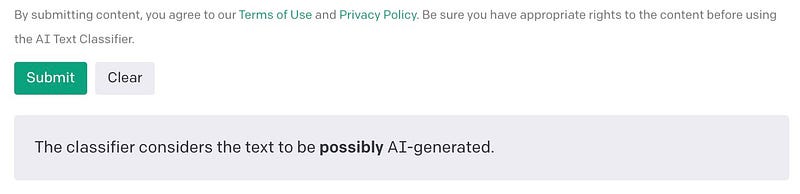

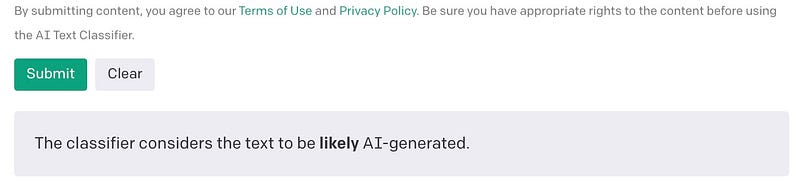
The output can be labeled in either of five types by AI Text classifier:
- very unlikely AI-generated.
- unlikely AI-generated.
- unclear if it is AI-generated.
- possibly AI-generated or
- likely AI-generated.
Text classifier below table shows the different criteria is based on which the labels are attached. For example, if the text is classified as unlikely, what does it mean? It means that the classify threshold output based on the analysis done over the text was between 0.45 and 0.9 and it has a probability of 50% that it could have been written by human and a probability of 34% if it could have been written by AI.

Limitations of AI Text Classifier:
As per OpenAI’s website, there are certain limitations of this classifier.

Sometimes, human-written text will be incorrectly but confidently labeled as AI-written by the classifier. This is especially true for classifiers based on neural networks, which are known to be poorly calibrated outside of their training data. For inputs that are very different from the text in the training set, the classifier is sometimes extremely confident in a wrong prediction. Another limitation is that the classifier is unreliable on short texts. Additionally, it can be evaded by editing AI-generated text, and it performs worse in languages other than English and unreliable on code. So we cannot say that, it can reliably identify very predictable text.
For more see Limitations section here, .
What can be done to improve ? :
There can be ways in which the classifier can be improved, such as:
- To improve the classifier’s performance on short texts, It could be trained on more diverse and shorter texts, and it could be designed to consider the context of the text to improve its accuracy.
- To reduce incorrect labels on longer texts, the classifier could be trained on a more diverse set of texts that cover a wider range of topics and styles.
- To improve the classifier’s ability to detect AI-generated text that has been edited to evade detection, the training data could be augmented with examples of edited AI-generated text.
- To improve the classifier’s performance on languages other than English, it could be trained on more diverse and larger datasets in those languages.
- To reliably identify very predictable text, additional features beyond language models could be used, such as statistical analysis of the content.
It is important to note that a single classifier may not be sufficient as a primary decision-making tool, and using multiple methods to determine the source of a piece of text may be necessary for more accurate results.
You can also try another classifier GPT-2 detector demo, based on the Transformers implementation of RoBERTa. It starts detecting better patterns after first 50 tokens on the copied text and identifies based on the likelihood of being Real or Fake.
Conclusion:
An AI text classifier is a valuable tool for identifying the source of a piece of text and ensuring transparency and accountability in the era of AI-generated content. While it has its limitations, we can continue improving its performance by training it on more diverse and larger datasets, designing it to consider the context of the text, and augmenting the training data with examples of edited AI-generated text. By using multiple methods to determine the source of a piece of text and ensuring correct citation, we can promote the ethical and effective use of AI-generated text.
If you like my article and would like to get such information directly in your inbox, do click below:
Subscribe!!!